【深入浅出Seata原理及实战】「入门基础专题」探索Seata服务的AT模式下的分布式开发实战指南(2)
承接上文
上一篇文章说到了Seata 为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。那么接下来我们将要针对于AT模式下进行分布式事务开发的原理进行介绍以及实战。
Seata AT模式
在AT、TCC、SAGA 和 XA 这四种事务模式中使用最多,最方便的就是 AT 模式。与其他事务模式相比,AT 模式可以应对大多数的业务场景,且基本可以做到无业务入侵,开发人员能够有更多的精力关注于业务逻辑开发。
使用AT模式的前提
任何应用想要使用Seata的 AT 模式对分布式事务进行控制,必须满足以下 2 个前提:
- 必须使用支持本地 ACID 事务特性的关系型数据库,例如 MySQL、Oracle 等;
- 应用程序必须是使用 JDBC 对数据库进行访问的 JAVA 应用。
Seata安装使用
下载地址
Seata服务进行下载的地址:https://seata.io/zh-cn/blog/download.html,访问之后可以看到下面的资源中,可以直接进行下载,如下图所示。
但是由于官方维护的稍微缓慢,所以并不是最新的版本,如果你想要下载较新的版本,可以去官方的Git仓库中进行下载对应的版本文件包。地址为:https://github.com/seata/seata/releases,可以看到下面的最新版本已经到了1.6.1了
我们选择下载对应的可执行包即可。
创建UNDO_LOG表
SEATA AT模式需要针对业务中涉及的各个数据库表,分别创建一个UNDO_LOG(回滚日志)表。不同数据库在创建 UNDO_LOG 表时会略有不同,以 MySQL 为例,其 UNDO_LOG 表的创表语句如下:
-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
启动服务
下载服务器软件包后,将其解压缩。主要通过脚本进行启动Seata服务
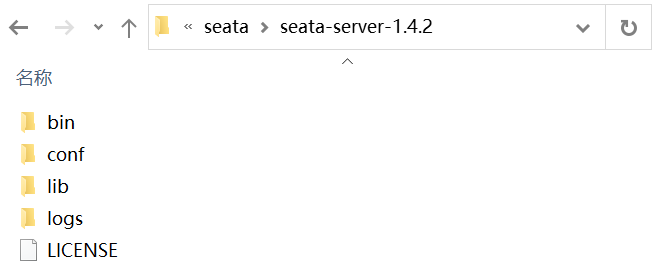
Seata Server 目录中包含以下子目录:
- bin:用于存放Seata Server可执行命令。
- conf:用于存放Seata Server的配置文件。
- lib:用于存放Seata Server依赖的各种 Jar 包。
- logs:用于存放Seata Server的日志。
Seata Server的执行脚本
