3行python代码翻译70种语言,这个OCR神奇太赞了
写在前面的一些P话:
今天给大家介绍一个超级简单且强大的OCR文本识别工具:easyocr.
这个模块支持70多种语言的即用型OCR,包括中文,日文,韩文和泰文等。
完全满足了大家对于语言的要求,不管你说的是中文、外文,还是鸟语,统统都给你拿下。(不是)
废话不多说,下面是这个模块的实战教程。
1.准备
请选择以下任一种方式输入命令安装依赖:
Windows 环境 打开 Cmd (开始-运行-CMD)。
MacOS 环境 打开 Terminal (command+空格输入Terminal)。
如果你用的是 VSCode编辑器 或 Pycharm,可以直接使用界面下方的Terminal.
pip install easyocr
它会安装除了模型文件之外的所有依赖,模型文件则会在运行代码的时候下载。
对于Windows,如果在安装 Torch 或 Torchvision 时报错了,请按照https://pytorch.org 的官方说明安装 Torch 和Torchvision。
如果你想使用显卡进行计算,你需要搜索下载CUDA,并在Pytorch网站上,确保选择正确的CUDA版本。如果仅打算在CPU模式下运行,请选择CUDA = None。
2.实战教程
这个模块用起来真的非常简单,三行代码完事了:
Python学习交流Q群:660193417####
import easyocr
reader = easyocr.Reader(['ch_sim','en'])
result = reader.readtext('test.png')
运行的过程中会安装所需要的模型文件,像下面这样:
不过它的下载速度非常慢,而且经常会失败,因此这里给出第二个解决方案:先下载好模型文件,再将其放置到所需要的位置
文字检测模型(CRAFT)(必须)
https://pythondict.com/go/?
url=https://github.com/JaidedAI/EasyOCR/releases/download/pre-
v1.1.6/craft_mlt_25k.zip
中文(简体)模型(识别中文必须)
https://pythondict.com/go/
url=https://github.com/JaidedAI/EasyOCR/releases/download/pre-
v1.1.6/chinese_sim.zip
中国(传统)模型
https://pythondict.com/go/?
url=https://github.com/JaidedAI/EasyOCR/releases/download/pre-
v1.1.6/chinese.zip
拉丁模型
https://pythondict.com/go/?
url=https://github.com/JaidedAI/EasyOCR/releases/download/pre-
v1.1.6/latin.zip
日本模型
https://pythondict.com/go/?
url=https://github.com/JaidedAI/EasyOCR/releases/download/pre-
v1.1.6/japanese.zip
韩文模型
https://pythondict.com/go/?
url=https://github.com/JaidedAI/EasyOCR/releases/download/pre-
v1.1.6/korean.zip
泰文模型
https://pythondict.com/go/?
url=https://github.com/JaidedAI/EasyOCR/releases/download/pre-
v1.1.6/thai.zip
阿拉伯文模型
https://pythondict.com/go/?
url=https://github.com/JaidedAI/EasyOCR/releases/download/pre-
v1.1.6/arabic.zip
下载完模型后,将文件放到下面这个位置。
Windows:C:\Users\用户名.EasyOCR\model
Linux:~/ .EasyOCR / model
如下图所示:
重新执行脚本不会再提醒下载模型了:
import easyocr
reader = easyocr.Reader(['ch_sim'])
result = reader.readtext('test.png')
print(result)
我随便截了一个直播弹幕的图片保存在脚本所在的文件夹下,命名为test.png:
结果如下:
基本上所有应该识别的文字都识别出来了,效果非常不错。
另外也可以看到,输出采用列表格式,每个item分别表示对应文字的边界框,识别文本结果和置信度。
这个模块还能识别多语种的情况:
我将这张图片命名为test2.jpg,修改代码中对应的图片名称:
import easyocr
reader = easyocr.Reader(['ch_sim','en'])
result = reader.readtext('test2.jpg')
print(result)
效果如下: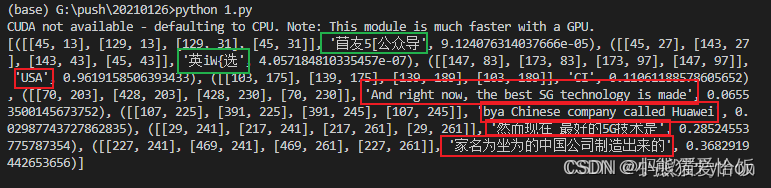
这张图片很复杂,而且是中英文混杂在一起的情况,但是可以看到模型除了左上角的水印,图片中的文字基本都是识别出来了,尽管有部分文字识别错误,但还在可以接受的范围之内。
不过需要注意的是,虽然可以一次性识别许多种语言,但并非所有语言都可以一起用,通常是公共语言和一个特殊语种可以一起识别,相互兼容,比如英语和日语。
如果你的电脑没有GPU或者显存不足,可以加一个gpu=false的参数仅使用CPU运行:
reader = easyocr.Reader(['ch_sim','en'], gpu = False)
另外,这个模块还支持直接使用命令行运行,相当方便,大家可以试试:
easyocr -l ch_sim en -f test.png --detail=1 --gpu=True
最后
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注我们!记得给个三连哦!
