RocksDB线程局部缓存
概述
在开发过程中,我们经常会遇到并发问题,解决并发问题通常的方法是加锁保护,比如常用的spinlock,mutex或者rwlock,当然也可以采用无锁编程,对实现要求就比较高了。对于任何一个共享变量,只要有读写并发,就需要加锁保护,而读写并发通常就会面临一个基本问题,写阻塞读,或则写优先级比较低,就会出现写饿死的现象。这些加锁的方法可以归类为悲观锁方法,今天介绍一种乐观锁机制来控制并发,每个线程通过线程局部变量缓存共享变量的副本,读不加锁,读的时候如果感知到共享变量发生变化,再利用共享变量的最新值填充本地缓存;对于写操作,则需要加锁,通知所有线程局部变量发生变化。所以,简单来说,就是读不加锁,读写不冲突,只有写写冲突。这个实现逻辑来源于Rocksdb的线程局部缓存实现,下面详细介绍Rocksdb的线程局部缓存ThreadLocalPtr的原理。
线程局部存储(TLS)
简单介绍下线程局部变量,线程局部变量就是每个线程有自己独立的副本,各个线程对其修改相互不影响,虽然变量名相同,但存储空间并没有关系。一般在linux 下,我们可以通过以下三个函数来实现线程局部存储创建,存取功能。
int pthread_key_create(pthread_key_t *key, void (*destr_function) (void*)),
int pthread_setspecific(pthread_key_t key, const void *pointer) ,
void * pthread_getspecific(pthread_key_t key)
ThreadLocalPtr类
有时候,我们并不想要各个线程独立的变量,我们仍然需要一个全局变量,线程局部变量只是作为全局变量的缓存,用以缓解并发。在RocksDB中ThreadLocalPtr这个类就是来干这个事情的。ThreadLocalPtr类包含三个内部类,ThreadLocalPtr::StaticMeta,ThreadLocalPtr::ThreadData和ThreadLocalPtr::Entry。其中StaticMeta是一个单例,管理所有的ThreadLocalPtr对象,我们可以简单认为一个ThreadLocalPtr对象,就是一个线程局部存储(ThreadLocalStorage)。但实际上,全局我们只定义了一个线程局部变量,从StaticMeta构造函数可见一斑。那么全局需要多个线程局部缓存怎么办,实际上是在局部存储空间做文章,线程局部变量实际存储的是ThreadData对象的指针,而ThreadData里面包含一个数组,每个ThreadLocalPtr对象有一个独立的id,在其中占有一个独立空间。获取某个变量局部缓存时,传入分配的id即可,每个Entry中ptr指针就是对应变量的指针。
ThreadLocalPtr::StaticMeta::StaticMeta() : next_instance_id_(), head_(this) {
if (pthread_key_create(&pthread_key_, &OnThreadExit) != ) {
abort();
}
......
}
void* ThreadLocalPtr::StaticMeta::Get(uint32_t id) const {
auto* tls = GetThreadLocal();
return tls->entries[id].ptr.load(std::memory_order_acquire);
}
struct Entry {