- seata-server.sh:主要是为Linux和Mac系统准备的启动脚本。执行
sh seata-server.sh启动服务。 - seata-server.bat:主要是为Windows系统准备的启动脚本。执行
cmd seata-server.bat启动服务。
其中参数的选择范围如下所示
--host, -h(简略指令)该地址向注册中心公开,其他服务可以通过该ip访问seata-server,默认: 0.0.0.0
--port, -p(简略指令) 监听的端口,默认值为8091
--storeMode, -m(简略指令)日志存储模式 : file(文件)、db(数据库),默认为:file
--help 帮助指令
例如执行shell脚本
sh seata-server.sh -p 8091 -h 127.0.0.1 -m file
AT 模式的工作机制
Seata的AT模式工作时大致可以分为以两个阶段,下面我们就结合一个实例来对 AT 模式的工作机制进行介绍。
整体机制
两阶段提交协议的演变:
- 一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
- 二阶段:提交异步化,非常快速地完成。回滚通过一阶段的回滚日志进行反向补偿。
AT模式一阶段
Seata AT模式一阶段的工作流程如下图所示
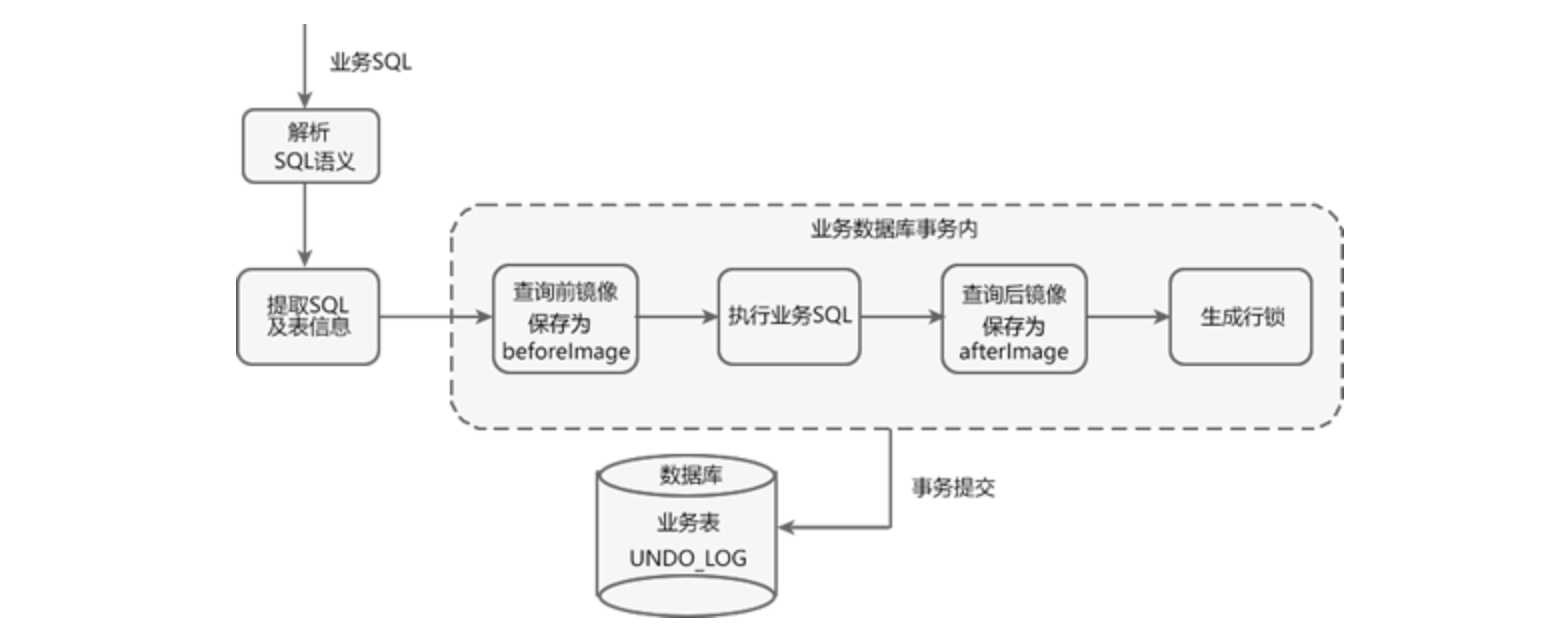
业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
第一子阶段-获取SQL的基本信息
Seata拦截并解析业务SQL,得到SQL 的操作类型(INSERT/UPDATE/DELETE)、表名(tableXXX)、判断条件(where condition = value)等相关信息。
第二子阶段-查询并备份【执行之前】的数据快照
根据得到的业务SQL信息,生成“前镜像查询语句”。
select * from tableXX where condition=value;
执行“前镜像查询语句”,得到即将执行操作的数据,并将其保存为“前镜像数据(beforeImage)”。
第三子阶段-执行业务操作的SQL语句
执行业务SQL,例如(update tableXX set parameter = 'value' where condition = value;),将这条记录的进行修改。
第四子阶段-查询业务操作之后的数据,并且保存下来
查询后镜像:根据“前镜像数据”的主键(id : X),生成“后镜像查询语句”。
