【深入浅出 Yarn 架构与实现】2-4 Yarn 基础库 - 状态机库
当一个服务拥有太多处理逻辑时,会导致代码结构异常的混乱,很难分辨一段逻辑是在哪个阶段发挥作用的。
这时就可以引入状态机模型,帮助代码结构变得清晰。
一、状态机库概述
一)简介
状态机由一组状态组成:
【初始状态 -> 中间状态 -> 最终状态】。
在一个状态机中,每个状态会接收一组特定的事件,根据事件类型进行处理,并转换到下一个状态。当转换到最终状态时则退出。
二)状态转换方式
状态间转换会有下面这三种类型:
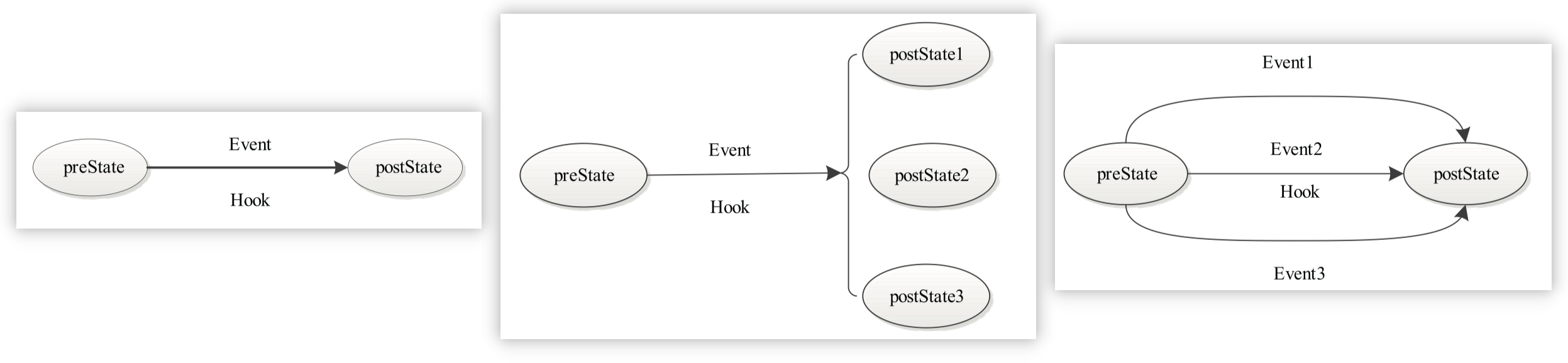
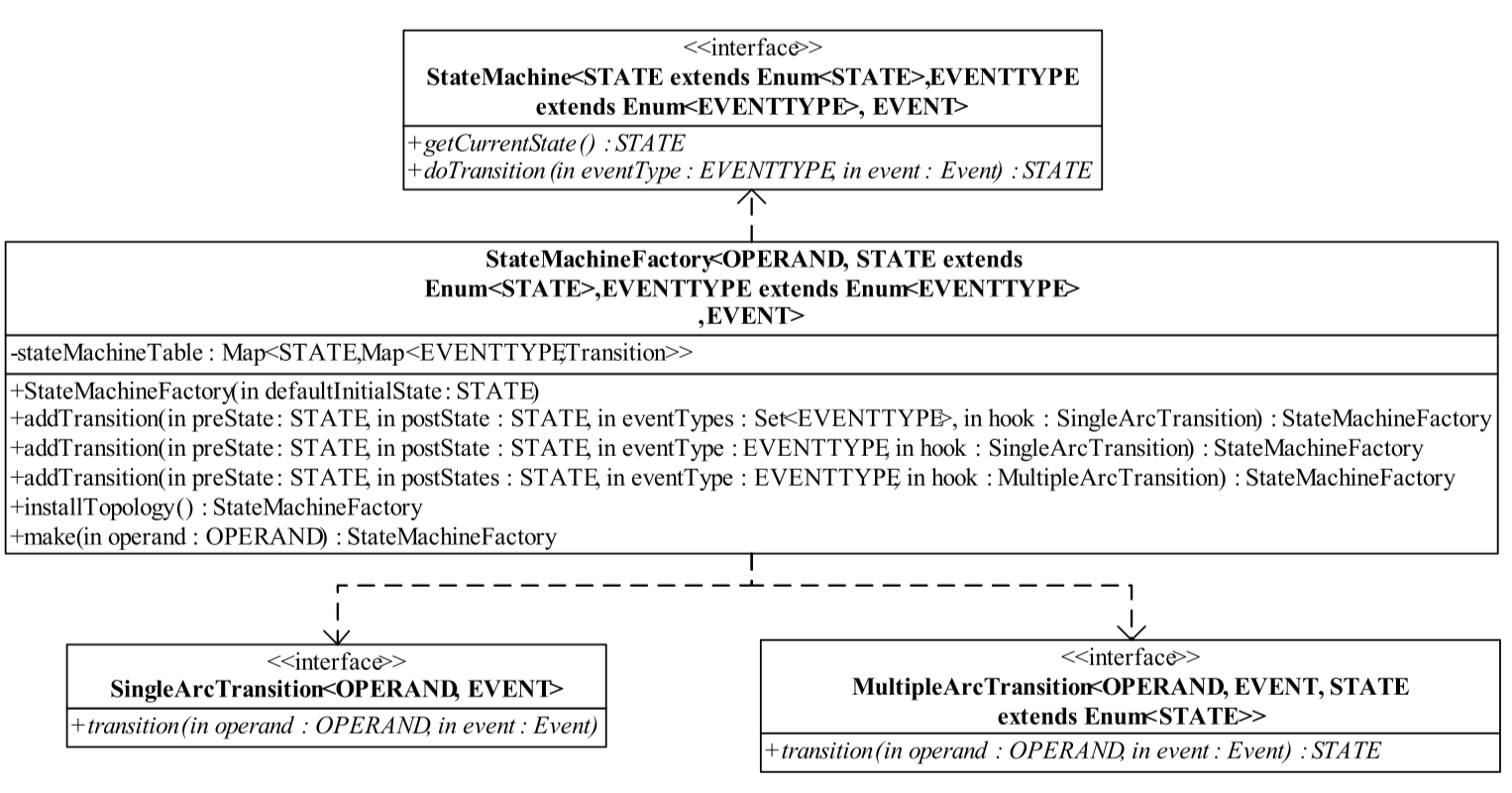
三)Yarn 状态机类
在 Yarn 中提供了一个工厂类 StateMachineFactory 来帮助定义状态机。如何使用,我们直接写个 demo。
二、案例 demo
在上一篇文章《Yarn 服务库和事件库》案例基础上进行扩展,增加状态机库的内容。如果还不了解服务库和事件库的同学,建议先学习下上一篇文章。
案例已上传至 github,有帮助可以点个 ️
https://github.com/Simon-Ace/hadoop-yarn-study-demo/tree/master/state-demo
一)状态机实现
状态机实现,可以直接嵌入到上篇文章中的 AsyncDispatcher使用。
这里仅给出状态机JobStateMachine以及各种事件处理的代码。完整的代码项目执行,请到 github demo 中查看。
import com.shuofxz.event.JobEvent;
import com.shuofxz.event.JobEventType;
import org.apache.hadoop.yarn.event.EventHandler;
import org.apache.hadoop.yarn.state.*;
import java.util.EnumSet;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/*
* 可参考 Yarn 中实现的状态机对象:
* ResourceManager 中的 RMAppImpl、RMApp- AttemptImpl、RMContainerImpl 和 RMNodeImpl,
* NodeManager 中 的 ApplicationImpl、 ContainerImpl 和 LocalizedResource,
* MRAppMaster 中的 JobImpl、TaskImpl 和 TaskAttemptImpl 等
* */
@SuppressWarnings({"rawtypes", "unchecked"})
public class JobStateMachine implements EventHandler<JobEvent> {
private final String jobID;
private EventHandler eventHandler;
private final Lock writeLock;
private final Lock readLock;
// 定义状态机
protected static final StateMachineFactory<JobStateMachine, JobStateInternal,
