Impala和Hive的关系(详解)
Impala和Hive的关系
Impala是基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata,意味着impala元数据都存储在Hive的metastore中。并且impala兼容Hive的sql解析,实现了Hive的SQL语义的子集,功能还在不断的完善中。
与Hive的关系
Impala 与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共同之处,如数据表元数 据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。Impala与Hive在Hadoop中的关系如下图所示。Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据分析人员提供了快速实验、验证想法的大数 据分析工具。可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。
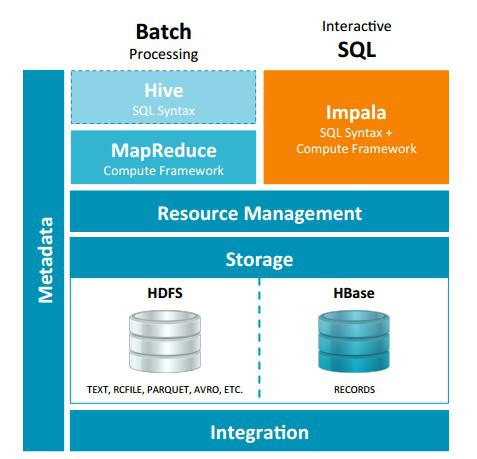
Impala相对于Hive所使用的优化技术
- 1、没有使用 MapReduce进行并行计算,虽然MapReduce是非常好的并行计算框架,但它更多的面向批处理模式,而不是面向交互式的SQL执行。与 MapReduce相比:Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发执行计划后,Impala使用拉式获取 数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少的了把中间结果写入磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免 每次执行查询都需要启动的开销,即相比Hive没了MapReduce启动时间。
- 2、使用LLVM产生运行代码,针对特定查询生成特定代码,同时使用Inline的方式减少函数调用的开销,加快执行效率。
- 3、充分利用可用的硬件指令(SSE4.2)。
- 4、更好的IO调度,Impala知道数据块所在的磁盘位置能够更好的利用多磁盘的优势,同时Impala支持直接数据块读取和本地代码计算checksum。
- 5、通过选择合适的数据存储格式可以得到最好的性能(Impala支持多种存储格式)。
- 6、最大使用内存,中间结果不写磁盘,及时通过网络以stream的方式传递。
Impala与Hive的异同
- 数据存储:使用相同的存储数据池都支持把数据存储于HDFS, HBase。
- 元数据:两者使用相同的元数据。
- SQL解释处理:比较相似都是通过词法分析生成执行计划。
执行计划:
- Hive: 依赖于MapReduce执行框架,执行计划分成 map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会 被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特点,过多的中间过程会增加整个Query的执行时间。
- Impala: 把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的 map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。
数据流:
- Hive: 采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。
- Impala: 采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以立即展现出来,而不用等到全部处理完成,更符合SQL交互式查询使用。
内存使用:
- Hive: 在执行过程中如果内存放不下所有数据,则会使用外存,以保证Query能顺序执行完。每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作。
- Impala: 在遇到内存放不下数据时,当前版本1.0.1是直接返回错误,而不会利用外存,以后版本应该会进行改进。这使用得Impala目前处理Query会受到一 定的限制,最好还是与Hive配合使用。Impala在多个阶段之间利用网络传输数据,在执行过程不会有写磁盘的操作(insert除外)。
调度:
- Hive: 任务调度依赖于Hadoop的调度策略。
- Impala: 调度由自己完成,目前只有一种调度器simple-schedule,它会尽量满足数据的局部性,扫描数据的进程尽量靠近数据本身所在的物理机器。调度器 目前还比较简单,在SimpleScheduler::GetBackend中可以看到,现在还没有考虑负载,网络IO状况等因素进行调度。但目前 Impala已经有对执行过程的性能统计分析,应该以后版本会利用这些统计信息进行调度吧。
容错:
- Hive: 依赖于Hadoop的容错能力。
- Impala: 在查询过程中,没有容错逻辑,如果在执行过程中发生故障,则直接返回错误(这与Impala的设计有关,因为Impala定位于实时查询,一次查询失败, 再查一次就好了,再查一次的成本很低)。但从整体来看,Impala是能很好的容错,所有的Impalad是对等的结构,用户可以向任何一个 Impalad提交查询,如果一个Impalad失效,其上正在运行的所有Query都将失败,但用户可以重新提交查询由其它Impalad代替执行,不 会影响服务。对于State Store目前只有一个,但当State Store失效,也不会影响服务,每个Impalad都缓存了State Store的信息,只是不能再更新集群状态,有可能会把执行任务分配给已经失效的Impalad执行,导致本次Query失败。
适用面:
- Hive: 复杂的批处理查询任务,数据转换任务。
- Impala:实时数据分析,因为不支持UDF,能处理的问题域有一定的限制,与Hive配合使用,对Hive的结果数据集进行实时分析。
Impala 与Hive都是构建在Hadoop之上的数据查询工具,但是各有不同侧重,那么我们为什么要同时使用这两个工具呢?单独使用Hive或者Impala不可以吗?
一、介绍Impala和Hive
(1)Impala和Hive都是提供对HDFS/Hbase数据进行SQL查询的工具,Hive会转换成MapReduce,借助于YARN进行调度从而实现对HDFS的数据的访问,而Impala直接对HDFS进行数据查询。但是他们都是提供如下的标准SQL语句,在机身里运行。

