知识图谱顶会论文(ACL-2022) ACL-SimKGC:基于PLM的简单对比KGC
12.(2022.5.4)ACL-SimKGC:基于PLM的简单对比KGC
摘要
知识图谱补全(KGC)的目的是对已知事实进行推理,并推断出缺失的环节。基于文本的方法,如KG-BERT从自然语言描述中学习实体表示,并具有归纳KGC的潜力。然而,基于文本的方法的性能仍然大大落后于基于图嵌入的方法(KGE),如TransE和RotatE。
在本研究中,我们认为关键问题在于有效的对比学习。为了提高学习效率,我们引入了三种类型的负采样:批内负采样、批前负采样和作为困难负样本的简单形式的自我负采样。结合InfoNCE损失,我们提出的模型SimKGC在多个基准数据集上的性能大大优于基于嵌入的方法。在平均倒数秩(MRR)方面,我们在WN18RR上比之前最先进的模型提高了+19%,在Wikidata5M直推设置上提高了+6.8%,在Wikidata5M归纳设置上提高了+22%。我们进行了彻底的分析以深入了解每个组件。我们的代码可从https://github.com/intfloat/SimKGC获得。
归纳学习(Inductive Learning): 顾名思义,就是从已有训练数据中归纳出模式来,应用于新的测试数据和任务。我们常用的机器学习模式就是归纳学习。
直推学习(Transductive Learning): 也叫转导学习,指的是由当前学习的知识直接推广到指定的部分数据上。即用于训练的数据包含了测试数据,学习过程是作用在这个固定的数据上的,一旦数据发生改变,需要重新进行学习训练。
Inductive Learning 对应于meta-learning(元学习),要求从诸多给定的任务和数据中学习通用的模式,迁移到未知的任务和数据上。
Transductive Learning 对应于domain adaptation(领域自适应),给定训练的数据包含了目标域数据,要求训练一个对目标域数据有最小误差的模型。
困难负样本(Hard Negative): hard negative就是当你得到错误的预测样本时,会创建一个负样本,并把这个负样本添加到训练集中去。当重新训练你的分类器后,分类器会表现的更好,并且不会像之前那样产生多的错误的正样本。
使用 MRR/Hits10 评估链路预测
- 平均倒数秩(Mean reciprocal rank,MRR)
MRR是一种衡量搜索质量的方法。我们取一个未被破坏的节点,找到距离定义为相似性分数的”最近邻”。根据相似性得分对最近的节点进行排名,并期望连接的节点会出现在排名的顶部。如果节点没有出现在第一个,MRR 会降低模型的精度得分。- Hits@n:(n通常为1、3和10)
根据相似性得分对最近的节点进行排名,我们期望被破坏的节点出现在前n个最近的节点中。
1.引言
大规模知识图(KGs)是知识密集型应用的重要组成部分,如问答、推荐系统和智能会话代理等。KG通常由三元组(h,r,t)组成,其中h是头实体,r是关系,t是尾实体。主流的开源KGs包括Freebase、Wikidata、YAGO、ConceptNet和WordNet等。尽管它们很有用,但它们往往是不完整的。KGC技术是知识图谱自动构建和验证的必要技术。
现有的KGC方法可以分为两大类:基于嵌入的方法和基于文本的方法。
