记一次 MySQL 主从同步异常的排查记录,百转千回
你好,我是悟空。
这是悟空的第 183 篇原创文章
官网:www.passjava.cn
本文主要内容如下:
一、现象
最近项目的测试环境遇到一个主备同步的问题:
备库的同步线程停止了,无法同步主库的数据更改。
备库报错如下:
完整的错误信息:
Relay log read failure: Could not parse relay log event entry. The possible reasons are: the master's binary log is corrupted (you can check this by running 'mysqlbinlog' on the binary log), the slave's relay log is corrupted (you can check this by running 'mysqlbinlog' on the relay log), a network problem, or a bug in the master's or slave's MySQL code. If you want to check the master's binary log or slave's relay log, you will be able to know their names by issuing 'SHOW SLAVE STATUS' on this slave.
上面的报错信息是什么意思呢?
翻译一下就是主库的 binlog 或者从库的 relay log 损坏了,造成这个问题的原因:
- 可能是网络问题。
- 也可能是主库或备库的代码 bug。
首先我们还是得复习下主从同步的原理才能更好地分析原因。
二、主从同步的原理
首先我们还是得复习下主从同步的原理才能更好地分析原因。
- 从库会生成两个线程,一个 I/O 线程,名字叫做 Slave_IO_Running,另外一个是 SQL 线程,名字叫做 Slave_SQL_Running;
- 从库的 I/O 线程会去请求主库的 binlog 日志文件,并将得到的 binlog 日志文件写到本地的 relay-log (中继日志)文件中;
- 主库会生成一个 dump 线程,用来给从库 I/O 线程传 binlog;
- 从库 SQL 线程,会读取 relay log 文件中的日志,并解析成 SQL 语句逐一执行。
三、排查思路
3.1 分析从库的同步状态
我们可以打印下从库的同步状态,看到如下几个关键信息:
Master_Log_File: mysql-bin.000956,代表从库读到的主库的 binlog file,
Read_Master_Log_Pos: 528071913,代表从库读到的主库的 binlog file 的日志偏移量
Relay_Log_File: relay-bin.000094,代表从库执行到了哪一个 relay log
Relay_Log_Pos: 123408769,代表从库执行的 relay log file 的日志偏移量
Relay_Master_Log_File: mysql-bin.000955,代表从库已经重放到了主库的哪个 binlog file。
Exec_Master_Log_Pos: 123408556,代表从库已经重放到了主库 binlog file 的偏移量。
Slave_IO_Running: Yes,说明 I/O 线程正在运行,可以正常获取 binlog 并生成 relay log。
Slave_SQL_Running: No,说明 SQL 线程已经停止运行,不能正常解析 relay log,也就不能执行主库上已经执行的命令。
Master_Log_File 和 Read_Master_Log_Pos 这两个参数合起来表示的是读到的主库的最新位点。
Relay_Master_Log_File 和 Exec_Master_Log_Pos,这两个参数合起来表示的是从库执行的最新位点。
如果红色框起来的两个参数:Master_Log_File 和 Relay_Master_Log_File 相等,则说明从库读到的最新文件和主库上生成的文件相同,这里前者是 mysql-bin.000956,后者是 mysql-bin.000955,说明两者不相同,存在主从不同步。
如果蓝色框起来的两个参数 Read_Master_Log_Pos 和 Exec_Master_Log_Pos 相等,则说明从库读到的日志文件的位置和从库上执行日志文件的位置相同,这里不相等,说明主从不同步。
当上面两组参数都相等时,则说明主从同步正常,且没有延迟。只要有任意一组不相等,则说明主从不同步,可能是从库停止同步了,或者从库存在同步延迟。由于上面的 SQL 线程已经停止了,说明是从库同步出现问题了。
从库同步出现的问题在最开始的报错信息里面已经提到了,可能是网络问题导致,还有可能是 binlog 或 relay log 损坏。
3.2 重启万能大法
先通过重启来恢复从库的 SQL 线程试试看?重启方式就是两种:
- 方式一:从库重新开启同步。就是执行 stop slave; 和 start slave; 命令。
- 方式二:重启从库实例。就是重启 mysql 实例或 mysql 容器。
这两种方式试了后,都不能恢复从库的 SQL 线程。
3.3 查看 binlog
再来看下 binlog 是否有损坏,在主库上通过这个命令打开 mysql-bin.000955 文件。
mysqlbinlog /var/lib/mysql/log/mysql-bin.000955
没有报错信息,如下图所示:
3.4 查看 relay log
看到从库同步的 Relay_Log_File 到 relay-bin.00094 就停止同步了,如下图所示,可能是这个文件损坏了。
在从库上通过 mysqlbinlog 命令打开这个文件
mysqlbinlog /var/lib/mysql/log/relay-bin.000094
可以看到有个报错信息:
ERROR: Error in Log_event::read_log_event(): 'read error', data_len: 7644, event_type: 31
ERROR: Could not read entry at offset 243899899: Error in log format or read error.