Entry() : ptr(nullptr) {}
Entry(const Entry& e) : ptr(e.ptr.load(std::memory_order_relaxed)) {}
std::atomic<void*> ptr;
};
整体结构如下:每个线程有一个线程局部变量ThreadData,里面包含了一组ThreadLocalPtr的指针,对应的是多个变量,同时ThreadData之间相互通过指针串联起来,这个非常重要,因为执行写操作时,写线程需要修改所有thread的局部缓存值来通知共享变量发生变化了。
---------------------------------------------------
| | instance | instance | instnace |
---------------------------------------------------
| thread | void* | void* | void* | <- ThreadData
---------------------------------------------------
| thread | void* | void* | void* | <- ThreadData
---------------------------------------------------
| thread | void* | void* | void* | <- ThreadData struct ThreadData {
explicit ThreadData(ThreadLocalPtr::StaticMeta* _inst)
: entries(), inst(_inst) {}
std::vector<Entry> entries;
ThreadData* next;
ThreadData* prev;
ThreadLocalPtr::StaticMeta* inst;
};
读写无并发冲突
现在说到最核心的问题,我们如何实现利用TLS来实现本地局部缓存,做到读不上锁,读写无并发冲突。读、写逻辑和并发控制主要通过ThreadLocalPtr中通过3个关键接口Swap,CompareAndSwap和Scrape实现。对于ThreadLocalPtr< Type* > 变量来说,在具体的线程局部存储中,会保存3中不同类型的值:
1). 正常的Type* 类型指针;
2). 一个Type*类型的Dummy变量,记为InUse;
3). nullptr值,记为obsolote;
读线程通过Swap接口来获取变量内容,写线程则通过Scrape接口,遍历并重置所有ThreadData为(obsolote)nullptr,达到通知其他线程局部缓存失效的目的。下次读线程再读取时,发现获取的指针为nullptr,就需要重新构造局部缓存。
//获取某个id对应的局部缓存内容,每个ThreadLocalPtr对象有单独一个id,通过单例StaticMeta对象管理。
void* ThreadLocalPtr::StaticMeta::Swap(uint32_t id, void* ptr) {
//获取本地局部缓存
auto* tls = GetThreadLocal(); return tls->entries[id].ptr.exchange(ptr, std::memory_order_acquire);
} bool ThreadLocalPtr::StaticMeta::CompareAndSwap(uint32_t id, void* ptr,