JobEventType, JobEvent>
stateMachineFactory = new StateMachineFactory<JobStateMachine, JobStateInternal, JobEventType, JobEvent>(JobStateInternal.NEW)
.addTransition(JobStateInternal.NEW, JobStateInternal.INITED, JobEventType.JOB_INIT, new InitTransition())
.addTransition(JobStateInternal.INITED, JobStateInternal.SETUP, JobEventType.JOB_START, new StartTransition())
.addTransition(JobStateInternal.SETUP, JobStateInternal.RUNNING, JobEventType.JOB_SETUP_COMPLETED, new SetupCompletedTransition())
.addTransition(JobStateInternal.RUNNING, EnumSet.of(JobStateInternal.KILLED, JobStateInternal.SUCCEEDED), JobEventType.JOB_COMPLETED, new JobTasksCompletedTransition())
.installTopology();
private final StateMachine<JobStateInternal, JobEventType, JobEvent> stateMachine;
public JobStateMachine(String jobID, EventHandler eventHandler) {
this.jobID = jobID;
// 多线程异步处理,state 有可能被同时读写,使用读写锁来避免竞争
ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
this.readLock = readWriteLock.readLock();
this.writeLock = readWriteLock.writeLock();
this.eventHandler = eventHandler;
stateMachine = stateMachineFactory.make(this);
}
protected StateMachine<JobStateInternal, JobEventType, JobEvent> getStateMachine() {
return stateMachine;
}
public static class InitTransition implements SingleArcTransition<JobStateMachine, JobEvent> {
@Override
public void transition(JobStateMachine jobStateMachine, JobEvent jobEvent) {
System.out.println("Receiving event " + jobEvent);
// do something...
