机器学习读书笔记(二)使用k-近邻算法改进约会网站的配对效果
一、背景
海伦女士一直使用在线约会网站寻找适合自己的约会对象。尽管约会网站会推荐不同的任选,但她并不是喜欢每一个人。经过一番总结,她发现自己交往过的人可以进行如下分类
- 不喜欢的人
- 魅力一般的人
- 极具魅力的人
海伦收集约会数据已经有了一段时间,她把这些数据存放在文本文件datingTestSet.txt中,每个样本数据占据一行,总共有1000行。
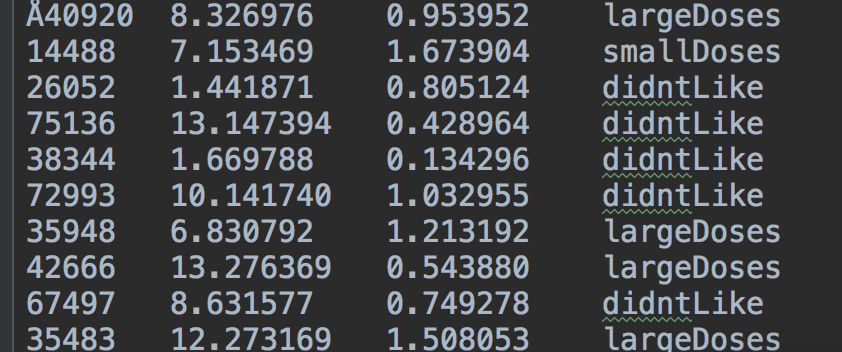
海伦收集的样本数据主要包含以下3种特征:
- 每年获得的飞行常客里程数
- 玩视频游戏所消耗时间百分比
- 每周消费的冰淇淋公升数
二、准备数据:数据的解析
在将上述特征数据输入到分类器前,必须将待处理的数据的格式改变为分类器可以接收的格式。在knn_test.py文件中创建名为file2matrix的函数,以此来处理输入格式问题。 将datingTestSet.txt放到与kn_test.py相同目录下,编写代码如下
# -*- coding: UTF-8 -*-
import numpy as np """
函数说明:打开并解析文件,对数据进行分类:1代表不喜欢,2代表魅力一般,3代表极具魅力 Parameters:
filename - 文件名
Returns:
returnMat - 特征矩阵
classLabelVector - 分类Label向量
""" def file2matrix(filename):
# 打开文件
fr = open(filename)
# 读取文件所有内容
arrayOLines = fr.readlines()
# 得到文件行数
numberOfLines = len(arrayOLines)
# 返回的NumPy矩阵,解析完成的数据:numberOfLines行,3列
returnMat = np.zeros((numberOfLines, 3))
# 返回的分类标签向量
classLabelVector = []
# 行的索引值
index = 0
for line in arrayOLines:
# s.strip(rm),当rm空时,默认删除空白符(包括'\n','\r','\t',' ')
line = line.strip()
# 使用s.split(str="",num=string,cout(str))将字符串根据'\t'分隔符进行切片。
listFromLine = line.split('\t')
# 将数据前三列提取出来,存放到returnMat的NumPy矩阵中,也就是特征矩阵
returnMat[index, :] = listFromLine[0:3]
# 根据文本中标记的喜欢的程度进行分类,1代表不喜欢,2代表魅力一般,3代表极具魅力
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat, classLabelVector """
函数说明:main函数 Parameters:
无
Returns:
无
"""
if __name__ == '__main__':
# 打开的文件名
filename = "datingTestSet.txt"
# 打开并处理数据
datingDataMat, datingLabels = file2matrix(filename)
print(datingDataMat)
print(datingLabels)
三、分析数据:数据可视化
# -*- coding: UTF-8 -*- from matplotlib.font_manager import FontProperties
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
import numpy as np """
函数说明:打开并解析文件,对数据进行分类:1代表不喜欢,2代表魅力一般,3代表极具魅力 Parameters:
filename - 文件名
Returns:
returnMat - 特征矩阵
classLabelVector - 分类Label向量
""" def file2matrix(filename):
# 打开文件
fr = open(filename)
# 读取文件所有内容
arrayOLines = fr.readlines()
# 得到文件行数
numberOfLines = len(arrayOLines)
# 返回的NumPy矩阵,解析完成的数据:numberOfLines行,3列
returnMat = np.zeros((numberOfLines, 3))
# 返回的分类标签向量
classLabelVector = []
# 行的索引值
index = 0
for line in arrayOLines:
# s.strip(rm),当rm空时,默认删除空白符(包括'\n','\r','\t',' ')
line = line.strip()
# 使用s.split(str="",num=string,cout(str))将字符串根据'\t'分隔符进行切片。
listFromLine = line.split('\t')
# 将数据前三列提取出来,存放到returnMat的NumPy矩阵中,也就是特征矩阵
returnMat[index, :] = listFromLine[0:3]
# 根据文本中标记的喜欢的程度进行分类,1代表不喜欢,2代表魅力一般,3代表极具魅力
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat, classLabelVector """
函数说明:可视化数据 Parameters:
datingDataMat - 特征矩阵
datingLabels - 分类Label
Returns:
无
""" def showdatas(datingDataMat, datingLabels):