void*& expected) {
//获取本地局部缓存
auto* tls = GetThreadLocal();
return tls->entries[id].ptr.compare_exchange_strong(
expected, ptr, std::memory_order_release, std::memory_order_relaxed);
} //将所有管理的对象指针设置为nullptr,将过期的指针返回,供上层释放,
//下次进行从局部线程栈获取时,发现内容为nullptr,则重新申请对象。
void ThreadLocalPtr::StaticMeta::Scrape(uint32_t id, std::vector<void*>* ptrs, void* const replacement) {
MutexLock l(Mutex());
for (ThreadData* t = head_.next; t != &head_; t = t->next) {
if (id < t->entries.size()) {
void* ptr =
t->entries[id].ptr.exchange(replacement, std::memory_order_acquire);
if (ptr != nullptr) {
//搜集各个线程缓存,进行解引用,必要时释放内存
ptrs->push_back(ptr);
}
}
}
} //初始化,或者被替换为nullptr后,说明缓存对象已经过期,需要重新申请。
ThreadData* ThreadLocalPtr::StaticMeta::GetThreadLocal() {
申请线程局部的ThreadData对象,通过StaticMeta对象管理成一个双向链表,每个instance对象管理一组线程局部对象。
if (UNLIKELY(tls_ == nullptr)) {
auto* inst = Instance();
tls_ = new ThreadData(inst);
{
// Register it in the global chain, needs to be done before thread exit
// handler registration
MutexLock l(Mutex());
inst->AddThreadData(tls_);
}
return tls_;
}
}
读操作包括两部分,Get和Release,这里面除了从TLS中获取缓存,还涉及到一个释放旧对象内存的问题。Get时,利用InUse对象替换TLS对象,Release时再将TLS对象替换回去,读写没有并发的场景比较简单,如下图,其中TLS Object代表本地线程局部缓存,GlobalObject是全局共享变量,对所有线程可见。
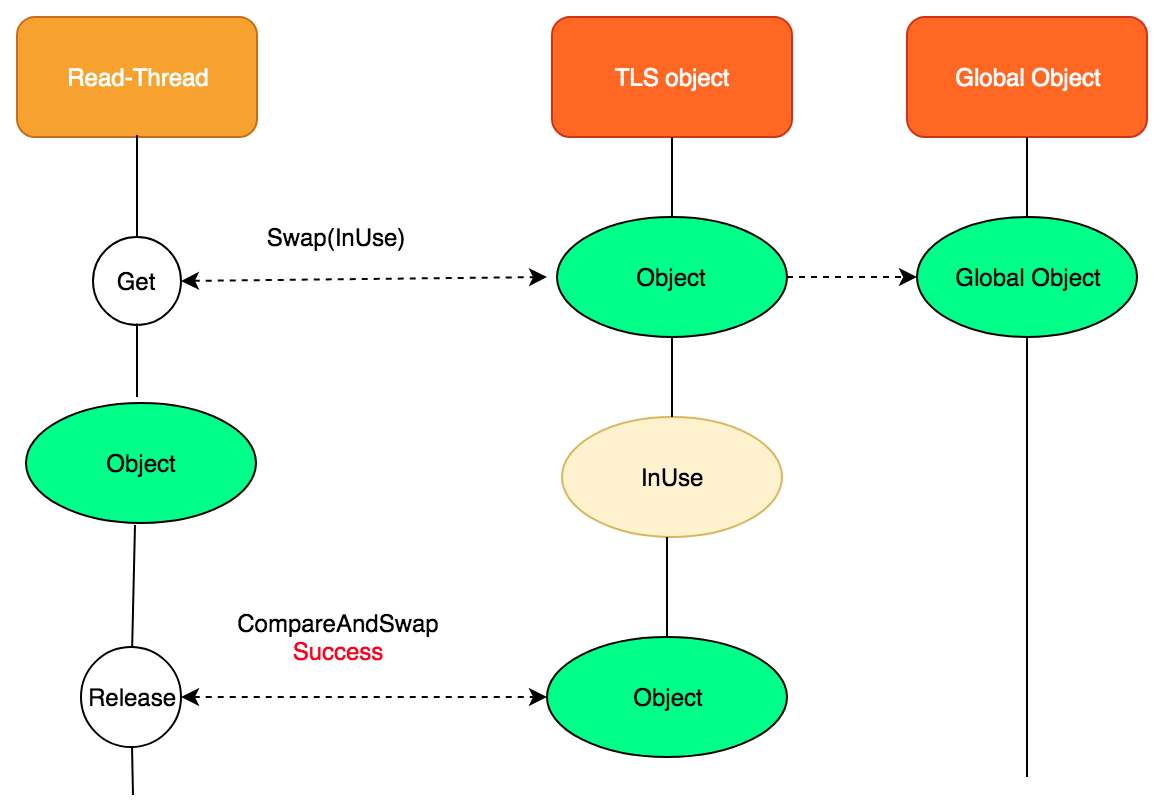
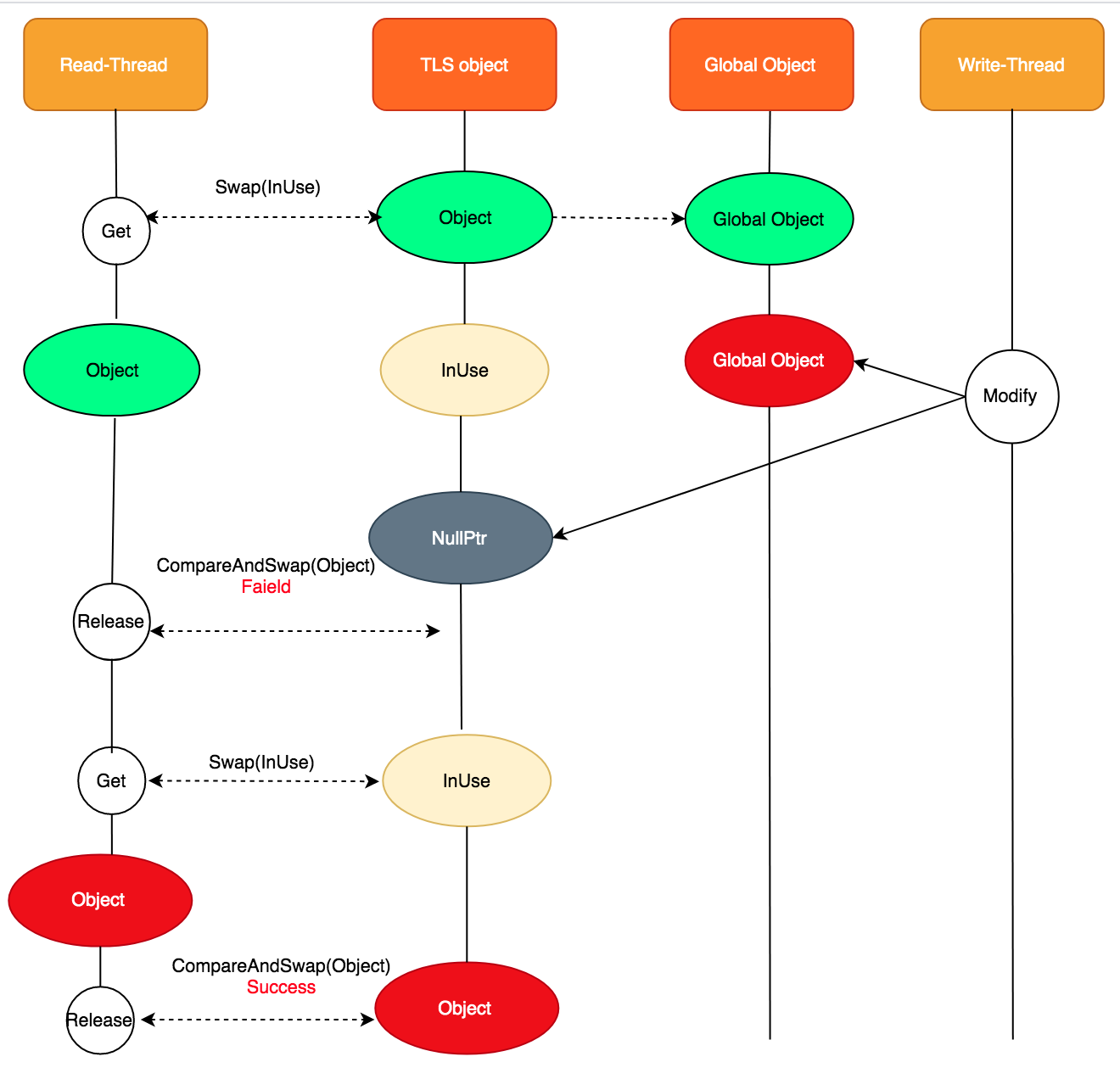
下面我们再看看读写有并发的场景,读线程读到TLS object后,写线程修改了全局对象,并且遍历对所有的TLS object进行修改,设置nullptr。在此之后,读线程进行Release时,compareAndSwap失败,感知到使用的object已经过期,执行解引用,必要时释放内存。当下次再次Get object时,发现TLS object为nullptr,就会使用当前最新的object,并在使用完成后,Release阶段将object填回到TLS。
应用场景