这段文字翻译过来就是读取错误,数据长度 7644,在读取偏移量为 243899899 的日志时发生了错误,可能是日志文件格式错误或是读取文件错误。
3.5 找原因
3.5.1 猜测事务日志太大
根据这个报错信息可以知道这个事务日志数据太长了,data_len: 7644,而导致读取错误。
而且上面还有很多 Update_rows 的操作。
猜测:会不会是主库执行了一个大事务,造成该事务生成的一条 binlog 日志太大了,从库生成的对应的一条 relay log 日志也很大, SQL 线程去解析这条 relay log 日志解析报错。
3.5.2 验证
到主库上查看下 binlog 日志里面有没有在那个时间点做特殊操作。
感觉快找到原因了。执行以下命令来查看
mysqlbinlog File --stop-datetime=T --start-datetime=T
stop-datetime 指定为读取 relay log 报错的时刻 2023-04-04 16:47:16,
start-datetime 指定为读取 relay log 报错的时刻 2023-04-04 16:47:30。
发现并没有找到 Update_rows 的操作。继续把时间往后加一点,经过多次尝试,把时间锁定在了 2023-04-04 17:00:30~17:00:31。这 1s 内能找到 2023-04-04 16:47:16 的操作日志。
日志如下,这个命令会打印 N 多日志,直接把屏幕打满了!!
难道真的 binlog 对应的这条事务日志太大了吗???
存疑: 2023-04-04 16:47:16 时刻对数据库中的表做了某个大事务的操作,造成该事务对应的这条 binlog 日志很大很大。生成的 relay log 也很大,SQL 线程解析 relay log 报错。
3.6 这是真相吗?
问了下熟悉这张表的同事,有没有在这个时刻做什么大事务操作。
同事看了下代码,发现有个批量插入的操作,一次执行 400 条,难道是 400 条太多了???这不应该是真正的原因,400 条也不多。
不经意间问了下这张表的数据量有多大,该同事在 4月4号 16:45:25 做了一个手动备份 xx_dance 表的操作,这张表有 25 万条数据。
这个备份操作是在一个事务里面执行的,生成的一条 binlog 日志很大。
这里只是一个猜测,还未得到验证,文末会说明真正的原因。
如果真的是这样,那我可以先恢复从库的同步,备份表的操作在从库上其实不需要。
3.7 GTID
不知道细心的你是否有发现上面的 binlog 里面有一个GTID,
'c5d74746-d7ec-11ec-bf8f-0242ac110002:8634832
记住 GTID 中的数字 8634832,后面恢复从库同步时要用到。
我们再来看下从库的状态,发现也有一个 GTID,如下图所示,值为 8634831,正好相差 1,感觉这两个 GTID 值之间有不可告人的秘密。
那么从库 SQL 线程停止运行的原因就是卡在 8634832 这里了,我们可否跳过这个 GTID 呢?