# 设置汉字格式
font = FontProperties(fname=r"/Library/Fonts/Songti.ttc", size=14)
# 将fig画布分隔成1行1列,不共享x轴和y轴,fig画布的大小为(13,8)
# 当nrow=2,nclos=2时,代表fig画布被分为四个区域,axs[0][0]表示第一行第一个区域
fig, axs = plt.subplots(nrows=2, ncols=2, sharex=False, sharey=False, figsize=(13, 8)) numberOfLabels = len(datingLabels)
LabelsColors = []
for i in datingLabels:
if i == 1:
LabelsColors.append('black')
if i == 2:
LabelsColors.append('orange')
if i == 3:
LabelsColors.append('red')
# 画出散点图,以datingDataMat矩阵的第一(飞行常客例程)、第二列(玩游戏)数据画散点数据,散点大小为15,透明度为0.5
axs[0][0].scatter(x=datingDataMat[:, 0], y=datingDataMat[:, 1], color=LabelsColors, s=15, alpha=.5)
# 设置标题,x轴label,y轴label
axs0_title_text = axs[0][0].set_title(u'每年获得的飞行常客里程数与玩视频游戏所消耗时间占比', FontProperties=font)
axs0_xlabel_text = axs[0][0].set_xlabel(u'每年获得的飞行常客里程数', FontProperties=font)
axs0_ylabel_text = axs[0][0].set_ylabel(u'玩视频游戏所消耗时间占', FontProperties=font)
plt.setp(axs0_title_text, size=9, weight='bold', color='red')
plt.setp(axs0_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs0_ylabel_text, size=7, weight='bold', color='black') # 画出散点图,以datingDataMat矩阵的第一(飞行常客例程)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5
axs[0][1].scatter(x=datingDataMat[:, 0], y=datingDataMat[:, 2], color=LabelsColors, s=15, alpha=.5)
# 设置标题,x轴label,y轴label
axs1_title_text = axs[0][1].set_title(u'每年获得的飞行常客里程数与每周消费的冰激淋公升数', FontProperties=font)
axs1_xlabel_text = axs[0][1].set_xlabel(u'每年获得的飞行常客里程数', FontProperties=font)
axs1_ylabel_text = axs[0][1].set_ylabel(u'每周消费的冰激淋公升数', FontProperties=font)
plt.setp(axs1_title_text, size=9, weight='bold', color='red')
plt.setp(axs1_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs1_ylabel_text, size=7, weight='bold', color='black') # 画出散点图,以datingDataMat矩阵的第二(玩游戏)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5
axs[1][0].scatter(x=datingDataMat[:, 1], y=datingDataMat[:, 2], color=LabelsColors, s=15, alpha=.5)
# 设置标题,x轴label,y轴label
axs2_title_text = axs[1][0].set_title(u'玩视频游戏所消耗时间占比与每周消费的冰激淋公升数', FontProperties=font)
axs2_xlabel_text = axs[1][0].set_xlabel(u'玩视频游戏所消耗时间占比', FontProperties=font)
axs2_ylabel_text = axs[1][0].set_ylabel(u'每周消费的冰激淋公升数', FontProperties=font)
plt.setp(axs2_title_text, size=9, weight='bold', color='red')
plt.setp(axs2_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs2_ylabel_text, size=7, weight='bold', color='black')
# 设置图例
didntLike = mlines.Line2D([], [], color='black', marker='.',
markersize=6, label='didntLike')
smallDoses = mlines.Line2D([], [], color='orange', marker='.',
markersize=6, label='smallDoses')
largeDoses = mlines.Line2D([], [], color='red', marker='.',
markersize=6, label='largeDoses')