从前面的分析来看,TLS作为cache,仍然需要一个全局变量,全局变量保持最新值,而TLS则可能存在滞后,这就要求我们的使用场景不要求读写要实时严格一致,或者能容忍多版本。全局变量和局部缓存有交互,交互逻辑是,全局变量变化后,局部线程要能及时感知到,但不需要实时。允许读写并发,即允许读的时候,使用旧值读,待下次读的时候,再获取到新值。Rocksdb中的superversion管理则符合这种使用场景,swich/flush/compaction会产生新的superversion,读写数据时,则需要读supversion。往往读写等前台操作相对于switch/flush/compaction更频繁,所以读superversion比写superversion比例更高,而且允许系统中同时存留多个superversion。
每个线程可以拿superversion进行读写,若此时并发有flush/compaction产生,会导致superversion发生变化,只要后续再次读取superversion时,能获取到最新即可。细节上来说,扩展到应用场景,一般在读场景下,我们需要获取snapshot,并借助superversion信息来确认这次读取要读哪些物理介质(mem,imm,L0,L1...LN)。
1).获取snapshot后,拿superversion之前,其它线程做了flush/compaction导致superversion变化
这种情况下,可以拿到最新的superversion。
2).获取snapshot后,拿superversion之后,其它线程做了flush/compaction导致superversion变化
这种情况下,虽然superversion比较旧,但是依然包含了所有snapshot需要的数据。那么为什么需要及时获取最新的superversion,这里主要是为了回收废弃的sst文件和memtable,提高内存和存储空间利用率。
总结
RocksDB的线程局部缓存是一个很不错的实现,用户使用局部缓存可以大大降低读写并发冲突,尤其在读远大于写的场景下,整个缓存维护代价也比较低,只有写操作时才需要锁保护。只要系统中允许共享变量的多版本存在,并且不要求实时保证一致,那么线程局部缓存是提升并发性能的一个不错的选择。
RocksDB线程局部缓存的更多相关文章
- 线程TLAB局部缓存区域(Thread Local Allocation Buffer)
TLAB(Thread Local Allocation Buffer) 1,堆是JVM中所有线程共享的,因此在其上进行对象内存的分配均需要进行加锁,这也导致了new对象的开销是比较大的 2,Sun ...
- asp.net MVC3的局部缓存页面PartialCache.cshtml
MVC3及以上有了PartialCache.cshtml局部缓存的方式,具体实现: 新建一个PartialCache.cshtml的页面,在控制器上写上如下代码: [OutputCache(Durat ...
- 使用Varnish+ESI实现静态页面的局部缓存(思路篇)
使用Varnish+ESI实现静态页面的局部缓存(思路篇) 页面静态化是搭建高性能网站必用的招式之一,页面静态化可以有效提升系统响应速度,同时也有利于搜索引擎优化.但在页面静态化后,静态页面之间包含( ...
- Thinkphp 缓存和静态缓存局部缓存设置
1.S方法缓存设置 if(!$rows = S('indexBlog')){ //*$rows = S('indexBlog') $rows = D('blog')->select(); S(' ...