select * from tableXX where condition=value;
执行“后镜像查询语句”,得到执行业务操作后的数据,并将其保存为“后镜像数据(afterImage)”。
第五子阶段-插入保存回滚日志记录到undo_log表中
将前后镜像数据和业务SQL的信息组成一条回滚日志记录,插入到 UNDO_LOG 表中,示例回滚日志如下。
{
"branchId": 641789253,
"undoItems": [{
"afterImage": {
"rows": [{
"fields": [{
"name": "id",
"type": 4,
"value": 1
}, {
"name": "name",
"type": 12,
"value": "GTS"
}, {
"name": "since",
"type": 12,
"value": "2014"
}]
}],
"tableName": "product"
},
"beforeImage": {
"rows": [{
"fields": [{
"name": "id",
"type": 4,
"value": 1
}, {
"name": "name",
"type": 12,
"value": "TXC"
}, {
"name": "since",
"type": 12,
"value": "2014"
}]
}],
"tableName": "product"
},
"sqlType": "UPDATE"
}],
"xid": "xid:xxx"
}
提交前需要获取申请本地锁
- 提交前,向TC注册分支:申请TableXXX表中,id主键等于N的记录的全局锁 。需要确保先拿到全局锁 。
- 拿不到全局锁 ,不能提交本地事务。
- 拿到全局锁,会被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。
示例说明:
两个全局事务tx1和tx2,分别对a表的m字段进行更新操作,m的初始值1000。
tx1先开始,开启本地事务,拿到本地锁,更新操作 m = 1000 - 100 = 900。本地事务提交前,先拿到该记录的全局锁 ,本地提交释放本地锁。
tx2后开始,开启本地事务,拿到本地锁,更新操作 m = 900 - 100 = 800。本地事务提交前,尝试拿该记录的全局锁 ,tx1 全局提交前,该记录的全局锁被 tx1 持有,tx2需要重试等待 全局锁 。
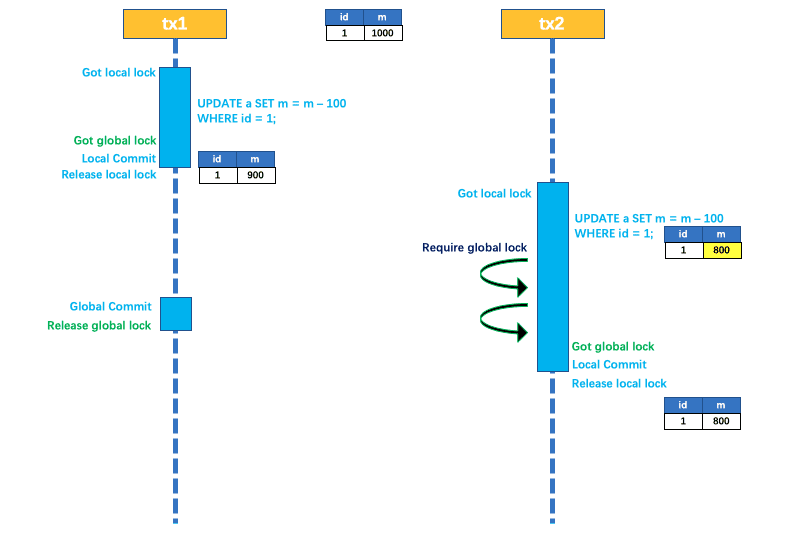
