分析document文档中script标签获取抖音无水印视频
思路分析
- 使用 playwright 模拟浏览器打开分享链接
- 获取 播放页面 html 信息
- 解析 播放页面的 video标签,video标签的src属性就是视频的地址
- 这种模式会触发抖音的风控机制
- 解析页面 获取相关cookie
- 使用cookie请求页面文档
- 解析文档内容其中就有播放地址
playwright 入门使用介绍
简单使用如下。这种模式会触发抖音的风控机制,出现验证码中间页。

# 抖音分享链接
share_url = 'https://v.douyin.com/SGGxvfM/'
# 创建浏览器打开分享地址
# 因为可能会触发抖音的风控机制,所以这里先设置为有头模式,当触发验证码中间页时,手动处理下
browser = sync_playwright().start().chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto(share_url)
# 获取标签及视频播放地址
page.wait_for_load_state()
video = page.wait_for_selector('video')
print(video)
source = video.query_selector_all('source')
video_src = source[0].get_attribute("src")
video_src = 'https:' + video_src
print(video_src)
file_name = 'result.mp4'
print('开始下载视频...')
response = requests.get(video_src, stream=True)
with open(file_name, "wb") as file:
file.write(response.content)
print('下载完成')
另辟出路
因为会触发中间验证页,虽然也可以使用 playwright 处理验证码,但是速度慢,同时验证方式更改就得更改总之不好。
背景信息
分享短链地址 :https://v.douyin.com/SGGxvfM/
重定向后的实际地址:https://www.douyin.com/video/7210719593298464003
流程:抖音的短链经过重定向后才会得到实际地址
中间过程就会拿到服务器写回的cookie信息
实际地址的请求是个document类型的内容,重点来了:document里的script标签的ID是RENDER_DATA,type是application/json,把标签里内容解码一下果然是我们想要的内容。
截图如下

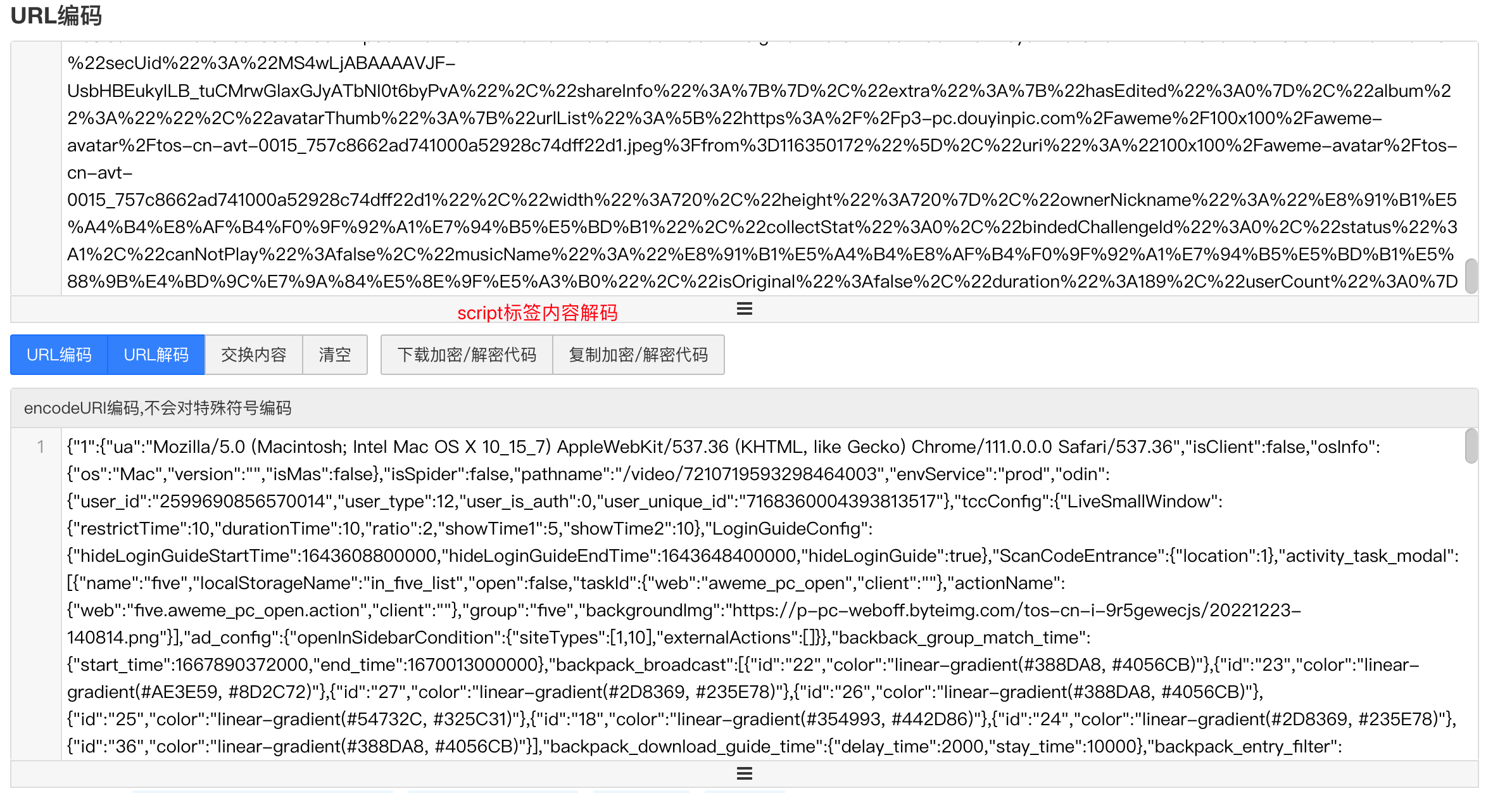

处理逻辑
有了上面的背景信息,那处理逻辑也很简单了。
- 使用 playwright 进行打开分享地址
- 获取cookie信息
- 请求实际地址内容
- 获取script标签内容
- 解析script标签内容里json信息并获取相关字段
import json
import re
import requests
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
from urllib.parse import unquote
share_url = 'https://v.douyin.com/SGGxvfM/'
browser = sync_playwright().start().chromium.launch(headless=True)
context = browser.new_context()
page = context.new_page()
page.goto(share_url)
cookies = page.context.cookies()
result_cookie = ''
for item in cookies:
if item['name'] == '__ac_nonce':
# document_header['__ac_nonce'] = item['value']
result_cookie = result_cookie + '__ac_nonce=' + item['value'] + ';'
if item['name'] == '__ac_signature':
result_cookie = result_cookie + '__ac_signature=' + item['value'] + ';'