- 并发基础(十) 线程局部副本ThreadLocal之正解
本文将介绍ThreadLocal的用法,并且指出大部分人对ThreadLocal 的误区. 先来看一下ThreadLocal的API: 1.构造方法摘要 ThreadLocal(): 创建一个线程 ...
- ehcache 页面整体缓存和局部缓存
页面缓存是否有必要?. 这样说吧,几乎所有的网站的首页都是访问率最高的,而首页上的数据来源又是非常广泛的,大多数来自不同的对象,而且有可能来自不同的db ,所以给首页做缓存是很必要的.那么主页的缓存策 ...
- ehcache实现页面整体缓存和页面局部缓存
之前写过spring cache和ehcache的基本介绍和注解实现缓存管理,今天记录下web项目的页面缓存技术. 页面缓存是否有必要?. 这样说吧,几乎所有的网站的首页都是访问率最高的,而首页上的数 ...
- ASP.NET缓存全解析3:页面局部缓存 转自网络原文作者李天平
有时缓存整个页面是不现实的,因为页的某些部分可能在每次请求时都需要变化.在这些情况下,只能缓存页的一部分.顾名思义,页面部分缓存是将页面部分内容保存在内存中以便响应用户请求,而页面其他部分内容则为动态 ...
- java线程与缓存
如果在你的服务中用了一些第三方的服务,最好使用缓存配合线程的方式去访问第三方的服务,以免引发线程安全问题,因为第三方的服务你不知道人家对于多线程是如何处理的,所以我们要在自己的程序中做一些线程安全的处 ...
随机推荐
- python3虚拟环境中解决 ModuleNotFoundError: No module named '_ssl'
前提是已经安装了openssl 问题 当我在python3虚拟环境中导入ssl模块时报错,报错如下: (py3) [root@localhost Python-3.6.3]# python3 Pyth ...
- 【win10主机】连接virtualbox上【32位winXP系统虚拟机】上启动的mysql
问题Q: 在virtualbox上启动winXP系统虚拟机后,启动含oa项目的tomcat,数据库服务也运行起来了,虚拟机上连接无误: 在上一篇<主机访问 虚拟机启动的项目>基础上,尝试连 ...
- python+unittest框架第四天unittest之批量执行案例
今天开始批量执行用例~,场景是这样的: 工作中我们可能有多个模块文件(.py)这些文件根据不同的业务类型或功能,测试案例分布在不同的模块文件下.前面的小示例中,我们的测试用例都是在一个文件中,直接运行 ...
- application.yml 增加数据库连接,重启日志卡死
SpringBoot引入JPA,application.ymlapplication.yml增加数据库链接参数,启动卡死,日志没有动,如下图 折腾好久,后面发现用 Maven的package 过程中 ...
- nodeJS 中mongoose操作分页
开始前先聊聊五毛钱的: 好久没写了,可能是因为懒(哎),写这个是好事,既帮助了自己,巩固一下知识,也可以让别人给自己纠错纠错,三月份接触到了node,先是跟着一些教程写了一些小实例,感觉自己就喜欢上了 ...
- python学习之并发编程
目录 一.并发编程之多进程 1.multiprocessing模块介绍 2.Process类的介绍 3.Process类的使用 3.1 创建开启子进程的两种方式 3.2 获取进程pid 3.3验证进程 ...
- [转]Android ImageView的scaleType属性与adjustViewBounds属性
Android ImageView的scaleType属性与adjustViewBounds属性 ImageView的scaleType的属性有好几种,分别是matrix(默认).center.c ...
- 约瑟夫环问题:有n个人围成一圈,顺序排号。从第一个人开始报数(从1到3报数),凡报到3的人退出圈子,问最后留下的是原来第几号的那位。
首先,我最大的学习来源不是百度而是我群友~~在这里表白一波我热爱学习的群友们!然后今天群里突然有人提出了题目的这个问题:有n个人围成一圈,顺序排号.从第一个人开始报数(从1到3报数),凡报到3的人退出 ...
- Lambada和linq查询数据库的比较
1. 查询Student表中的所有记录的Sname.Ssex和Class列.select sname,ssex,class from studentLinq: from s in Student ...
- electron-vue-webpack引入bootstrap多实例问题Multiple instances of Vue detected!
在node modules里面找到electron-webpack目录, 修改out->main.js白名单内容,增加 whiteListedModules.add("bootstra ...