// 完成后发送新的 Event —— JOB_START
jobStateMachine.eventHandler.handle(new JobEvent(jobStateMachine.jobID, JobEventType.JOB_START));
}
}
public static class StartTransition implements SingleArcTransition<JobStateMachine, JobEvent> {
@Override
public void transition(JobStateMachine jobStateMachine, JobEvent jobEvent) {
System.out.println("Receiving event " + jobEvent);
jobStateMachine.eventHandler.handle(new JobEvent(jobStateMachine.jobID, JobEventType.JOB_SETUP_COMPLETED));
}
}
public static class SetupCompletedTransition implements SingleArcTransition<JobStateMachine, JobEvent> {
@Override
public void transition(JobStateMachine jobStateMachine, JobEvent jobEvent) {
System.out.println("Receiving event " + jobEvent);
jobStateMachine.eventHandler.handle(new JobEvent(jobStateMachine.jobID, JobEventType.JOB_COMPLETED));
}
}
public static class JobTasksCompletedTransition implements MultipleArcTransition<JobStateMachine, JobEvent, JobStateInternal> {
@Override
public JobStateInternal transition(JobStateMachine jobStateMachine, JobEvent jobEvent) {
System.out.println("Receiving event " + jobEvent);
// 这是多结果状态部分,因此需要人为制定后续状态
// 这里整个流程结束,设置一下对应的状态
boolean flag = true;
if (flag) {
return JobStateInternal.SUCCEEDED;
} else {
return JobStateInternal.KILLED;
}
}
}
@Override
public void handle(JobEvent jobEvent) {
try {
// 注意这里为了避免静态条件,使用了读写锁
writeLock.lock();
JobStateInternal oldState = getInternalState();
try {
getStateMachine().doTransition(jobEvent.getType(), jobEvent);
} catch (InvalidStateTransitionException e) {
System.out.println("Can't handle this event at current state!");
}
if (oldState != getInternalState()) {
System.out.println("Job Transitioned from " + oldState + " to " + getInternalState());
}
} finally {
writeLock.unlock();
}
}
public JobStateInternal getInternalState() {
readLock.lock();
try {
return getStateMachine().getCurrentState();
} finally {
readLock.unlock();
}
}
public enum JobStateInternal {
NEW,
SETUP,
INITED,
RUNNING,
SUCCEEDED,
KILLED
}
}
二)状态机可视化
hadoop 中提供了状态机可视化的工具类 VisualizeStateMachine.java,可以拷贝到我们的工程中使用。
根据提示,运行需要三个参数:
Usage: %s <GraphName> <class[,class[,...]]> <OutputFile>%n

运行后会在项目根目录生成图文件 jsm.gv。
需要使用 graphviz工具将 gv 文件转换成 png 文件:
# linux 安装
yum install graphviz
# mac 安装
brew install graphviz
转换:
dot -Tpng jsm.gv > jsm.png
可视化状态机展示:

再使用这个工具对 Yarn 中的 Application 状态进行展示:

三)如果不用状态机库
【思考】
如果不用状态机,代码结构会是什么样呢?
下面这样的代码,如果要增加或修改逻辑可能就是很痛苦的一件事情了。
// 一堆的函数调用
// 一堆的 if 嵌套
// 或者 switch case
三、总结
本节对 Yarn 状态机库进行了介绍。实际使用时会结合事件库、服务库一同使用。
状态机库的使用帮助代码结构更加的清晰,新增状态处理逻辑只需要增加一个状态类别,或者增加一个方法处理对应类型的事件即可。将整个处理逻辑进行了拆分,便于编写和维护。
参考文章:
源码|Yarn的事件驱动模型与状态机
【深入浅出 Yarn 架构与实现】2-4 Yarn 基础库 - 状态机库的更多相关文章
- 【深入浅出 Yarn 架构与实现】3-1 Yarn Application 流程与编写方法
本篇学习 Yarn Application 编写方法,将带你更清楚的了解一个任务是如何提交到 Yarn ,在运行中的交互和任务停止的过程.通过了解整个任务的运行流程,帮你更好的理解 Yarn 运作方式 ...
- 【深入浅出 Yarn 架构与实现】2-2 Yarn 基础库 - 底层通信库 RPC
RPC(Remote Procedure Call) 是 Hadoop 服务通信的关键库,支撑上层分布式环境下复杂的进程间(Inter-Process Communication, IPC)通信逻辑, ...
