WebGPU 导入[2] - 核心概念与重要机制解读
1. 核心概念
这部分不会详细展开,以后写教程时会深入。以下只是核心概念,是绝大多数 WebGPU 原生程序要接触的,并不是全部。
① 适配器和设备
适配器,也就是 GPUAdapter,指代真正的物理显卡,WebGPU 给了个对象来代替它:
const adapter = await navigator.gpu.requestAdapter()
它提供了一个最重要行为,请求设备对象 GPUDevice:
const device = await adapter.requestDevice()
那么什么是 Device?其实,显卡很忙。
WebGPU 程序只是三大图形 API 中某个的“上层封装”,除了 WebGPU,调用三大图形 API 的程序远不止,游戏、三维建模工具、视频编解码器,都有可能会调用,甚至会直接调取 GPU 厂商给的 SDK 或驱动程序。
显然,作为显卡“本身”,适配器为了极高效率地工作,喂给它的数据资源和指令最好就是翻译过的,尽可能专注地执行计算 —— 就像大老板不可能日理万机一样,最好给到老板的决策资料,就是经过整理的,他要做的就是使用他多年的经验快速决策、签字(效率高的老总 = RTX4090,超市小老板 = GT1030)。
那么,谁负责与各个部门(各个对显卡有需要的程序)负责人沟通具体业务呢?
我认为是老总的全权代理人,一般是秘书 + 副总经理。
不同封装有不同的概念,至少在 WebGPU 中,这个代理人叫做“设备”,GPUDevice,它几乎就是显卡的分身,WebGPU 程序中所要调取的资源、创建的对象、要触发的行为,都交给设备对象实现。
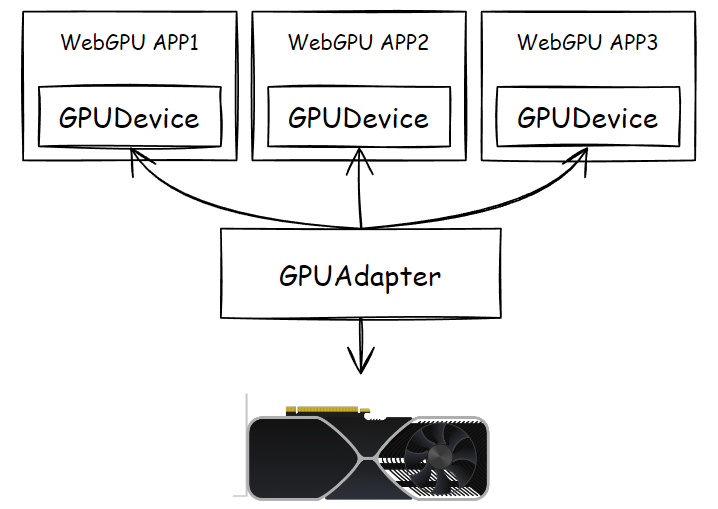
每个 WebGPU 程序应该都有自己的 GPUDevice,不同的设备对象创建的 Buffer、Texture 等资源是不互通的,而适配器呢,一般情况下是同一个,除非你短时间内把电脑的显卡给更改过,前一会儿是独显,过一会儿可能是核显了(这段话还有待技术验证,仅为我不负责任的猜测)。
如果你写过原生的 WebGL,你可能会联想到 gl 上下文变量了,没错,设备对象大部分时候就是 gl 上下文的作用,但是是有本质区别的。
② 缓冲、纹理、采样器
缓冲、纹理,即 GPUBuffer、GPUTexture 均是 GPU 显存中的数据对象,能在客户端代码(如果没特别说明,就是指浏览器端的 JavaScript)组织、创建、上载数据、相互转化、反读数据。
WebGPU 进行渲染绘图时,Canvas 是一个特殊的 GPUTexture。
采样器则是着色器程序对纹理采样时的参数封装。
看起来是 WebGL 类似对象 WebGLBuffer、WebGLTexture 以及纹理采样函数的“升级”,实际上调用时提供了更细致的传参,在数据上载、纹理与缓冲相互转化、再从显存读取到内存的“映射机制”上却大有不同。
这三个对象被称作“资源”,均由 GPUDevice 创建。
③ 绑定组
绑定组,我更愿意称之为“资源绑定组”,即 GPUBindGroup;资源即“缓冲、纹理、采样器”的任意组合。
使用绑定组,允许把一组你需要的资源“打组”,传进着色器代码中,它与下面的“管线”是紧密相关的。
为什么要打组呢?为什么我不能写个函数,按我需要把 GPUBuffer、GPUTexture、GPUSampler 挨个像 WebGL 一样绑定到某个绑定点呢?