你可能对 GTID 的原理很感兴趣,可以查看之前悟空写的一篇文章:
四、GTID 同步方式的原理
这里还是把主从同步采用 GTID 方式的流程拿出来看下,帮助大家快速回顾下,熟悉的同学可以跳过本节内容。
GTID 方案:主库计算主库 GTID 集合和从库 GTID 的集合的差集,然后主库推送差集 binlog 给从库。
当从库设置完同步参数后,假定主库 A 的GTID 集合记为集合 x,从库 B 的 GTID 集合记为 y。
从库同步的逻辑如下:
- 从库 B 指定主库 A,基于主备协议建立连接。
- 从库 B 把集合 y 发给主库 A。
- 主库 A 计算出集合 x 和集合 y 的差集,也就是集合 x 中存在,集合 y 中不存在的 GTID 集合。比如集合 x 是 1~100,集合 y 是 1~90,那么这个差集就是 91~100。这里会判断集合 x 是不是包含有集合 y 的所有 GTID,如果不是则说明主库 A 删除了从库 B 需要的 binlog,主库 A 直接返回错误。
- 主库 A 从自己的 binlog 文件里面,找到第一个不在集合 y 中的事务 GTID,也就是找到了 91。
- 主库 A 从 GTID = 91 的事务开始,往后读 binlog 文件,按顺序取 binlog,然后发给 B。
- 从库 B 的 I/O 线程读取 binlog 文件生成 relay log,SQL 线程解析 relay log,然后执行 SQL 语句。
GTID 同步方案和位点同步的方案区别是:
- 位点同步方案是通过人工在从库上指定哪个位点,主库就发哪个位点,不做日志的完整性判断。
- 而 GTID 方案是通过主库来自动计算位点的,不需要人工去设置位点,对运维人员友好。
五、恢复从库的同步
5.1 查看从库执行 GTID 的进度
在从库上执行 show slave status \G来查看 GTID 集合。
Retrieved_Gtid_Set 表示从库收到的所有日志的 GTID 集合。
Executed_Gtid_Set 表示从库已经执行完成的 GTID 集合。
如果 Executed_Gtid_Set 集合是包含 Retrieved_Gtid_Set,则表示从库接收到的日志已经同步完成。
这里 Executed_Gtid_Set 的集合为 1-8634831,而 Retrieved_Gtid_Set 为 1-9101426,说明从库有些 GTID 是没有执行的。从库已经执行到了 8634831,下一个要执行的 GTID 为 8634832。
因为我们采用的同步方式是 GTID 方式,所以只要让从库跳过这个 GTID ,从下一个 GTID 开始同步就行。
带来的问题就是这个 GTID 对应的事务没有执行。因为报错的操作是从库备份一张大表,所以从库跳过这个备份操作也是可以接受的。
5.2 手动设置 GTID
来,手动设置一把 GTID 试下。
5.2.1 重置从库进度
首先重置下从库同步的进度,这条命令会把 relog 给清理掉,不过重新开启同步后,主库会计算主库 GTID 集合和从库 GTID 的集合的差集,然后主库推送差集 binlog 给从库。
stop slave;
reset slave;
5.2.1 设置 GTID 为一个值
执行以下命令设置 GTID 为下一个值。
set gtid_next='c5d74746-d7ec-11ec-bf8f-0242ac110002:8634832';
begin;
commit;
set gtid_next=automatic;
start slave;
gtid_next 表示设置下一个 GTID = 8634832,这个值是在原来的 8634831 加 1。后面的 begin 和 commit 是提交了一个空事务,把这个 GTID 加到从库的 GTID 集合中。那么从库的 GTID 集合就变成了
'c5d74746-d7ec-11ec-bf8f-0242ac110002:1-8634832';
5.2.2 查看当前 GTID 集合