- 基于嵌入的方法将每个实体和关系映射到一个低维向量,而不使用任何附加信息(例如实体描述)。KGE包括TransE、TransH、RotatE和TuckER等。
- 基于文本的方法整合了实体表示学习的可用文本,并且如图1所示,使用了附加信息(例如实体描述)。直观地说,基于文本的方法应该优于基于嵌入的方法,因为它们可以访问额外的输入信号。然而,在流行的基准测试上的结果却截然不同:基于文本的方法仍然落后于预训练的KGE模型。
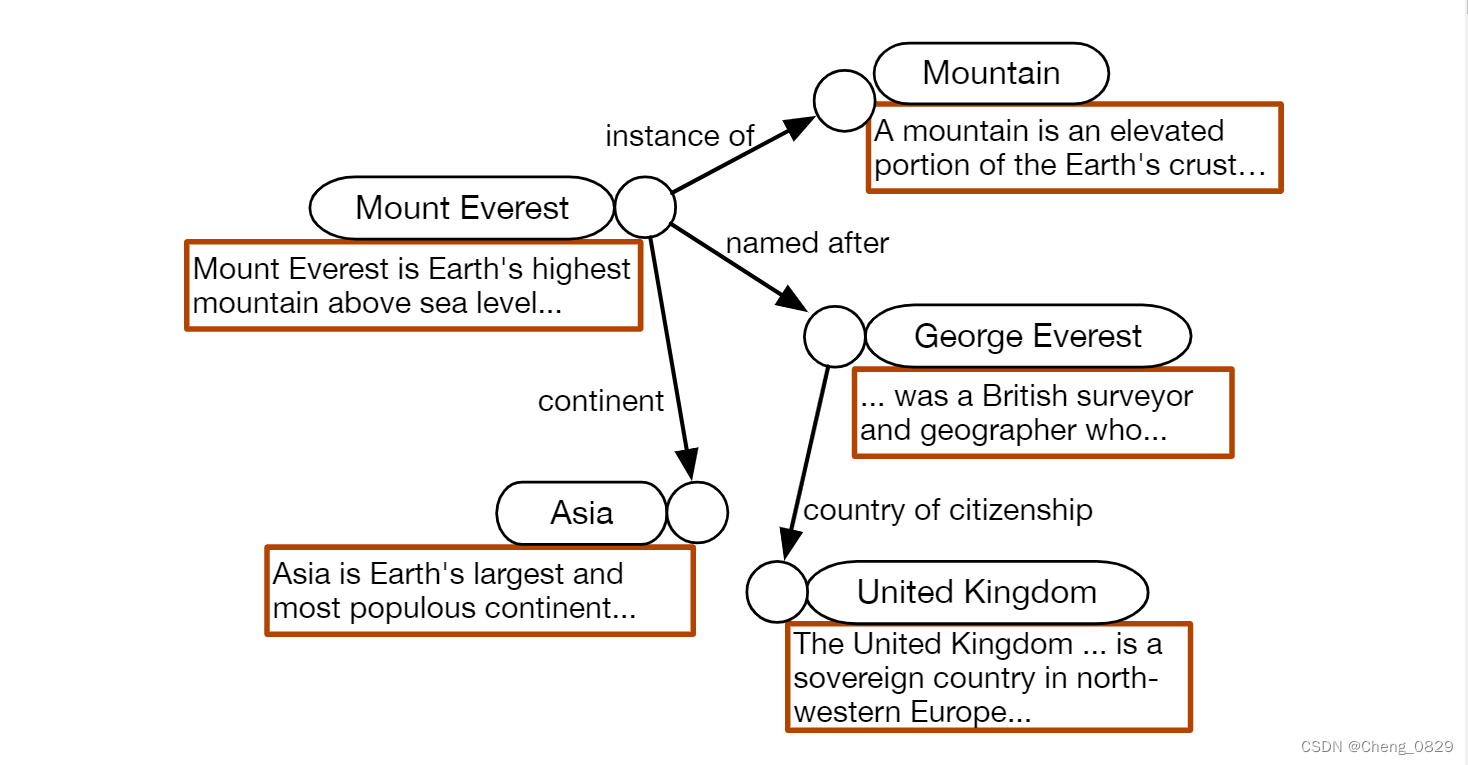
知识图谱的一个例子。每个实体都有其名称和文字描述。
我们假设,这种性能下降的关键问题是对比学习的低效。基于嵌入的方法不涉及成本高昂的文本编码器的计算,因此可以在有大量负样本的情况下高效训练。例如,在Wikidata5M数据集上,负样本数量为64,用RotatE的默认配置训练1000个epoch。而基于文本的KEPLER方法由于RoBERTa的计算成本高,只能在负样本数量为1的情况下训练30个epoch。
在本文中,受对比学习研究最新进展的启发,我们引入了三种类型的负采样以改进基于文本的KGC方法:批内负采样、批前负采样和自我负采样。
- 通过采用双编码器而不是交叉编码器架构,可以使用更大的批尺寸来增加批内负采样的数量。
- 来自之前批次的向量被缓存,并作为批前负采样。
- 此外,挖掘困难负样本也有助于提高对比学习。我们发现头实体本身可以作为困难负样本,我们称之为"自我负采样"。因此,负样本量可以增加到数千的规模。我们还提出将损失函数从基于间隔的排序损失改为InfoNCE,使模型更关注困难负样本。
基于文本的方法的一个优点是它们支持归纳实体表示学习。在训练中未知的实体仍然可以被适当地建模,而基于嵌入的方法,如TransE,只能在直推设置下进行推理。归纳知识图的补全在现实世界中非常重要,因为每天都有新的实体出现(直推学习要求把所有数据包括测试数据都当作训练数据)。此外,基于文本的方法可以利用最先进的预先训练的语言模型来学习更好的表示。近期的一系列工作试图从BERT中引出隐式存储的知识。KGC的任务也可以看作是检索这些知识的一种方式。
如果在图中通过一条短路径连接,两个实体更有可能相互关联。根据经验,我们发现基于文本的模型严重依赖语义匹配,在一定程度上忽略了这种拓扑偏差。我们提出了一个简单的重新排序策略,即提高头实体的k跳邻居的分数。
k跳邻居(k-hop): 图拓扑领域的概念,即图中两个点的最短距离为k,则互为k-hop邻居。
我们通过在WN18RR、FB15k-237和Wikidata5M(包括直推和归纳设置)三个主流基准数据集上进行实验来评估我们提出的SimKGC模型。根据自动评价指标(MRR, Hits@{1,3,10}),SimKGC在WN18RR(MRR 47.6→66.6)、Wikidata5M直推设置(MRR 29.0→35.8)和归纳设置(MRR 49.3→71.4)上的表现明显优于现有方法。在FB15k-237数据集上,我们的结果也具有竞争力。为了帮助更好地理解我们提出的方法,我们进行了一系列分析并报告了人工评估结果。希望SimKGC能够促进未来更好的KGC系统的开发。
2.相关工作
2.1 知识图补全(KGC)