有两个原因:
- 性能角度:打组本身就是减少 CPU 到 GPU 信号通讯的一种方式,想想你的硬盘,是连续大文件传得快,还是细碎的小文件快?
- 复用角度:不同的着色行为可能会用一样的资源集合,此时同一个绑定组就可以复用;想一想,肉馅儿塞进包子里叫肉包,包进饺子皮里就是肉饺子了。
绑定组是由 GPUDevice 创建的,是由第 ⑤ 小节中的 可编程通道编码器 调用并与管线实际一起运作的。
④ 着色器与管线
着色器即 GPUShaderModule,管线一般指 GPURenderPipeline、GPUComputePipeline 两个。
着色器支持把任意着色器混在一段字符串中,顶点着色器、片元着色器、计算着色器可以共用一个 GPUShaderModule 对象,只需指定入口函数,这点与 WebGL 分开创建 VS、FS 是不一样的。
管线可不是 WebGLProgram 的升级,虽然 gl.useProgram 和 passEncoder.setPipeline 在行为上有类似的作用,即切换到指定的行为过程,但是,在 WebGPU 中这两个管线对象,除了附着对应的着色器对象外,还限定着管线不同阶段对应的状态参数。有三个状态参数对应着两大管线:
vertex、fragment
compute
例如:
/*
---------
这里不详细展开,仅作为简略
---------
*/
const positionAttribDesc: GPUVertexAttribute = {
shaderLocation: 0, // wgsl - @location(0)
offset: 0,
format: 'float32x3'
}
const colorAttribDesc: GPUVertexAttribute = {
shaderLocation: 1, // wgsl - @location(1)
offset: 0,
format: 'float32x3'
}
const positionBufferDesc: GPUVertexBufferLayout = {
attributes: [positionAttribDesc],
arrayStride: 4 * 3, // sizeof(float) * 3
}
const colorBufferDesc: GPUVertexBufferLayout = {