tx1二阶段全局提交,释放全局锁 。tx2 拿到全局锁提交本地事务
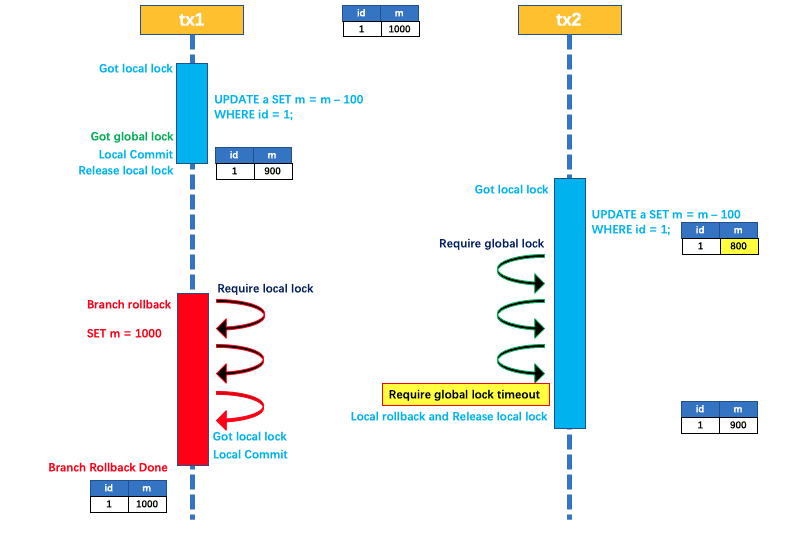
如果tx1的二阶段全局回滚,则tx1需要重新获取该数据的本地锁,进行反向补偿的更新操作,实现分支的回滚。
此时,如果tx2仍在等待该数据的全局锁,同时持有本地锁,则tx1的分支回滚会失败。分支的回滚会一直重试,直到tx2的全局锁等锁超时,放弃全局锁并回滚本地事务释放本地锁,tx1 的分支回滚最终成功。因为整个过程全局锁在tx1结束前一直是被tx1持有的,所以不会发生脏写的问题。
数据库隔离级别
在数据库本地事务隔离级别,读已提交(Read Committed)或以上的基础上,Seata(AT 模式)的默认全局隔离级别是读未提交(Read Uncommitted) 。
如果应用在特定场景下,必需要求全局的读已提交 ,目前Seata的方式是通过 SELECT FOR UPDATE 语句的代理。
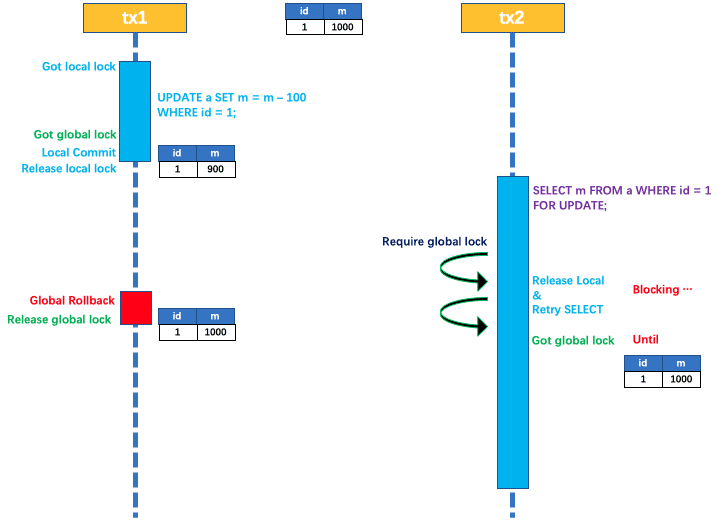
SELECT FOR UPDATE 语句的执行会申请全局锁 ,如果全局锁被其他事务持有,则释放本地锁(回滚 SELECT FOR UPDATE 语句的本地执行)并重试。这个过程中,查询是被 block 住的,直到全局锁拿到,即读取的相关数据是已提交的,才返回。
出于总体性能上的考虑,Seata目前的方案并没有对所有 SELECT 语句都进行代理,仅针对 FOR UPDATE 的 SELECT 语句。
本地事务提交
业务数据的更新和前面步骤中生成的UNDO LOG一并提交,将本地事务提交的结果上报给TC。
AT模式二阶段-回滚操作
收到TC的分支回滚请求,开启一个本地事务。
通过XID和Branch ID查找到相应的UNDO LOG 记录。
数据校验:拿 UNDO LOG 中的后镜与当前数据进行比较,如果有不同,说明数据被当前全局事务之外的动作做了修改。这种情况,需要根据配置策略来做处理,详细的说明在另外的文档中介绍。
根据 UNDO LOG 中的前镜像和业务SQL的相关信息生成并执行回滚的语句:
update TableXXX set parameter = 'XXX' where condition = value;
- 提交本地事务,并把本地事务的执行结果(即分支事务回滚的结果)上报给 TC。
AT模式二阶段-提交操作
收到TC的分支提交请求,把请求放入一个异步任务的队列中,马上返回提交成功的结果给 TC。
异步任务阶段的分支提交请求将异步和批量地删除相应 UNDO LOG 记录。