# 添加图例
axs[0][0].legend(handles=[didntLike, smallDoses, largeDoses])
axs[0][1].legend(handles=[didntLike, smallDoses, largeDoses])
axs[1][0].legend(handles=[didntLike, smallDoses, largeDoses])
# 显示图片
plt.show() """
函数说明:main函数 Parameters:
无
Returns:
无
"""
if __name__ == '__main__':
# 打开的文件名
filename = "datingTestSet.txt"
# 打开并处理数据
datingDataMat, datingLabels = file2matrix(filename)
showdatas(datingDataMat, datingLabels)
四、准备数据:数据归一化
如下给出了四组样本,如果想要计算样本3和样本4之间的距离,可以使用欧拉公式计算。
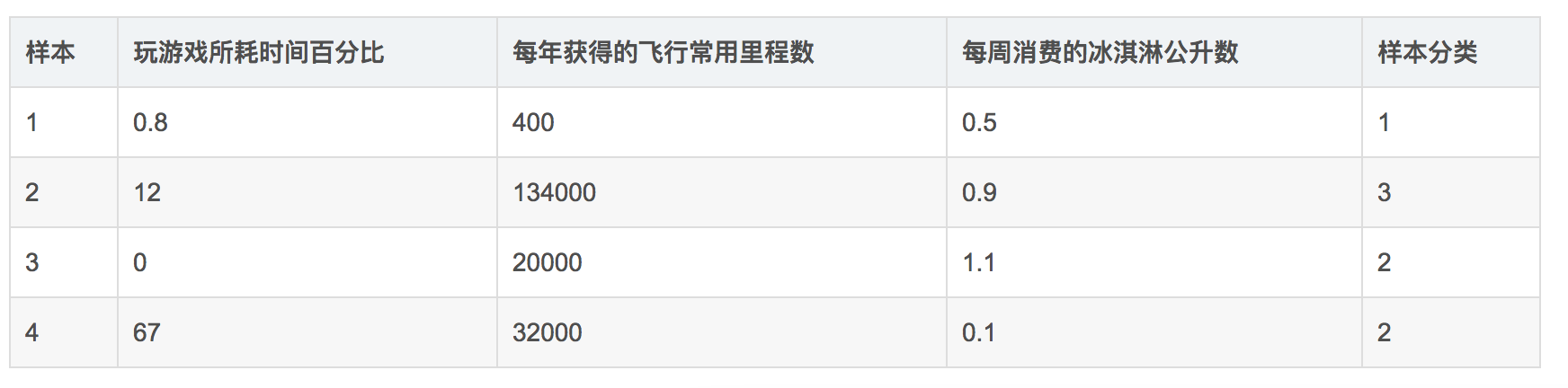
我们很容易发现,上面方程中数字差值最大的属性对计算结果的影响最大,也就是说,每年获取的飞行常客里程数对于计算结果的影响将远远大于表2.1中其他两个特征-玩视频游戏所耗时间占比和每周消费冰淇淋公斤数的影响。而产生这种现象的唯一原因,仅仅是因为飞行常客里程数远大于其他特征值。但海伦认为这三种特征是同等重要的,因此作为三个等权重的特征之一,飞行常客里程数并不应该如此严重地影响到计算结果。
在处理这种不同取值范围的特征值时,我们通常采用的方法是将数值归一化,如将取值范围处理为0到1或者-1到1之间。下面的公式可以将任意取值范围的特征值转化为0到1区间内的值:
newValue = (oldValue - min) / (max - min)
五、测试算法:验证分类器
为了测试分类器效果,编写代码如下:
# -*- coding: UTF-8 -*-
import numpy as np
import operator """
函数说明:kNN算法,分类器 Parameters:
inX - 用于分类的数据(测试集)
dataSet - 用于训练的数据(训练集)
labes - 分类标签
k - kNN算法参数,选择距离最小的k个点
Returns:
sortedClassCount[0][0] - 分类结果
""" def classify0(inX, dataSet, labels, k):
# numpy函数shape[0]返回dataSet的行数
dataSetSize = dataSet.shape[0]
# 在列向量方向上重复inX共1次(横向),行向量方向上重复inX共dataSetSize次(纵向)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
# 二维特征相减后平方
sqDiffMat = diffMat ** 2
# sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
# 开方,计算出距离
distances = sqDistances ** 0.5
# 返回distances中元素从小到大排序后的索引值
sortedDistIndices = distances.argsort()
# 定一个记录类别次数的字典
classCount = {}
for i in range(k):
# 取出前k个元素的类别
voteIlabel = labels[sortedDistIndices[i]]
# dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
# 计算类别次数
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# python3中用items()替换python2中的iteritems()
# key=operator.itemgetter(1)根据字典的值进行排序
# key=operator.itemgetter(0)根据字典的键进行排序
# reverse降序排序字典
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# 返回次数最多的类别,即所要分类的类别
return sortedClassCount[0][0] """
函数说明:打开并解析文件,对数据进行分类:1代表不喜欢,2代表魅力一般,3代表极具魅力 Parameters:
filename - 文件名
Returns:
returnMat - 特征矩阵
classLabelVector - 分类Label向量 """ def file2matrix(filename):
# 打开文件
fr = open(filename)
# 读取文件所有内容
arrayOLines = fr.readlines()
# 得到文件行数
numberOfLines = len(arrayOLines)
# 返回的NumPy矩阵,解析完成的数据:numberOfLines行,3列
returnMat = np.zeros((numberOfLines, 3))
# 返回的分类标签向量
classLabelVector = []
# 行的索引值
index = 0
for line in arrayOLines:
# s.strip(rm),当rm空时,默认删除空白符(包括'\n','\r','\t',' ')
line = line.strip()
# 使用s.split(str="",num=string,cout(str))将字符串根据'\t'分隔符进行切片。
listFromLine = line.split('\t')
# 将数据前三列提取出来,存放到returnMat的NumPy矩阵中,也就是特征矩阵
returnMat[index, :] = listFromLine[0:3]