attributes: [colorAttribDesc],
arrayStride: 4 * 3, // sizeof(float) * 3
}
// --- 创建 state 参数对象
const vertexState: GPUVertexState = {
module: shaderModule,
entryPoint: 'vs_main',
buffers: [positionBufferDesc, colorBufferDesc]
}
const fragmentState: GPUFragmentState = {
module: shaderModule,
entryPoint: 'fs_main',
targets: [{
format: navigator.gpu.getPreferredCanvasFormat()
}],
}
const primitiveState: GPUPrimitiveState = {
topology: 'triangle-list'
}
// --- 渲染管线 ---
const renderPipeline = device.createRenderPipeline({
layout: 'auto',
vertex: vertexState,
fragment: fragmentState,
primitive: primitiveState
})
// --- 计算管线 ---
const computePipeline = device.createComputePipeline({
layout: 'auto',
compute: {
module: shaderModule,
entryPoint: 'cs_main',
}
})
对应 GPUVertexState、GPUFragmentState、GPUComputeState 类型;上面说到绑定组是与管线紧密相关的,这几个状态参数对象,与绑定组中的各个资源对象有着对应关系。
着色器模块对象和管线对象也是由 GPUDevice 创建的,管线对象甚至提供了异步创建的方法。
⑤ 编码器与队列
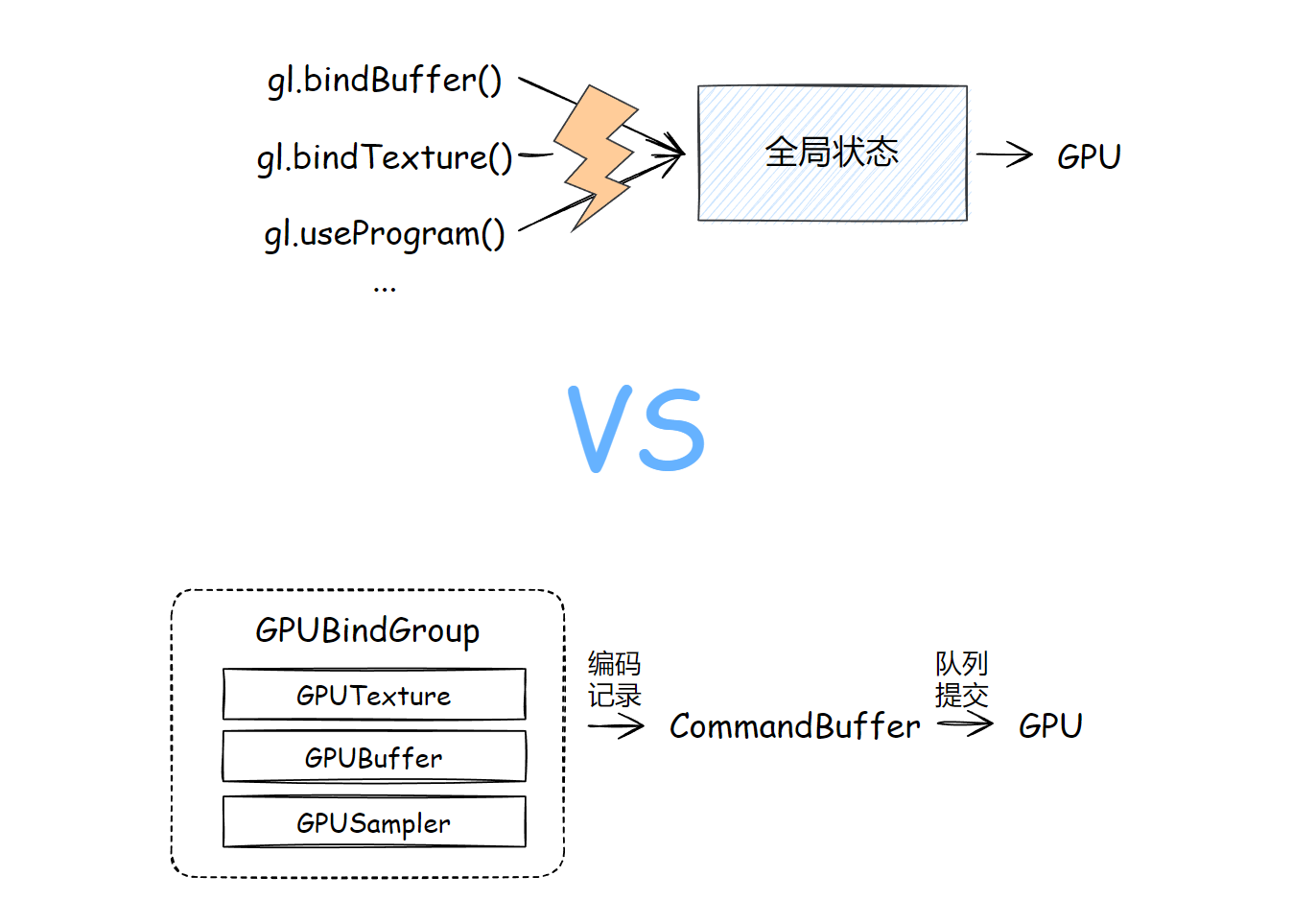
WebGPU 使用“编码器”去“记录”一帧内要做什么事情,譬如切换管线、设定接下来要用什么缓冲、绑定组,进而要进行什么操作(绘图或触发并行计算)。
这有什么好处?