KGC涉及对多关系数据建模,以帮助自动构建大规模KGs。在基于平移的方法中,如TransE和TransH,三元组(h,r,t)是从头实体h到尾实体t的特定关系的平移。有人在基于平移的方法的基础上引入了复数嵌入,以便增加模型的表现力。RotatE在复空间中将一个三元组作为关系旋转来建模。有人将KGC视为一个三维二元张量因子分解问题,并研究了几种因子分解技术的有效性。有些方法尝试合并实体描述。DKRL使用CNN对文本进行编码,而KG-BERT、StAR和BLP都采用PLM来计算实体嵌入。GraIL和BERTRL利用子图或路径信息进行归纳关系预测。在基准测试的性能方面,基于文本的方法仍然不如RotatE等方法。
2.2 预训练语言模型(PLM)
PLM(如BERT、GPT和T5等)使得现在的NLP中学习方法发生了很大转变。首先对大量带有语言建模目标的无标记文本语料库进行预训练,然后对下游任务进行微调。考虑到它们在少样本甚至零样本场景下的良好表现,一个有趣的问题是:“PLM可以用作知识库吗?” 有人基于此提出了带有手工设计提示探索的语言模型。一系列后续工作专注于寻找更好的提示,以引出模型参数中隐式存储的知识。另一种工作将符号知识注入到语言模型的预训练中,并在一些知识密集型任务中表现出一定的性能提升。
2.3 对比学习
对比学习通过正样本和负样本之间的对比来学习有用的表示。正样本和负样本的定义取决于具体的任务。在自我监督视觉表现学习中,正样本对是同一图像的两个增强视图,而负样本对是不同图像的两个增强视图。最近,对比学习方法在许多不同的领域都取得了巨大的成功,包括多模态预训练、视频文本检索和自然语言理解等。在NLP领域,通过利用来自问答对、自然语言推理数据和并行语料库的监督标记,对比类方法在语义相似基准测试上超过了无对比方法。有人采用对比学习改进密集文本检索以便在开放域进行问答,其中正类文本就是包含正确答案的文本。
3.模型方法
3.1 符号
知识图\(\mathcal{G}\)是一个有向图,其中顶点是实体\(\mathcal{E}\),每条边可以表示为一个三元组\((h,r,t)\),其中h,r,t分别对应头实体、关系和尾实体。KGC的链接预测任务是在给定不完全知识图\(\mathcal{G}\)的情况下推断缺失的三元组。在广泛采用实体排名评估的方式下,尾实体预测\((h,r,?)\)需要对给定\(h\)和\(r\)的所有实体进行排名,头实体预测\((?,r,t)\)也类似。在本研究中,对于每个三元组\((h,r,t)\),我们添加一个逆三元组\((t,r^{−1},h)\),其中\(r^{−1}\)是\(r\)的逆关系。基于这样的创新,我们只需要处理尾实体的预测问题。
3.2 模型结构
我们提出的模型SimKGC采用双编码器架构。两个编码器使用相同的PLM进行初始化,但不共享参数。
给定一个三元组\((h,r,t)\),第一个编码器BERT\(_{hr}\)用于计算头部实体\(h\)的关系感知嵌入。我们首先用一个特殊的符号[SEP]在中间连接实体\(h\)和关系\(r\)的文本描述。BERT\(_{hr}\)用于获取最后一层隐藏状态。我们没有直接使用第一个标记的隐藏状态,而是使用平均池化,然后进行\(L_2\)归一化,以获得关系感知的嵌入\(\mathbf{e}_{hr}\),这是因为平均池化已被证明可以产生更好的句子嵌入。\(\mathbf{e}_{hr}\)是关系感知的,因为即使头实体是相同的,但不同的关系将有不同的输入,因此有不同的嵌入。