document_header = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-ch-ua-platform': 'macOS',
'sec-ch-ua': '"Google Chrome";v="111", "Not(A:Brand";v="8", "Chromium";v="111"',
'sec-ch-ua-mobile': '?0',
'upgrade-insecure-requests': '1',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'cookie': result_cookie
}
# print(page.url)
url = page.url
# url = 'https://www.iesdouyin.com/share/video/7210719593298464003/?region=CN&mid=7210720503894805308&u_code=33j73e481hda&did=MS4wLjABAAAAyWxE53gU-qg10uh4jIbo0XpO2_I8z5fpPlI_pBAlio7gocacNdKp0p4KSAydSgC_&iid=MS4wLjABAAAALt7iss0DroHh-NMLV6ZFi-4uYP-lTU-NqsBOH3GQxng6bxW6xVoJ7AHXunv0YjHv&with_sec_did=1&titleType=title&from_ssr=1×tamp=1678941771&utm_campaign=client_share&app=aweme&utm_medium=ios&tt_from=copy&utm_source=copy'
search_result = re.search('https://www.iesdouyin.com/share/video/(.+?)/', url)
video_id = search_result.group(1)
video_url = 'https://www.douyin.com/video/' + video_id + '?previous_page=app_code_link'
video_detail_response = requests.get(video_url, headers=document_header)
soup = BeautifulSoup(video_detail_response.text)
encode_data = soup.find('script', {'id': 'RENDER_DATA'}).get_text()
decode_data = unquote(encode_data)
decode_data = json.loads(decode_data)
video_url = decode_data['44']['aweme']['detail']['video']['playAddr'][0]['src']
video_src = 'https:' + video_url
print(video_src)
file_name = 'result.mp4'
print('开始下载视频...')
response = requests.get(video_src, stream=True)
with open(file_name, "wb") as file:
file.write(response.content)
print('下载完成')
额外其他
另外包装了一个微信小程序,可以试用看看,个人带宽服务器流量有限谨慎使用。使用过程中有问题还请多多包涵反馈。

分析document文档中script标签获取抖音无水印视频的更多相关文章
- Table对象代表一个HTML表格,在文档中<table>标签每出现一次,一个table对象就会被创建。
1.对象集合 cells[] 返回包含表格中所有单元格的一个数组 rows[] 返回包含表格中所有行的一个数组 tBodies[] 返回包含表格中所有tbody的一个数组(主包含ty和td) 2.对象 ...
- 使用Python中的HTMLParser、cookielib抓取和解析网页、从HTML文档中提取链接、图像、文本、Cookies(二)(转)
对搜索引擎.文件索引.文档转换.数据检索.站点备份或迁移等应用程序来说,经常用到对网页(即HTML文件)的解析处理.事实上,通过 Python语言提供的各种模块,我们无需借助Web服务器或者Web浏览 ...