# 根据文本中标记的喜欢的程度进行分类,1代表不喜欢,2代表魅力一般,3代表极具魅力
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat, classLabelVector """
函数说明:对数据进行归一化 Parameters:
dataSet - 特征矩阵
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
""" def autoNorm(dataSet):
# 获得数据的最小值
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
# 最大值和最小值的范围
ranges = maxVals - minVals
# shape(dataSet)返回dataSet的矩阵行列数
normDataSet = np.zeros(np.shape(dataSet))
# 返回dataSet的行数
m = dataSet.shape[0]
# 原始值减去最小值
normDataSet = dataSet - np.tile(minVals, (m, 1))
# 除以最大和最小值的差,得到归一化数据
normDataSet = normDataSet / np.tile(ranges, (m, 1))
# 返回归一化数据结果,数据范围,最小值
return normDataSet, ranges, minVals """
函数说明:分类器测试函数 Parameters:
无
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值 """ def datingClassTest():
# 打开的文件名
filename = "datingTestSet.txt"
# 将返回的特征矩阵和分类向量分别存储到datingDataMat和datingLabels中
datingDataMat, datingLabels = file2matrix(filename)
# 取所有数据的百分之十
hoRatio = 0.10
# 数据归一化,返回归一化后的矩阵,数据范围,数据最小值
normMat, ranges, minVals = autoNorm(datingDataMat)
# 获得normMat的行数
m = normMat.shape[0]
# 百分之十的测试数据的个数
numTestVecs = int(m * hoRatio)
# 分类错误计数
errorCount = 0.0 for i in range(numTestVecs):
# 前numTestVecs个数据作为测试集,后m-numTestVecs个数据作为训练集
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :],
datingLabels[numTestVecs:m], 4)
print("分类结果:%d\t真实类别:%d" % (classifierResult, datingLabels[i]))
if classifierResult != datingLabels[i]:
errorCount += 1.0
print("错误率:%f%%" % (errorCount / float(numTestVecs) * 100)) """
函数说明:main函数 Parameters:
无
Returns:
无 """
if __name__ == '__main__':
datingClassTest()
六、使用算法:构建完整可用系统
我们可以给海伦一个小段程序,通过该程序海伦会在约会网站上找到某个人并输入他的信息。程序会给出她对男方喜欢程度的预测值。
# -*- coding: UTF-8 -*- import numpy as np
import operator """
函数说明:kNN算法,分类器 Parameters:
inX - 用于分类的数据(测试集)
dataSet - 用于训练的数据(训练集)
labes - 分类标签
k - kNN算法参数,选择距离最小的k个点
Returns:
sortedClassCount[0][0] - 分类结果
""" def classify0(inX, dataSet, labels, k):
# numpy函数shape[0]返回dataSet的行数
dataSetSize = dataSet.shape[0]
# 在列向量方向上重复inX共1次(横向),行向量方向上重复inX共dataSetSize次(纵向)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
# 二维特征相减后平方
sqDiffMat = diffMat ** 2
# sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
# 开方,计算出距离
distances = sqDistances ** 0.5
# 返回distances中元素从小到大排序后的索引值
sortedDistIndices = distances.argsort()
# 定一个记录类别次数的字典
classCount = {}
for i in range(k):
# 取出前k个元素的类别
voteIlabel = labels[sortedDistIndices[i]]
# dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
# 计算类别次数
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# python3中用items()替换python2中的iteritems()
# key=operator.itemgetter(1)根据字典的值进行排序
# key=operator.itemgetter(0)根据字典的键进行排序
# reverse降序排序字典
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# 返回次数最多的类别,即所要分类的类别