类似地,第二个编码器BERT\(_t\)用于计算尾部实体\(t\)的\(L_2\)归一化嵌入\(\mathbf{e}_t\)。BERT\(_t\)的输入只包含实体\(t\)的文本描述。
由于嵌入\(\mathbf{e}_{hr}\)和\(\mathbf{e}_t\)都是\(L_2\)归一化的,余弦相似度\(cos(\mathbf{e}_{hr}, \mathbf{e}_t)\)即为两个嵌入之间的点积:
\]
对于尾部实体预测(h,r,?),我们计算\(\mathbf{e}_{hr}\)与\(\mathcal{E}\)中所有实体的余弦相似度,并把得分最高的实体作为预测输出:
\]
3.3 负采样
对于知识图补全,训练数据仅由正三元组组成。在给定一个正类的三元组(h,r,t)时,“负抽样”需要对一个或多个负三元组进行抽样来训练判别模型。现有的大多数方法都是随机破坏h或t,然后过滤掉训练图\(\mathcal{G}\)中出现的假负类。不同三元组的负样本不共享,因此是独立的。对于基于嵌入的方法,典型的负样本数量为64左右;基于文本的方法为5左右。我们结合了三种类型的负采样来提高训练效率,而不产生显著的计算和内存开销。
3.3.1 批内负采样(IB)
这是在视觉表征学习和密集文本检索等方面被广泛采用的策略。
同一批中的实体可以用作负样本。这种批内负样本允许双编码器模型有效重用实体嵌入。
3.3.2 批前负采样(PB)
批内负采样的缺点是负采样的数量与批次大小相关。批前负采样使用来自前批次的实体嵌入。由于这些嵌入是用前几轮训练的模型参数计算的,所以它们与批内负采样不一致。通常只使用1或2个前批次。其他方法如MoCo也可以提供更多的负样本。我们把MoCo的研究留作以后的工作。
3.3.3 自我负采样(SN)
除了增加负样本的数量,挖掘困难负采样对提高对比表现学习也很重要。对于尾部实体预测(h,r,?),基于文本的方法倾向于给头实体h分配高分,这可能是因为文本重叠程度高。为了缓解这个问题,我们建议使用头部实体h作为困难负采样的自我负样本。引入自我负样本可以减少模型对虚假文本匹配的依赖(类似于自我否定)。
3.3.4 负采样处理
我们用\(\mathcal{N}_{IB}\)、\(\mathcal{N}_{PB}\)和\(\mathcal{N}_{SN}\)来表示上述三种负采样。
在训练过程中,可能会出现一些假负类样本。例如,正确的实体(已经在KG中的)碰巧出现在同一个批处理中的另一个三元组中,被批内负采样标记为负样本。
我们用二进制掩码过滤掉这些假负类样本。将所有负样本全部组合起来,负样本集合定义为:
\left\{t^{\prime} \mid t^{\prime} \in \mathcal{N}_{\mathrm{IB}} \cup \mathcal{N}_{\mathrm{PB}} \cup \mathcal{N}_{\mathrm{SN}},\left(h, r, t^{\prime}\right) \notin \mathcal{G}\right\}\tag{3}
\]
假设批量大小为1024,使用2个预批次,我们将有\(|\mathcal{N}_{IB}|=1024−1\),\(|\mathcal{N}_{PB}|=2×1024\),\(|\mathcal{N}_{SN}|=1\),\(|N(h,r)|=3072\)个负样本。
3.4 基于图的重排序