【深入浅出Seata原理及实战】「入门基础专题」探索Seata服务的AT模式下的分布式开发实战指南(2)的更多相关文章
- 我叫Mongo,收了「查询基础篇」,值得你拥有
这是mongo第二篇「查询基础篇」,后续会连续更新6篇 mongodb的文章总结上会有一系列的文章,顺序是先学会怎么用,在学会怎么用好,戒急戒躁,循序渐进,跟着我一起来探索交流. 通过上一篇基础篇的介 ...
- 🏆【Alibaba中间件技术系列】「RocketMQ技术专题」系统服务底层原理以及高性能存储设计分析
设计背景 消息中间件的本身定义来考虑,应该尽量减少对于外部第三方中间件的依赖.一般来说依赖的外部系统越多,也会使得本身的设计越复杂,采用文件系统作为消息存储的方式. RocketMQ存储机制 消息中间 ...
- 「mysql优化专题」高可用性、负载均衡的mysql集群解决方案(12)
一.为什么需要mysql集群? 一个庞大的分布式系统的性能瓶颈中,最脆弱的就是连接.连接有两个,一个是客户端与后端的连接,另一个是后端与数据库的连接.简单如图下两个蓝色框框(其实,这张图是我在悟空问答 ...
- 【HBase基础教程】1、HBase之单机模式与伪分布式模式安装(转)
在这篇blog中,我们将介绍Hbase的单机模式安装与伪分布式的安装方式,以及通过浏览器查看Hbase的用户界面.搭建hbase伪分布式环境的前提是我们已经搭建好了hadoop完全分布式环境,搭建ha ...
- ☕【Java技术指南】「并发编程专题」Fork/Join框架基本使用和原理探究(基础篇)
前提概述 Java 7开始引入了一种新的Fork/Join线程池,它可以执行一种特殊的任务:把一个大任务拆成多个小任务并行执行. 我们举个例子:如果要计算一个超大数组的和,最简单的做法是用一个循环在一 ...
- ☕【Java技术指南】「并发编程专题」CompletionService框架基本使用和原理探究(基础篇)
前提概要 在开发过程中在使用多线程进行并行处理一些事情的时候,大部分场景在处理多线程并行执行任务的时候,可以通过List添加Future来获取执行结果,有时候我们是不需要获取任务的执行结果的,方便后面 ...
- ☕【Java技术指南】「并发编程专题」针对于Guava RateLimiter限流器的入门到精通(含实战开发技巧)
并发编程的三剑客 在开发高并发系统时有三剑客:缓存.降级和限流. 缓存 缓存的目的是提升系统访问速度和增大系统处理容量. 降级 降级是当服务出现问题或者影响到核心流程时,需要暂时屏蔽掉,待高峰或者问题 ...
