JAVA——遍历
关于遍历,发现了个坑。 详见如下:
package com.fxl.test; import java.util.ArrayList;
import java.util.Iterator;
import java.util.List; public class TestLoop { public static void main(String[] args) {
List<String> list = new ArrayList();
for(int i=0;i<10000*100;i++){
list.add("test"+i);
}
test1(list);
test2(list);
}
public static void test1(List<String> list){
long start = System.currentTimeMillis();
long num = 0l;
for(String str : list){
num += Long.parseLong(str.replace("test", ""));
}
System.out.println("result:"+num + "\n use Time:"+(System.currentTimeMillis()-start)/1000);
} public static void test2(List<String> list){
long start = System.currentTimeMillis();
long num = 0l;
/*for(Iterator<String> it=list.iterator(); it.hasNext();){
num += Long.parseLong(it.next().replace("test", ""));
it.remove();
}*/
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String str = it.next();
num += Long.parseLong(str.replace("test", ""));
it.remove();
} System.out.println("result:"+num + "\n use Time:"+(System.currentTimeMillis()-start)/1000);
} }
运行结果:
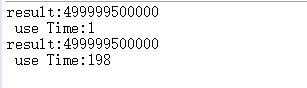
看,是不是很6,按理来说,一边遍历一边删除会少遍历一些,速度会快一些,but。。。。。。
JAVA——遍历的更多相关文章
- java 遍历map 方法 集合 五种的方法
package com.jackey.topic; import java.util.ArrayList;import java.util.HashMap;import java.util.Itera ...
- java 遍历文件夹里的文件
Java遍历文件夹的2种方法: A.不使用递归: import java.io.File; import java.util.LinkedList; public class FileSystem { ...
- JAVA 遍历文件夹下的所有文件
JAVA 遍历文件夹下的所有文件(递归调用和非递归调用) 1.不使用递归的方法调用. public void traverseFolder1(String path) { int fileNum = ...
- java遍历树(深度遍历和广度遍历
java遍历树如现有以下一颗树:A B B1 B11 B2 B22 C C ...
- java遍历Hashmap/Hashtable的几种方法
一>java遍历Hashtabe: import java.util.Hashtable; import java.util.Set; public class HashTableTest { ...
- JAVA 遍历文件夹下的所有文件(递归调用和非递归调用)
JAVA 遍历文件夹下的所有文件(递归调用和非递归调用) 1.不使用递归的方法调用. public void traverseFolder1(String path) { int fileNum = ...
- java 遍历List 和 Map的几种方法
java遍历List 1.(性能最差) for(String tmp:list) { //System.out.println(tmp); } 2.(性能最好) for(int i = 0; i &l ...
- java 遍历Map的四种方式
java 遍历Map的四种方式 CreationTime--2018年7月16日16点15分 Author:Marydon 一.迭代key&value 第一种方式:迭代entrySet 1 ...
- Java 遍历指定文件夹及子文件夹下的文件
Java 遍历指定文件夹及子文件夹下的文件 /** * 遍历指定文件夹及子文件夹下的文件 * * @author testcs_dn * @date 2014年12月12日下午2:33:49 * @p ...
- Java遍历Map键、值。获取Map大小的方法
Map读取键值对,Java遍历Map的两种实现方法 第一种方法是根据map的keyset()方法来获取key的set集合,然后遍历map取得value的值 import java.util.HashM ...
随机推荐
- 小峰servlet/jsp(2)
一.jsp javaBean组件引入 <jsp:useBean id="实例化对象名称" scope="保存范围" class="类完整名称&q ...
- 发送邮件(单独文字)的方法(网易邮箱 OR QQ邮箱)
# coding:utf-8import smtplibfrom email.mime.text import MIMEText # 发邮件相关的参数# 网易邮箱用这个# smtpserver=&qu ...
- linux中uptime命令查看linux系统负载
阅读目录 uptime cat /proc/loadavg 何为系统负载呢? 进阶参考 uptime 另外还有一个参数 -V(大写),是用来查询版本的 [appdeploy@CNSZ22PL0088: ...
- [UE4]动画事件
在动画中添加事件通知,在动画蓝图中就可以使用这个事件通知: 在动画蓝图中可以使用“Try Get Pawn Owner”取得控制的角色实例 在Controller中,可以使用“Get Controll ...
- 如何在FreePBX ISO 中文版本安装讯时网关,潮流16FXS 网关和潮流话机
如何在FreePBX ISO 中文版本安装讯时网关,潮流16FXS 网关和潮流话机摘自:http://www.siplab.cn/?p=664 1)迅时的fxo口网关要注册到asterisk,所以现在 ...
- Mac parallels desktop安装windows,linux
前言 这款软件你就看作是虚拟机vm,如果你要安装win10系统,请下载ios镜像文件 下载准备工作 Parallels Desktop 13 破解版本 联系站长所要 win10 iso镜像文件 ...
- DeepFM模型理论及代码实现
论文地址:DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
- Jquery阻断事件冒泡(转载)
JQuery阻止事件冒泡 冒泡事件就是点击子节点,会向上触发父节点,祖先节点的点击事件. 我们在平时的开发过程中,肯定会遇到在一个div(这个div可以是元素)包裹一个div的情况,但是呢,在这两个d ...
- js的sort(0实现数组的排序
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content ...
- 使用spring注解——定义bean和自动注入
对于java bean的定义和依赖配置,使用xml文件真心是不方便. 今天学习如何用注解,解决bean的定义和注入. 常用注解: 1.自动注入:@Resources,@Autowired 2.Bean ...