知识图通常表现出空间局部性。附近的实体比相距很远的实体更有可能相互关联。基于文本的KGC方法能很好地捕获语义相关性,但可能无法完全捕获这种归纳偏差。我们提出了一个简单的基于图的重排序策略:根据来自训练集的图,如果\(t_i\)在头实体\(h\)的\(k\)跳邻居\(\mathcal{E}_k(h)\)中,则设α≥0,提高候选尾实体\(t_i\)的分数:
\]
3.5 训练和推断
在训练过程中,我们使用含有间隔的InfoNCE损失函数:
\]
其中,间隔\(γ\)>0促使模型提高正确三元组\((h,r,t)\)的得分。\(φ(h,r,t)\)为候选三元组的评分函数,如式1所示,定义\(φ(h,r,t)=cos(\mathbf{e}_{hr}, \mathbf{e}_t)∈[−1,1]\)。温度\(τ\)可以调整负样本的相对重要性,较小的\(τ\)使损失函数更关注困难负采样,但也有过拟合标签噪声的风险。为了避免将\(τ\)作为超参数调优,我们将\(log\frac{1}{τ}\)重新参数化为一个可学习参数。
对于推理,最耗时的部分是实体嵌入的时间复杂度为\(O(|E|)\)的BERT前向传播计算。假设有\(|\mathcal{T}|\)个测试三元组。对于每个三重\((h,r,?)\)和\((t,r^{−1},?)\)而言,我们需要计算关系感知的头部实体嵌入,并使用点积来获得所有实体的排名得分。
总的来说,SimKGC需要\(|\mathcal{E}|+2×|\mathcal{T}|\)次BERT正向传播,而KG-BERT等交叉编码器模型也需要\(|\mathcal{E}|+2×|\mathcal{T}|\)次BERT正向传播。
能够扩展到大型数据集对于实际使用非常重要。对于双编码器模型,我们可以在快速相似度搜索工具(如Faiss)的帮助下预先计算实体嵌入并高效检索排名靠前的k个实体。
知识图谱顶会论文(ACL-2022) ACL-SimKGC:基于PLM的简单对比KGC的更多相关文章
- 知识图谱顶会论文(KDD-2022) kgTransformer:复杂逻辑查询的预训练知识图谱Transformer
论文标题:Mask and Reason: Pre-Training Knowledge Graph Transformers for Complex Logical Queries 论文地址: ht ...
- 知识图谱顶会论文(SIGIR-2022) MorsE:归纳知识图嵌入的元知识迁移
MorsE:归纳知识图嵌入的元知识迁移 论文题目: Meta-Knowledge Transfer for Inductive Knowledge Graph Embedding 论文地址: http ...
- 知识图谱顶会论文(IJCAI-2022) TEMP:多跳推理的类型感知嵌入
IJCAI-TEMP:知识图谱上多跳推理的类型感知嵌入 论文地址: Type-aware Embeddings for Multi-Hop Reasoning over Knowledge Graph ...
- 知识图谱顶会论文(ACL-2022) PKGC:预训练模型是否有利于KGC?可靠的评估和合理的方法
PKGC:预训练模型是否有利于KGC?可靠的评估和合理的方法 论文地址:Do Pre-trained Models Benefit Knowledge Graph Completion? A Reli ...