我们可以通过 show master status\G 命令来查看从库的 GTID 集合。下方截图是执行上述命令之前的。GTID集合为 1-8634831。另外 GTID 集合 为 1 和 GTID 集合为 1-4 的可以忽略,因为它们前面的 Master_UUID 不是当前主库的 uuid。
也可以通过 show slave status\G 命令来查看 GTID 集合,结果也是一样的。
5.3 开启从库同步
再次启动从库的同步(start slave 命令),I/O 线程和 SQL 线程的状态都为 YES,说明启动成功了。
而且查看从库的同步状态时,观察到从库的同步是存在延迟的。通过观察这个字段 Seconds_Behind_Master 在不断减小,说明主从同步的延迟越来越小了。
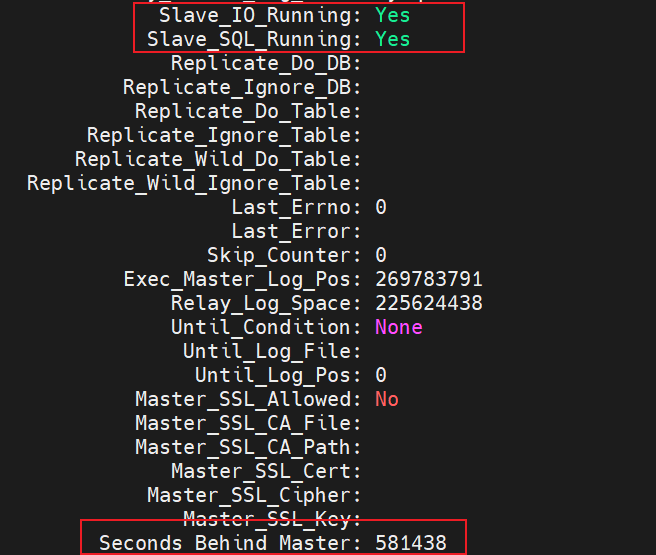
过一段时间后,执行的 GTID 等于收到的 GTID 集合,Seconds_Behind_Master = 0,说明主从完全同步了。
六、原因
上面的推测:* *备份大表造成 binlog 的一条日志太大,relay log 也跟着变大,SQL 线程无法正常解析**。
但这是真相吗?
虽然从库重新开启了同步,且跳过了这条日志,但带来的是从库上就不会出现这个备用表 xx_dance_0404 。
但出现了两个奇怪的问题:
问题 1:从库开启同步后,居然出现了这个备份表 xx_dance_0404。不是跳过这个备份操作了吗?目前没想到原因。
问题 2:为了重现这个问题,我到主库上做了一个备份表的操作,表名为 xx_dance_0412,从库也同步了这个新的备份表 xx_dance_0412。而且 binlog 出现的日志现象也是一样的,对应的这条 binlog 日志也很大,但是从库同步正常。我又备份了一张 300 万的大表,依然没重现。
通过问题 2 可以说明上面的推测是错误的,备份大表并不会影响主从同步。
那么 relay log 报错的原因是什么?
只有一个原因了,relay log 文件真的是损坏的,从库的状态上也说明了原因,relay log is corrupted(损坏)。SQL 线程去解析 relay log 时报错了,导致 SQL 线程停止,从库不能正常执行同步。
小结: relay log 损坏了,导致从库的 SQL 线程解析 relay log 时出现异常。从库恢复方式是通过手动设置当时出错的 GTID 的下一个值,让从库不从主库同步这个 GTID,最后从库就能正常同步这个 GTID 之后的 binlog 了,后续 SQL 线程也能正常解析 relay log 了。
如果你对上面的排查思路、结论、恢复方式有其他想法,欢迎拍砖!
- END -
记一次 MySQL 主从同步异常的排查记录,百转千回的更多相关文章
- MySQL主从同步异常问题解决Client requested master to start replication from position > file size
MySQL主从同步异常问题解决Client requested master to start replication from position > file size 一.问题描述 MySQ ...
- mysql主从同步异常原因及恢复
mysql主从同步异常原因及恢复 前言 mysql数据库做主从复制,不仅可以为数据库的数据做实时备份,保证数据的完整性,还能做为读写分离,提升数据库的整体性能.但是,mysql主从复制经常会因为某些原 ...
- 记一次mysql主从同步因断电产生的不能同步问题 1236 1032
背景: 项目新上线一个月,qa需要测试断电服务拉起,服务拉起成功后,发现mysql主从异常,以下是发现的问题以及解决方案 问题1: Slave_IO_Running: No 一方面原因是因为网络通信 ...
- Mysql主从同步 异常Slave_SQL_Running: No
在刚搭建好的mysql主从节点上对从节点进行操作,导致同步异常:报错如下: 从节点执行: mysql> show slave status\G;************************* ...