编码器“记录”这些行为,是在 CPU 侧,也就是 JavaScript 完成的,这就解决了 WebGL 全局状态对象的问题:改变一个状态,就要发起一条或多条 GL 函数的调用(尽管使用扩展或在 WebGL 2.0 用各种技术进行了弥补,但是也不能实际解决问题)。
编码记录完成后,会在 CPU 这边生成一个叫做“指令缓冲”对象,把当前帧的所有指令缓冲一次性提交给一个队列,那么当前帧就结束了战斗。
合情合理,大部分的逻辑组织交给更擅长处理这些事情的 CPU 完成,最后集中发射给 GPU,这就是 WebGPU 于 WebGL 的一大优点。
编码器有哪些?
上面一段文字比较粗略。
首先,为了区分绘图操作、GPU 通用计算操作,WebGPU 使用“渲染通道编码器”、“计算通道编码器”,也就是 GPURenderPassEncoder、GPUComputePassEncoder 来实现各自的行为编码、记录;以渲染通道编码为例:

上图参考自博客 Raw WebGPU。
而能创建这两个特定 GPU 计算的“通道编码器”的,叫做“指令编码器”,也就是 GPUCommandEncoder:
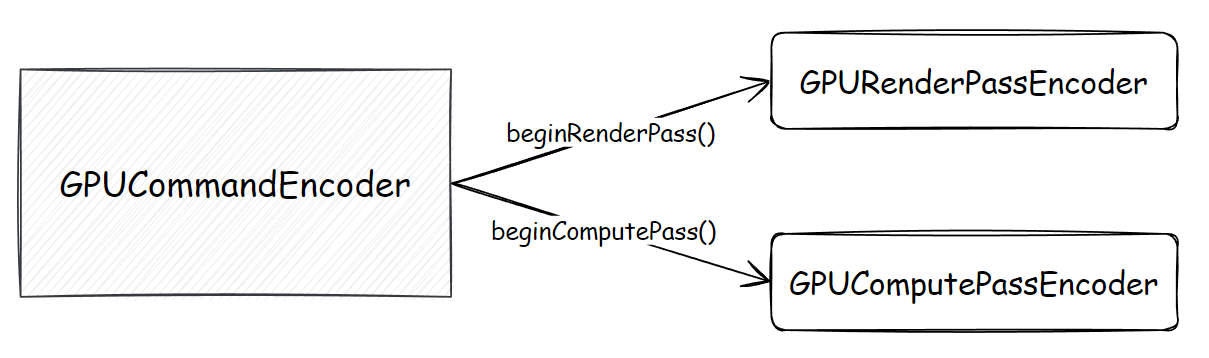
指令编码器除了承载上面两个通道编码器的编码结果外,还额外提供了资源的拷贝行为、查询行为的编码,例如纹理与缓冲对象之间的互相拷贝等:

在实际的代码中,是按 GPUCommandEncoder 调用某个方法的顺序进行记录的,例如 beginRenderPass()、copyBufferToTexture() 等。
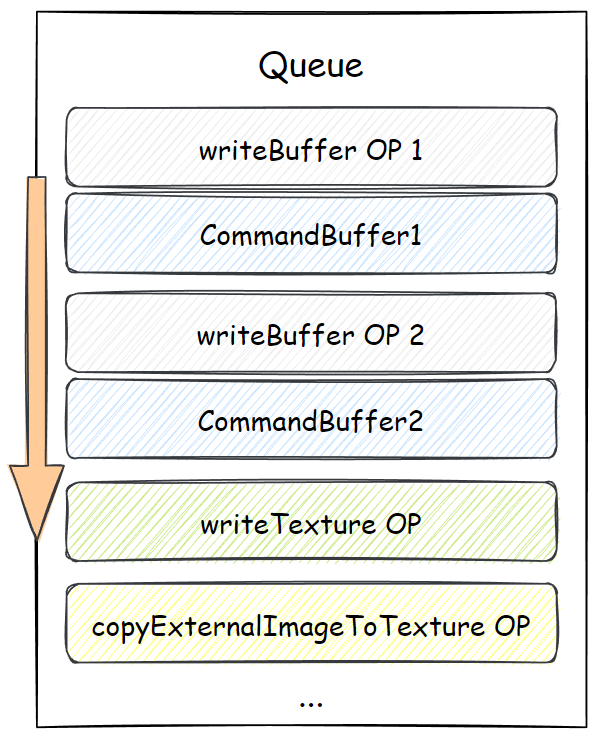
队列与指令缓冲
指令编码器的 finish 方法返回一个指令缓冲对象,即 GPUCommandBuffer,这个可以提交给队列对象 GPUQueue,队列对象是设备对象上的一个实例字段。
排列在队列上的除了指令缓冲,还有队列自己发出的“队列时间线”上的行为,例如写入缓冲数据、写入纹理数据等。图示如下:
2. 重要机制
① 缓冲映射机制
缓冲映射,简单的说就是使得内存、显存中的缓冲数据可以交换着用的一种机制。详细的文章可以参考:
② 时间线
WebGPU 规范中不同的行为也许发生在的层面是不一样的,每个层面在运作的过程中都有它自己的时间线。规范给出了三条时间线:
内容时间线:内容时间线上的行为,大多数是 JavaScript 对象的创建、JavaScript 方法的调用,这是最上面的一层;
设备时间线:此“设备”非