- 🏆【Alibaba中间件技术系列】「Nacos技术专题」服务注册与发现相关的原理分析
背景介绍 前几篇文章介绍了Nacos配置中心服务的能力机制,接下来,我们来介绍Nacos另一个非常重要的特性就是服务注册与发现,说到服务的注册与发现相信大家应该都不陌生,在微服务盛行的今天,服务是非常 ...
- 「mysql优化专题」这大概是一篇最好的mysql优化入门文章(1)
优化,一直是面试最常问的一个问题.因为从优化的角度,优化的思路,完全可以看出一个人的技术积累.那么,关于系统优化,假设这么个场景,用户反映系统太卡(其实就是高并发),那么我们怎么优化? 如果请求过多, ...
- 【Maven实战技巧】「插件使用专题」Maven-Assembly插件实现自定义打包
前提概要 最近我们项目越来越多了,然后我就在想如何才能把基础服务的打包方式统一起来,并且可以实现按照我们的要求来生成,通过研究,我们通过使用maven的assembly插件完美的实现了该需求,爽爆了有 ...
随机推荐
- Vue学习之--------深入理解Vuex、原理详解、实战应用(2022/9/1)
@ 目录 1.概念 2.何时使用? 3.搭建vuex环境 3.1 创建文件:src/store/index.js 3.2 在main.js中创建vm时传入store配置项 4.基本使用 4.1.初始化 ...
- Jedis测试redis。(redis在linux虚拟机中)
文章目录 1.确保虚拟机开启.并且连接到redis 2.建立一个maven工程 3.在pom中加入jedis的依赖 4.编写测试用例 5.测试结果 1.确保虚拟机开启.并且连接到redis 2.建立一 ...
- 齐博x1内容评论标签的风格制作
评论的标签如下: {qb:comment name="xxxxx" rows='5'} HTML代码片段 {/qb:comment} 评论涉及到的元素有{posturl} 这个是代 ...
- nrf52——DFU升级USB/UART升级方式详解(基于SDK开发例程)
摘要:在前面的nrf52--DFU升级OTA升级方式详解(基于SDK开发例程)一文中我测试了基于蓝牙的OTA,本文将开始基于UART和USB(USB_CDC_)进行升级测试. 整体升级流程: 整个过程 ...
- 长事务 (Long Transactions)
长事务 长事务用于支持 AutoCAD 参照编辑功能,对于 ObjectARX 应用程序非常有用.这些类和函数为应用程序提供了一种方案,用于签出实体以进行编辑并将其签回其原始位置.此操作会将原始对象替 ...
- SpringBoot&MyBatisPlus
5. SpringBoot 学习目标: 掌握基于SpringBoot框架的程序开发步骤 熟练使用SpringBoot配置信息修改服务器配置 基于SpringBoot完成SSM整合项目开发 5.1 入门 ...
- SpringMVC&Maven进阶
3. SpringMVC 3.1 了解SpringMVC 概述 SpringMVC技术与Servlet技术功能等同,均属于web层开发技术 学习路线 请求与响应 REST分割 SSM整合 拦截器 目标 ...
- 从0搭建vue3组件库: Input组件
本篇文章将为我们的组件库添加一个新成员:Input组件.其中Input组件要实现的功能有: 基础用法 禁用状态 尺寸大小 输入长度 可清空 密码框 带Icon的输入框 文本域 自适应文本高度的文本域 ...
- 【网络】内网穿透方案&FRP内网穿透实战(基础版)
目录 前言 方案 方案1:公网 方案2:第三方内网穿透软件 花生壳 cpolar 方案3:云服务器做反向代理 FRP简介 FRP资源 FRP原理 FRP配置教程之SSH 前期准备 服务器配置 下载FR ...
- 题解合集 (update on 11.5)
收录已发布的题解 按发布时间排序. 部分可能与我的其他文章有重复捏 qwq . AtCoder for Chinese: Link ZHOJ: Link 洛谷 \(1\sim 5\) : [题解]CF ...