(2)Apache Hive是MapReduce的高级抽象,使用HiveQL,Hive可以生成运行在Hadoop集群的MapReduce或Spark作业。Hive最初由Facebook大约在2007年开发,现在是Apache的开源项目。
Apache Impala是高性能的专用SQL引擎,使用Impala SQL,因为Impala无需借助任何的框架,直接实现对数据块的查询,所以查询延迟毫秒级。Impala受到Google的Dremel项目启发,2012年由Cloudera开发,现在是Apache开源项目。
二、Impala和Hive有什么不同?
(1)Hive有很多的特性:
1、对复杂数据类型(比如arrays和maps)和窗口分析更广泛的支持
2、高扩展性
3、通常用于批处理
(2)Impala更快
1、专业的SQL引擎,提供了5x到50x更好的性能
2、理想的交互式查询和数据分析工具
3、更多的特性正在添加进来
三、高级概述:

四、为什么要使用Hive和Impala?
1、为数据分析人员带来了海量数据分析能力,不需要软件开发经验,运用已掌握的SQL知识进行数据的分析。
2、比直接写MapReduce或Spark具有更好的生产力,5行HiveQL/Impala SQL等同于200行或更多的Java代码。
3、提供了与其他系统良好的互操作性,比如通过Java和外部脚本扩展,而且很多商业智能工具支持Hive和Impala。
五、Hive和Impala使用案例
(1)日志文件分析
日志是普遍的数据类型,是当下大数据时代重要的数据源,结构不固定,可以通过Flume和kafka将日志采集放到HDFS,然后分析日志的结构,根据日志的分隔符去建立一个表,接下来运用Hive和Impala 进行数据的分析。例如:

(2)情感分析
很多组织使用Hive或Impala来分析社交媒体覆盖情况。例如:

(3)商业智能
很多领先的BI工具支持Hive和Impala

Impala和Hive的关系(详解)的更多相关文章
- slf4j log4j logback关系详解和相关用法
slf4j log4j logback关系详解和相关用法 写java也有一段时间了,一直都有用slf4j log4j输出日志的习惯.但是始终都是抱着"拿来主义"的态度,复制粘贴下配 ...
- 【转】UML类图与类的关系详解
UML类图与类的关系详解 2011-04-21 来源:网络 在画类图的时候,理清类和类之间的关系是重点.类的关系有泛化(Generalization).实现(Realization).依赖(D ...
- UML类图与类的关系详解
摘自:http://www.uml.org.cn/oobject/201104212.asp UML类图与类的关系详解 2011-04-21 来源:网络 在画类图的时候,理清类和类之间的关系是重点.类 ...
- Hibernate中的多对多关系详解(3)
前面两节我们讲到了一对一的关系,一对多,多对一的关系,相对来说,是比较简单的,但有时,我们也会遇到多对多的关系,比如说:角色与权限的关系,就是典型的多对多的关系,因此,我有必要对这种关系详解,以便大家 ...
- Hadoop Hive sql语法详解
Hadoop Hive sql语法详解 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件 ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- slf4j log4j logback log4j2关系详解和相关用法
来源:slf4j log4j logback关系详解和相关用法https://www.cnblogs.com/Sinte-Beuve/p/5758971.html The Simple Logging ...
- Hive的配置详解和日常维护
Hive的配置详解和日常维护 一.Hive的参数配置详解 1>.mapred.reduce.tasks 默认为-1.指定Hive作业的reduce task个数,如果保留默认值,则Hive 自 ...
随机推荐
- Java虚拟机六 堆溢出的处理
在Java程序中,如果堆空间不足,有可能抛出内存溢出错误:Out Of Memory,简称OOM. Exception in thread "main" java.lang.Out ...
- JDBC 连接数据库,包含连接池
1.不使用连接池方式(Jdbc) 1.1 工具类(JdbcUtil.java) package com.jdbc.util; import java.io.IOException;import jav ...
- jdk 与jre
1. 定义JRE(Java Runtime Enviroment)是Java的运行环境.面向Java程序的使用者,而不是开发者.如果你仅下载并安装了JRE,那么你的系统只能运行Java程序.JRE是运 ...
- IIS7.5 配置虚拟目录的经历
好多网站为了不带上什么端口号所有就建立虚拟目录的试来使用80端口 iis6设置都没有问题可到了7.5碰到了点问题 原来7.5上有个:添加应用程序和添加虚拟目录.还有个转换为应用程序 直接把网站建成虚拟 ...
- Docker 学习应用篇三:使用docker搭建的环境,安装thinksns
Thinksns 是一个开源的社交网站,因为目前的项目需要用到这个,所以就下载一个安装试试看. 之前在windows上用了wamp,安装的很顺利.但是项目是要部署到linux上的.于是我便用了Dock ...
- HDU 6447 - YJJ's Salesman - [树状数组优化DP][2018CCPC网络选拔赛第10题]
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6447 Problem DescriptionYJJ is a salesman who has tra ...
- HIT 2739 - The Chinese Postman Problem - [带权有向图上的中国邮路问题][最小费用最大流]
题目链接:http://acm.hit.edu.cn/hoj/problem/view?id=2739 Time limit : 1 sec Memory limit : 64 M A Chinese ...
- 最大生成树——LCA
今天说是要练习LCA结果找了道题看着题解打完了,如此惭愧,Lca还得好好理解啊,感觉在最大生成树上做有点异样,可能还是不是很理解吧,在noip前一定要再把这道题再a一遍,好题啊. 这是2013noip ...
- QtCreator 可以通过 Clang-Tidy 和 CLazy 对你的代码进行静态检查
QtCreator 可以通过 Clang-Tidy 和 CLazy 对你的代码进行静态检查 打开你的工程,点击Analyze -> Clang-Tidy and CLazy 选择你想分析的 cp ...
- 算法抽象及用Python实现具体算法
一.算法抽象 它们一般是在具体算法的基础上总结.提炼.分析出来的,再反过来用于指导解决其它问题.它们适用于某一类问题的解决,用辩 证法的观点看,抽象的算法和具体的算法就是抽象与具体.普遍性与特殊性.共 ...