- 【python】使用HTMLParser、cookielib抓取和解析网页、从HTML文档中提取链接、图像、文本、Cookies
一.从HTML文档中提取链接 模块HTMLParser,该模块使我们能够根据HTML文档中的标签来简洁.高效地解析HTML文档. 处理HTML文档的时候,我们常常需要从其中提取出所有的链接.使用HTM ...
- Python中的HTMLParser、cookielib抓取和解析网页、从HTML文档中提取链接、图像、文本、Cookies(二)
对搜索引擎.文件索引.文档转换.数据检索.站点备份或迁移等应用程序来说,经常用到对网页(即HTML文件)的解析处理.事实上,通过 Python语言提供的各种模块,我们无需借助Web服务器或者Web浏览 ...
- [译]我们应该在HTML文档中何处放script标签
本文翻译youtube上的up主kudvenkat的javascript tutorial播放单 源地址在此: https://www.youtube.com/watch?v=PMsVM7rjupU& ...
- jquery获取元素在文档中的位置信息以及滚动条位置(转)
jquery获取元素在文档中的位置信息以及滚动条位置 http://blog.csdn.net/qq_34095777/article/details/78750886 原文链接 原创 201 ...
- javaScript获取文档中所有元素节点的个数
HTML+JS 代码: <!DOCTYPE html> <html lang="en"> <head> <meta charset=&qu ...
- Java解析word,获取文档中图片位置
前言(背景介绍): Apache POI是Apache基金会下一个开源的项目,用来处理office系列的文档,能够创建和解析word.excel.ppt格式的文档. 其中对word文档的处理有两个技术 ...
- html中如何获取元素在文档中的位置
html中如何获取元素在文档中的位置 一.总结 一句话总结: $("#elem").offset().top $("#elem").offset().left ...
- HTML span标签:用来组合文档中的行内元素
在DIV+CSS切图布局重构技术中,除了常常使用div标签外也常常使用span标签布局,通常也可以通过对span标签对象设置不同样式实现我们要的美化效果.这里主机吧主要讲的是span标签的定义和用法. ...
随机推荐
- 学PHP的第二天!
这是我学PHP的第二天,我改了一些代码,终于把我喜欢的OJ网站的默认模板给改掉了,竟然能用!!!我从来都没有这么的欣喜过,看来PHP果真是一门非常好用的编程语言,但这个OJ有些用的是python的模块 ...
- 在Unity3D中开发的Ghost Shader
SwordMaster Ghost Shader 特点 此Shader是顶点片元Shader,由本人手动编写完成 此Shader已经在移动设备真机上进行过测试,可以直接应用到您的项目中 所支持的Uni ...
- mysql零基础-1
数据库概述 为什么要使用数据库 持久化 DB:数据库 DBMS:数据库管理系统 SQL:结构化查询语言 数据库与数据库管理系统关系 数据库管理系统(DBMS)可以管理多个数据库,一般开发人员会针对每一 ...
- vs2019 debug 出现: printf is ambiguous
在vs中写c++代码时,莫名其妙出现:printf is ambiguous 的错误. 第一步,有设置std namespace 删除后再输入 using namespace std; 第二步.删除u ...
- 理解 Shell
理解 Shell shell 的父子关系 用于登录的某个虚拟控制器终端,或在 GUI 中运行终端仿真器时所启动的默认的交互 shell,是一个父 shell.本书到目前为止都是父 shell 提供 C ...
- texstudio设置外部浏览器及右侧预览不能使用问题
刚装的texstudio,今天不知什么原因右侧显示的pdf文件一直是以前的,百度了下没找到,自己摸索了下,只需要把构建里面pdf查看器更改下即可 如果想更改外部pdf查看器,只需要设置下命令里面外部p ...
- Synchronized和Lock有什么区别?用Lock有什么好处?
Synchronized 和 Lock 1.原始构成 Synchronized 是关键字属于JVM层面 (代码中以蓝色字体呈现) monitorenter .monitorexit Lock 是具体类 ...
- TRACE()宏的使用
TRACE()宏一般是用在mfc中的,用于将调试信息输出到vs的输出窗口中(这是关键), 这在使用vs作为开发工具的时候,是非常方便的. 然而在开发一般c++程序时,却貌似无法获得这样的便利,其实只要 ...
- Qt之如何创建并显示一个柱状图
创建一个简单的柱状图 第一步:创建一个QBarSet对象:QBarSet类代表条形图中的一组条形. QBarSet *set0 = new QBarSet("Jane"); QBa ...
- 如何让charles无论怎么请求都返回一个结果
1. map Local 将匹配的url映射到本地文件.这个需要首先将url右键,save Response,将原有报文保存到本地,然后映射到该文件,修改该文件即可,直接自己写费事2. ...