return sortedClassCount[0][0] """
函数说明:打开并解析文件,对数据进行分类:1代表不喜欢,2代表魅力一般,3代表极具魅力 Parameters:
filename - 文件名
Returns:
returnMat - 特征矩阵
classLabelVector - 分类Label向量
""" def file2matrix(filename):
# 打开文件
fr = open(filename)
# 读取文件所有内容
arrayOLines = fr.readlines()
# 得到文件行数
numberOfLines = len(arrayOLines)
# 返回的NumPy矩阵,解析完成的数据:numberOfLines行,3列
returnMat = np.zeros((numberOfLines, 3))
# 返回的分类标签向量
classLabelVector = []
# 行的索引值
index = 0
for line in arrayOLines:
# s.strip(rm),当rm空时,默认删除空白符(包括'\n','\r','\t',' ')
line = line.strip()
# 使用s.split(str="",num=string,cout(str))将字符串根据'\t'分隔符进行切片。
listFromLine = line.split('\t')
# 将数据前三列提取出来,存放到returnMat的NumPy矩阵中,也就是特征矩阵
returnMat[index, :] = listFromLine[0:3]
# 根据文本中标记的喜欢的程度进行分类,1代表不喜欢,2代表魅力一般,3代表极具魅力
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat, classLabelVector """
函数说明:对数据进行归一化 Parameters:
dataSet - 特征矩阵
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
""" def autoNorm(dataSet):
# 获得数据的最小值
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
# 最大值和最小值的范围
ranges = maxVals - minVals
# shape(dataSet)返回dataSet的矩阵行列数
normDataSet = np.zeros(np.shape(dataSet))
# 返回dataSet的行数
m = dataSet.shape[0]
# 原始值减去最小值
normDataSet = dataSet - np.tile(minVals, (m, 1))
# 除以最大和最小值的差,得到归一化数据
normDataSet = normDataSet / np.tile(ranges, (m, 1))
# 返回归一化数据结果,数据范围,最小值
return normDataSet, ranges, minVals """
函数说明:通过输入一个人的三维特征,进行分类输出 Parameters:
无
Returns:
无
""" def classifyPerson():
# 输出结果
resultList = ['讨厌', '有些喜欢', '非常喜欢']
# 三维特征用户输入
precentTats = float(input("玩视频游戏所耗时间百分比:"))
ffMiles = float(input("每年获得的飞行常客里程数:"))
iceCream = float(input("每周消费的冰激淋公升数:"))
# 打开的文件名
filename = "datingTestSet.txt"
# 打开并处理数据
datingDataMat, datingLabels = file2matrix(filename)
# 训练集归一化
normMat, ranges, minVals = autoNorm(datingDataMat)
# 生成NumPy数组,测试集
inArr = np.array([precentTats, ffMiles, iceCream])
# 测试集归一化
norminArr = (inArr - minVals) / ranges
# 返回分类结果
classifierResult = classify0(norminArr, normMat, datingLabels, 3)
# 打印结果
print("你可能%s这个人" % (resultList[classifierResult - 1])) """
函数说明:main函数 Parameters:
无
Returns:
无
"""
if __name__ == '__main__':
classifyPerson()
机器学习读书笔记(二)使用k-近邻算法改进约会网站的配对效果的更多相关文章
- 使用K近邻算法改进约会网站的配对效果
1 定义数据集导入函数 import numpy as np """ 函数说明:打开并解析文件,对数据进行分类:1 代表不喜欢,2 代表魅力一般,3 代表极具魅力 Par ...
- k-近邻(KNN)算法改进约会网站的配对效果[Python]
使用Python实现k-近邻算法的一般流程为: 1.收集数据:提供文本文件 2.准备数据:使用Python解析文本文件,预处理 3.分析数据:可视化处理 4.训练算法:此步骤不适用与k——近邻算法 5 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- 【Machine Learning in Action --2】K-近邻算法改进约会网站的配对效果
摘自:<机器学习实战>,用python编写的(需要matplotlib和numpy库) 海伦一直使用在线约会网站寻找合适自己的约会对象.尽管约会网站会推荐不同的人选,但她没有从中找到喜欢的 ...