- 知识图谱顶会论文(ACL-2022) CAKE:用于多视图KGC的可扩展常识感知框架
CAKE:用于多视图KGC的可扩展常识感知框架.pdf 论文地址:CAKE:Scalable Commonsense-Aware Framework For Multi-View Knowledge ...
- 知识图谱-生物信息学-医学论文(Chip-2022)-BCKG-基于临床指南的中国乳腺癌知识图谱的构建与应用
16.(2022)Chip-BCKG-基于临床指南的中国乳腺癌知识图谱的构建与应用 论文标题: Construction and Application of Chinese Breast Cance ...
- 知识图谱-生物信息学-医学论文(BMC Bioinformatics-2022)-挖掘阿尔茨海默病相关KG来确定潜在的相关语义三元组用于药物再利用
论文标题: Mining On Alzheimer's Diseases Related Knowledge Graph to Identity Potential AD-related Semant ...
- 知识图谱顶刊综述 - (2021年4月) A Survey on Knowledge Graphs: Representation, Acquisition, and Applications
知识图谱综述(2021.4) 论文地址:A Survey on Knowledge Graphs: Representation, Acquisition, and Applications 目录 知 ...
- 知识图谱-生物信息学-医学顶刊论文(Briefings in Bioinformatics-2021):生物信息学中的图表示学习:趋势、方法和应用
4.(2021.6.24)Briefings-生物信息学中的图表示学习:趋势.方法和应用 论文标题: Graph representation learning in bioinformatics: ...
随机推荐
- 定语从句关系代词只能用 that 的情况
当先行词被形容词最高级.序数词,以及 the only.the very.the right 等修饰时,关系代词只能用 that. This is the most interesting movie ...
- 【LOJ#3197】【eJOI2019】T形覆盖 - (图论、简单推导)
题面 题解 (题目中说的四种摆放方式实际上是分别旋转0°,90°,180°,270°后的图形) 题目中关于摆放方式的描述听起来很臭,我们把它转换一下,每个拼版先覆盖"上下左右中"五 ...
- 【c语言学习】1 基础环境安装调试
1-1下载 vs2019 vs2019下载链接https://visualstudio.microsoft.com/zh-hans/vs/community/ 1-2安装配置环境 记得勾选上c++开发 ...
- 分布式协同AI基准测试项目Ianvs:工业场景提升5倍研发效率
摘要:全场景可扩展的分布式协同AI基准测试项目 Ianvs(雅努斯),能为算法及服务开发者提供全面开发套件支持,以研发.衡量和优化分布式协同AI系统. 本文分享自华为云社区<KubeEdge|分 ...
- 完全解析Array.apply(null, { length: 1000 })
Array.apply(null, { length: 1000 }) 点击打开视频讲解更加详细 在阅读VueJS教程时有这么段demo code: render: function (createE ...
- 记一次 .NET 某数控机床控制程序 卡死分析
一:背景 1. 讲故事 前段时间有位朋友微信上找到我,说它的程序出现了卡死,让我帮忙看下是怎么回事? 说来也奇怪,那段时间求助卡死类的dump特别多,被迫训练了一下对这类问题的洞察力 ,再次声明一下, ...
- Memlab,一款分析 JavaScript 堆并查找浏览器和 Node.js 中内存泄漏的开源框架
Memlab 是一款 E2E 测试和分析框架,用于发现 JavaScript 内存泄漏和优化机会. Memlab 是 JavaScript 的内存测试框架.它支持定义一个测试场景(使用 Puppete ...
- 升级openssl和openssh脚本
#!/bin/bash # 原先的版本号信息 # openssl version #OpenSSL 1.0.2k-fips 26 Jan 2017 # ssh -V #OpenSSH_7.4p1, O ...
- JDK19新特性使用详解
前提 JDK19于2022-09-20发布GA版本,本文将会详细介绍JDK19新特性的使用. 新特性列表 新特性列表如下: JPE-405:Record模式(预览功能) JPE-422:JDK移植到L ...
- ERP 软件为什么很贵?
ERP软件的贵体现在两个方面,一个是软件系统贵,一个是部署实施贵,究其原因,就是ERP专业性太高.内部业务逻辑忒复杂,而面向形形色色的实体企业时个性化需求又加剧了它整体的复杂性,实施部署客制化无法避免 ...