GPUDevice;设备时间线上的行为,大多数是指浏览器底层 WebGPU 实现中的变化,这类行为的层级低于 JavaScript 的执行,操作的是“内部对象”,却还没到 GPU 执行的部分,例如生成指令缓冲;队列时间线:此“队列”非
GPUQueue;队列时间线上发生的行为,通常就是指 GPU 中具体任务的执行,例如绘制、资源上载、资源复制、通用计算调度等。
WebGPU 导入[2] - 核心概念与重要机制解读的更多相关文章
- Elasticsearch学习笔记(六)核心概念和分片shard机制
一.核心概念 1.近实时(Near Realtime NRT) (1)从写入数据到数据可以被搜索到有一个小延迟(大概1秒): (2)基于es执行搜索和分析可以达到秒级 2.集群(Cluster) 一个 ...
- Elasticsearch之重要核心概念(cluster(集群)、shards(分配)、replicas(索引副本)、recovery(据恢复或叫数据重新分布)、gateway(es索引的持久化存储方式)、discovery.zen(es的自动发现节点机制机制)、Transport(内部节点或集群与客户端的交互方式)、settings(修改索引库默认配置)和mappings)
Elasticsearch之重要核心概念如下: 1.cluster 代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的.es的一个概念就是 ...
- 通过核心概念了解webpack工作机制
webpack 是一个现代 JavaScript 应用程序的静态模块打包器(module bundler).当 webpack 处理应用程序时,它会递归地构建一个依赖关系图(dependency gr ...
- docker核心概念(镜像、容器、仓库)及基本操作
概要 docker是一种linux容器技术.容器有效的将由单个操作系统挂管理的资源划分到孤立的组中,以便更好的在组之间平衡有冲突的资源使用需求.可简单理解为一种沙盒 .每个容器内运行一个应用,不同的容 ...
- ElasticSearch入门及核心概念介绍
Elasticsearch研究有一段时间了,现特将Elasticsearch相关核心知识和原理以初学者的角度记录下来,如有不当,烦请指正! 0. 带着问题上路——ES是如何产生的? (1)思考:大 ...
- Apache NiFi 核心概念和关键特性
本文来源于官方文档翻译 NiFi 的核心概念 NiFi 最早是美国国家安全局内部使用的工具,用来投递海量的传感器数据.后来由 apache 基金会开源.天生就具备强大的基因.NiFi基本设计理念与 F ...