- mysql主从同步单个表实验记录
问题的提出: 在CRM管理系统与运营基础数据平台之间需要有数据表进行交换,说是交换,其实是单向的,就是CRM里面的一些数据需要实时同步到运营基础数据平台中. 解决方案: A.采用时间戳的办法进行代码开 ...
- MySQL主从同步报错故障处理记录
从库上记录删除失败,Error_code: 1032 问题描述:在master上删除一条记录,而slave上找不到,导致报错 Last_SQL_Error: Could not execute Del ...
- 监控mysql主从同步状态是否异常
监控mysql主从同步状态是否异常,如果异常,则发生短信或邮寄给管理员 标签:监控mysql主从同步状态是否异常 阶段1:开发一个守护进程脚本每30秒实现检测一次. 阶段2:如果同步出现如下错误号(1 ...
- 运维派 企业面试题1 监控MySQL主从同步是否异常
Linux运维必会的实战编程笔试题(19题) 企业面试题1:(生产实战案例):监控MySQL主从同步是否异常,如果异常,则发送短信或者邮件给管理员.提示:如果没主从同步环境,可以用下面文本放到文件里读 ...
- MySQL主从同步、读写分离配置步骤、问题解决笔记
MySQL主从同步.读写分离配置步骤.问题解决笔记 根据要求配置MySQL主从备份.读写分离,结合网上的文档,对搭建的步骤和出现的问题以及解决的过程做了如下笔记: 现在使用的两台服务器已经 ...
- zabbix3.0.4监控mysql主从同步
zabbix3.0.4监控mysql主从同步 1.监控mysql主从同步原理: 执行一个命令 mysql -u zabbix -pzabbix -e 'show slave status\G' 我们在 ...
随机推荐
- window10下,命令行与端口
netstat -ano 查看端口情况 tasklist|findstr "9220" 通过PID号"9220"查看对应端口被什么进程占用了 netstat - ...
- java的内存模型,jmm理解和(GC)垃圾回收时机。
jmm模型中的gc处理是在堆中回收. 1.新对象出来以后,先尝试在eden中放下,放不下的时候,进行一次ygc,只会在eden中回收,
- SQL Server 启用“锁定内存页”
这次在虚拟机中做了一个模拟器做压力测试,简单模拟了一条20个工位的生产线上生产1000个工件,并向 MES 服务端发起功能请求,保存质量数据和扫码数据到数据库.在测试时发现服务端进程的 CPU 占用有 ...
- 归纳了一下AD的快捷键
1:shift+s 键 切换单层显示 2:q 英寸和毫米 尺寸切换3:D+R进入布线规则设置.其中 Clearance 是设置最小安全线间距,覆铜时候间距的.比较常用4:CTRL+鼠标单击某个 ...
- Ensemble learning A survey 论文阅读
Ensemble learning A survey是2018年发表的一篇关于集成学习的综述性论文 发展 在Surowiecki的书中The Wisdom of Crowds,当符合以下标准时,大众的 ...
- 【技术指北】通过SMB协议在iOS和Windows之间传输文件
windows操作 新建文件夹 设置文件夹的属性,选择共享 设置高级共享,权限选择完全控制 选择共享,选择Everyone cmd - ipcofig,获取ipv4地址 iOS操作 打开文件管理器 选 ...
- 修改word文档中已有的批注者名称
前言 https://blog.csdn.net/hyh19962008/article/details/89430548 word中可以通过修改用户的信息实现新建的批注者显示不同的名称,但是对于文档 ...
- python pip安装三方库失败
Collecting pip WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None ...
- Vue-router 中hash模式和history模式的关系
Vue-router 中hash模式和history模式的关系 众所周知,vue+vue-router能够构建一个SPA单页面应用, 打包后只会生成一个index.html文件,而项目内页面的切换其实 ...
- 2021.06.29 mac系统下zsh: command not found:***报错问题
最近老是遇到zsh: command not found:vue,zsh: command not found:nrm, zsh: command not found:tsc, zsh: comman ...