3行python代码翻译70种语言,这个OCR神奇太赞了的更多相关文章
- 100行Python代码实现一款高精度免费OCR工具
近期Github开源了一款基于Python开发.名为 Textshot 的截图工具,刚开源不到半个月已经500+Star. 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语 ...
- 一个 11 行 Python 代码实现的神经网络
一个 11 行 Python 代码实现的神经网络 2015/12/02 · 实践项目 · 15 评论· 神经网络 分享到:18 本文由 伯乐在线 - 耶鲁怕冷 翻译,Namco 校稿.未经许可,禁止转 ...
- 200行Python代码实现2048
200行Python代码实现2048 一.实验说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌面 ...
- 30行Python代码实现人脸检测
参考OpenCV自带的例子,30行Python代码实现人脸检测,不得不说,Python这个语言的优势太明显了,几乎把所有复杂的细节都屏蔽了,虽然效率较差,不过在调用OpenCV的模块时,因为模块都是C ...
- 21行python代码实现拼写检查器
引入 大家在使用谷歌或者百度搜索时,输入搜索内容时,谷歌总是能提供很好的拼写检查,比方你输入 speling,谷歌会立即返回 spelling. 前几天,看到http://norvig.com/spe ...
- vim中凝视多行python代码
在vim中凝视多行python代码比較麻烦,主要由下面几种方法: (1)将须要凝视的代码以文档字符串的形式呈现 (2)将须要凝视的代码以函数的形式呈现 (3)使用vim自身快捷键 我们主要使用第三种方 ...
- 几行python代码解决相关词联想
日常生活中经常会遇到相关词联想的问题,也就是说输入一个词汇,把相关的词汇查询出来,听起来这个做法也不是太难,但如何去积累那么多的词汇,再用好的算法将相关内容联系起来,本身还是不简单的.笔者认为最简单的 ...
- 转-Pycharm中运行Python代码的几种方式
转自:Pycharm中运行Python代码的几种方式 在pycharm中的Python代码运行会出现各种奇葩的问题,比如,密码输入时不显示或没有提示,给我们带来一些麻烦,下面介绍几种代码运行的几种方式 ...
- 将python代码转化为c语言代码,提高运行效率
将python代码转化为c语言代码,提高运行效率 首先,需要安装cpython库: pip install cython 安装完成之后,写一段简单的代码,例如下面这个利用递归求斐波那契数列的函数,然后 ...
随机推荐
- gin框架使用【4.请求参数】
GET url: http://127.0.0.1:8080/users?id=1&name=卷毛狒狒 package mainimport ( "github.com/gin-go ...
- EMC信号完整性落地实测1---走出玄学
EMC信号完整性落地实测1---走出玄学 无论我们从51单片机,STM32电路,运放,传感器,ADC采集还是可控硅晶闸管等等电源电路跨入到电子工程师的行业,我们通常会长时间处于低频的电子电路设计调试阶 ...
- 2021.12.09 [HEOI2016/TJOI2016]排序(线段树+二分,把一个序列转换为01串)
2021.12.09 [HEOI2016/TJOI2016]排序(线段树+二分,把一个序列转换为01串) https://www.luogu.com.cn/problem/P2824 题意: 在 20 ...
- 五分钟配置 MinGW-W64 编译工具
编译器是一个诸如 C 语言撰写的源程序一步一步走向机器世界彼岸的桥梁. Gnu 项目的 GCC 编译器是常用的编译器之一.儿在Windows 上也有 MinGW 这样可用的套件,可以让我们使用 GCC ...
- Em 和 Rem 的基本使用
1. Em html 结构 <div id="box-1"> <h3>Box One</h3> <p> Lorem ipsum do ...
- Revit二次开发之添加选项卡和按钮
我们日常在revit开发中经常会用到按钮,可以通过revitAPI提供的接口创建按钮,今天我简单介绍一下两种按钮,一种是单命令按钮,另一种是含下拉菜单的按钮,包括创建他们的方法. 实现方法 1.实 ...
- 网络协议之:Domain name service DNS详解
目录 简介 DNS的功能 DNS的组成 域名空间Domain name space Name servers DNS的工作流程 DNS资源记录 DNS消息的结构 总结 简介 现在是互联网的世界,大家从 ...
- MybatisCodeHelperPro简单使用
1.idea安装 2.连接mysql 3.创建实体等关联类 ,选择数据库表右键选择如图 4配置 生成后的 5简单应用 可以直接生成xml 总结:非常的方便快捷.
- 1.6 为什么要学Linux,它比Windows好在哪里?
早在 20 世纪 70 年代,UNIX 系统是开源而且免费的,但是在 1979 年时,AT&T 公司宣布了对 UNIX 系统的商业化计划,随之开源软件业转变成了版权式软件产业,源代码被当作商业 ...
- 不再空谈AI,从打造一台智能无人机开始
对于大多数无人机爱好者来说,能自己从头开始组装一台无人机,之后加入AI算法,能够航拍,可以目标跟踪,是心中的梦想. 并且,亲自从零开始完成复杂系统,这是掌握核心技术的必经之路. 开课吧特邀北京航空航天 ...