- 使用k-近邻算法改进约会网站的配对效果
---恢复内容开始--- < Machine Learning 机器学习实战>的确是一本学习python,掌握数据相关技能的,不可多得的好书!! 最近邻算法源码如下,给有需要的入门者学习, ...
- 机器学习实战1-2.1 KNN改进约会网站的配对效果 datingTestSet2.txt 下载方法
今天读<机器学习实战>读到了使用k-临近算法改进约会网站的配对效果,道理我都懂,但是看到代码里面的数据样本集 datingTestSet2.txt 有点懵,这个样本集在哪里,只给了我一个文 ...
- KNN算法项目实战——改进约会网站的配对效果
KNN项目实战——改进约会网站的配对效果 1.项目背景: 海伦女士一直使用在线约会网站寻找适合自己的约会对象.尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人.经过一番总结,她发现自己交往过的人可 ...
- kNN分类算法实例1:用kNN改进约会网站的配对效果
目录 实战内容 用sklearn自带库实现kNN算法分类 将内含非数值型的txt文件转化为csv文件 用sns.lmplot绘图反映几个特征之间的关系 参考资料 @ 实战内容 海伦女士一直使用在线约会 ...
- k-近邻算法-优化约会网站的配对效果
KNN原理 1. 假设有一个带有标签的样本数据集(训练样本集),其中包含每条数据与所属分类的对应关系. 2. 输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较. a. 计算新 ...
随机推荐
- ORA-00600: internal error code, arguments: [4194], [53], [41], [], [], [], [], []
真的不动,关闭同事开发测试IBM 3650server它直接关系到电源插头行??? 第二天加点重新启动之后oracle 打开报错ORA-00600: internal error code, argu ...
- .net reactor 学习系列(三)---.net reactor代码自动操作相关保护功能
原文:.net reactor 学习系列(三)---.net reactor代码自动操作相关保护功能 接上篇,上篇已经学习了界面的各种功能以及各种配置,这篇准备学习下代码控制许可证. ...
- 网络库Asio交叉编译(Linux生成ARM)
1. Asio是一个跨平台的C++库,用于网络和底层I/O编程.Asio使用先进的C++方式提供了一系列的异步模型 2. 官方网址:http://think-async.com 3. 由于Asio库 ...
- 2017 JavaScript 开发者的学习图谱
码云项目推荐 前端框架类 1.项目名称: 基于 Vue.js 的 UI 组件库 iView 项目简介:iView 是一套基于 Vue.js 的 UI 组件库,主要服务于 PC 界面的中后台产品. 特性 ...
- wpf 绑定数据无法更新ui控件可能存在的问题
BindingMode的枚举值有: ① OneWay ② TwoWay ③ OneTime:根据源端属性值设置目标属性值,之后的改变会被忽略,除非调用BindingExpression.UpdateT ...
- github网页
GitHub主页 创建仓库 想必大家都有自己的Github账号吧,没有的可以到GitHub官网注册账号,注册完后,我们来下一步,在我们的GitHub上面右上角的New repository来创建一个仓 ...
- C#串口控制舵机、arduino源码 及C#源码及界面
原文 C#串口控制舵机.arduino源码 及C#源码及界面 1.舵机原理简介 控制信号由接收机的通道进入信号调制芯片,获得直流偏置电压.它内部有一个基准电路,产生周期为20ms,宽度为1.5ms的基 ...
- Android零基础入门第35节:Android中基于回调的事件处理
原文:Android零基础入门第35节:Android中基于回调的事件处理 通过前面两期掌握了Android中基于监听的事件处理的五种形式,那么本期一起来学习Android中基于回调的事件处理. 一. ...
- UWP入门(一) -- 先写几个简单控件简单熟悉下(别看这个)
原文:UWP入门(一) -- 先写几个简单控件简单熟悉下(别看这个) 1. MainPage.xmal <Grid Background="{ThemeResource Applica ...
- 【UWP开发】uwp应用安装失败
原文:[UWP开发]uwp应用安装失败 编译出了uwp应用.appx之后双击打开,报错你需要为此应用包而安装的新证书,或者是带有受信任证书的新应用包.系统管理员或应用开发人员可以提供帮助.证书链在不受 ...