- Spring核心概念和案例
一.Spring概念 1.Spring框架概述 轻量级的Java EE开源框架,它是由Rod Johnson为了解决企业应用程序开发的复杂性而创建, Spring框架提供了一个开发平台,用于整合其他技 ...
- Javascript本质第一篇:核心概念
很多人在使用Javascript之前都至少使用过C++.C#或Java,面向对象的编程思想已经根深蒂固,恰好Javascript在语法上借鉴了Java,虽然方便了Javascript的入门,但要深入理 ...
- spring技术核心概念纪要
一.背景 springframework 从最初的2.5版本发展至今,期间已经发生了非常多的修正及优化.许多新特性及模块的出现,使得整个框架体系显得越趋庞大,同时也带来了学习及理解上的困难. 本文阐述 ...
随机推荐
- 基于SqlSugar的开发框架循序渐进介绍(3)-- 实现代码生成工具Database2Sharp的整合开发
我喜欢在一个项目开发模式成熟的时候,使用代码生成工具Database2Sharp来配套相关的代码生成,对于我介绍的基于SqlSugar的开发框架,从整体架构确定下来后,我就着手为它们量身定做相关的代码 ...
- 基于 Jenkins + Kubernetes + Argo CD 的完整 DevOps 流程记录(1) - 环境部署
一.环境准备 1.1 镜像仓库 整套 DevOps 流程使用 Harbor 作为内部镜像仓库,所有构建产物(镜像)都会推送到 Harbor,以备后续进行项目部署.Harbor 从 2.x 版本开始支持 ...
- 147_Power BI Report Server demo演示
焦棚子的文章目录 服务器地址:http://pbirs.jiaopengzi.com/reports 用户名:pbirs 密码:pbirs 分别用pc网页.pc桌面power bi软件以及手机端pow ...
- 116_Power Pivot 先进先出原则库龄库存计算相关
博客:www.jiaopengzi.com 焦棚子的文章目录 请点击下载附件 一背景 前面写过了一个关于进销存的案例,留一个话题就是先进先出的库存计算. 刚好有朋友提了相关这样的需求.先来看看效果. ...
- 「NOI2019」序列
NKOJ卡常卡不过QAQ description 给两个A,B序列,让你分别在A,B中各选k个数,其中至少有L对下标相等. Solution 把问题转化为至多选n-K对下标不同的对. 配对问题就用费用 ...
- 关于『进击的Markdown』:第五弹
关于『进击的Markdown』:第五弹 建议缩放90%食用 路漫漫其修远兮,吾将上下而求索. 我们要接受Mermaid的考验了呢 Markdown 语法真香(一如既往地安利) ( 进击吧!Mark ...
- 关于『HTML』:第三弹
关于『HTML』:第三弹 建议缩放90%食用 盼望着, 盼望着, 第三弹来了, HTML基础系列完结了!! 一切都像刚睡醒的样子(包括我), 欣欣然张开了眼(我没有) 敬请期待Markdown语法系列 ...
- Jmeter接口参数化<自动化>(csv文件)管理测试用例以及断言
1.创建相关线程组(不解释) 2.创建相应的请求(在请求中设置变量) 下面截图中①②③④⑤⑥⑦皆可以设置为变量 3.新建CSV文件 将请求中设置的变量为明确了解每个字段的含义(皆可以将变量填写到列表的 ...
- 1. 时序练习(广告渠道vs销量预测)
用散点图来看下sales销量与哪一维度更相关. 和目标销量的关系的话,那么这就是多元线性回归问题了. 上面把所有的200个数据集都用来训练了,现在把数据集拆分一下,分成训练集合测试集,再进行训练. 可 ...
- ngx_http_fastcgi_module 的那些事
是什么? 顾名思义,是Nginx用来处理FastCGI的模块.FastCGI是什么?这个以后再讲,可以说的是现在LNMP架构里面,PHP一般是以PHP-CGI的形式在运行,它就是一种FastCGI,我 ...