- 【深入浅出 Yarn 架构与实现】2-1 Yarn 基础库概述
了解 Yarn 基础库是后面阅读 Yarn 源码的基础,本节对 Yarn 基础库做总体的介绍.并对其中使用的第三方库 Protocol Buffers 和 Avro 是什么.怎么用做简要的介绍. 一. ...
- 【深入浅出 Yarn 架构与实现】2-3 Yarn 基础库 - 服务库与事件库
一个庞大的分布式系统,各个组件间是如何协调工作的?组件是如何解耦的?线程运行如何更高效,减少阻塞带来的低效问题?本节将对 Yarn 的服务库和事件库进行介绍,看看 Yarn 是如何解决这些问题的. 一 ...
- YARN底层基础库
YARN基础库是其他一切模块的基础,它的设计直接决定了YARN的稳定性和扩展性,YARN借用了MRV1的一些底层基础库,比如RPC库等,但因为引入了很多新的软件设计方式,所以它的基础库更多,包括直 ...
- 【深入浅出 Yarn 架构与实现】1-1 设计理念与基本架构
一.Yarn 产生的背景 Hadoop2 之前是由 HDFS 和 MR 组成的,HDFS 负责存储,MR 负责计算. 一)MRv1 的问题 耦合度高:MR 中的 jobTracker 同时负责资源管理 ...
- 【深入浅出 Yarn 架构与实现】1-2 搭建 Hadoop 源码阅读环境
本文将介绍如何使用 idea 搭建 Hadoop 源码阅读环境.(默认已安装好 Java.Maven 环境) 一.搭建源码阅读环境 一)idea 导入 hadoop 工程 从 github 上拉取代码 ...
- Spark on Yarn 架构解析
. 一.Hadoop Yarn组件介绍: 我们都知道yarn重构根本的思想,是将原有的JobTracker的两个主要功能资源管理器 和 任务调度监控 分离成单独的组件.新的架构使用全局管理所有应用程序 ...
- Yarn集群的搭建、Yarn的架构和WordCount程序在集群提交方式
一.Yarn集群概述及搭建 1.Mapreduce程序运行在多台机器的集群上,而且在运行是要使用很多maptask和reducertask,这个过程中需要一个自动化任务调度平台来调度任务,分配资源,这 ...
随机推荐
- windows10/11高性能模式开启
大部分用户windows10和11高性能模式都被隐藏了 并且没有隐藏选项我们如何开启呢如下 win+R如下 打开运行-输入cmd进入后输入代码如下 powercfg -SETACTIVE 8c5e7f ...
- NetCore性能优化
NetCore性能优化2.非跟踪查询在只读方案中使用结果时,非跟踪查询十分有用,可以更快速地执行.增加AsNoTracking()表示非跟踪,如:var users = context.User.As ...
- Homework5
问:什么是分而治之? 答:分而治之就是通过一系列的方法,将复杂的问题逐渐划分成若干份相对简单的问题的方法,对每个相对简单问题进行一一解决,若干个简单问题的解的集合就是一个复杂问题的解.分而治之的应用体 ...
- C++ "链链"不忘@必有回响之单链表
1. 前言 数组和链表是数据结构的基石,是逻辑上可描述.物理结构真实存在的具体数据结构.其它的数据结构往往在此基础上赋予不同的数据操作语义,如栈先进后出,队列先进先出-- 数组中的所有数据存储在一片连 ...
- MySQL5.7.15数据库配置主从服务器实现双机热备实例教程
环境说明 程序在:Web服务器192.168.0.57上面 数据库在:MySQL服务器192.168.0.67上面 实现目的:增加一台MySQL备份服务器(192.168.0.68),做为MySQL服 ...
- Kubernetes 监控--PromQL
Prometheus 通过指标名称(metrics name)以及对应的一组标签(label)唯一定义一条时间序列.指标名称反映了监控样本的基本标识,而 label 则在这个基本特征上为采集到的数据提 ...
- CentOS6 配置阿里云 NTP 服务
本文以Centos 6.5为例介绍如何修改Linux实例时区,以及开启和配置Linux NTP服务,保证实例本地时间精确同步. 前提条件 NTP服务的通信端口为UDP 123,设置NTP服务之前请确保 ...
- alertmanager配置文件详解
global: smtp_smarthost: 'localhost:25' smtp_from: 'alertmanager@example.org' #用于邮件通知的P发件人 route: #每个 ...
- Java SpringBoot 项目构建 Docker 镜像调优实践
PS:已经在生产实践中验证,解决在生产环境下,网速带宽小,每次推拉镜像影响线上服务问题,按本文方式构建镜像,除了第一次拉取.推送.构建镜像慢,第二.三-次都是几百K大小传输,速度非常快,构建.打包.推 ...
- Java程序设计(四)作业
要求:定义一个Java项目,项目名为"学号_姓名_题号",如:"20181101_张三_1",完成后将项目复制到桌面并压缩提交到邮箱82794085@qq.co ...