快速排序方法——python实现
参考博文:http://www.cnblogs.com/jingmoxukong/p/4302891.html
快速排序是一种交换排序。
快速排序由C. A. R. Hoare在1962年提出。
它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分:分割点左边都是比它小的数,右边都是比它大的数。
它的基本流程是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
算法结构如图所示:
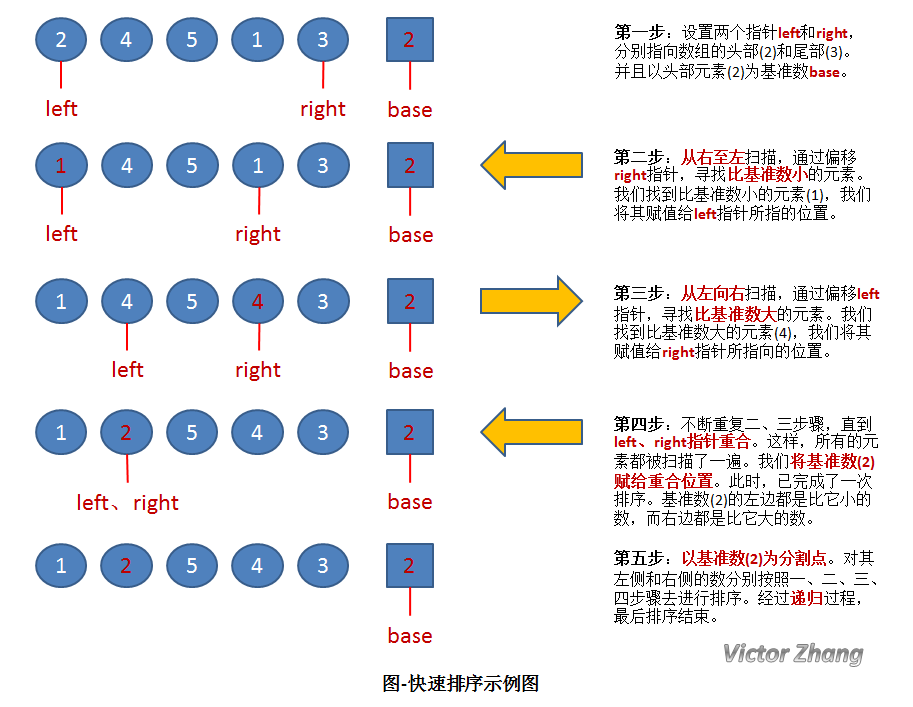
图中,演示了快速排序的处理过程:
初始状态为一组无序的数组:2、4、5、1、3。
经过以上操作步骤后,完成了第一次的排序,得到新的数组:1、2、5、4、3。
新的数组中,以2为分割点,左边都是比2小的数,右边都是比2大的数。
因为2已经在数组中找到了合适的位置,所以不用再动。
2左边的数组只有一个元素1,所以显然不用再排序,位置也被确定。(注:这种情况时,left指针和right指针显然是重合的。因此在代码中,我们可以通过设置判定条件left必须小于right,如果不满足,则不用排序了)。
而对于2右边的数组5、4、3,设置left指向5,right指向3,开始继续重复图中的一、二、三、四步骤,对新的数组进行排序。
在此采用python语言实现,代码如下:
example = [1,3,4,5,2,6,9,7,8,0] a = 0
b = len(example)-1 def quickSort(number,head,tail):
if (head<tail):
base = division(number,head,tail)
#print(number[base],"\n")
quickSort(number,head,base-1)
quickSort(number,base+1,tail)
else:
print(number) def division(number,head,tail):
base = number[head]
while(head<tail):
while(head<tail and number[tail]>=base):
tail-=1
number[head] = number[tail]
while (head<tail and number[head]<=base):
head+=1
number[tail] = number[head]
number[head] = base
return head if __name__ == '__main__':
quickSort(example,a,b)
运行结果如下图:

- 时间复杂度与空间复杂度
当数据有序时,以第一个关键字为基准分为两个子序列,前一个子序列为空,此时执行效率最差。
而当数据随机分布时,以第一个关键字为基准分为两个子序列,两个子序列的元素个数接近相等,此时执行效率最好。
所以,数据越随机分布时,快速排序性能越好;数据越接近有序,快速排序性能越差。
快速排序在每次分割的过程中,需要 1 个空间存储基准值。而快速排序的大概需要 Nlog2N次的分割处理,所以占用空间也是 Nlog2N 个。
快速排序方法——python实现的更多相关文章
- python的str,unicode对象的encode和decode方法, Python中字符编码的总结和对比bytes和str
python_2.x_unicode_to_str.py a = u"中文字符"; a.encode("GBK"); #打印: '\xd6\xd0\xce\xc ...
- 经典排序方法 python
数据的排序是在解决实际问题时经常用到的步骤,也是数据结构的考点之一,下面介绍10种经典的排序方法. 首先,排序方法可以大体分为插入排序.选择排序.交换排序.归并排序和桶排序四大类,其中,插入排序又分为 ...
- 排序算法之快速排序的python实现
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序. 快速排序算法的工作原理如下: 1. 从数列中挑出一个元 ...
- 矩阵或多维数组两种常用实现方法 - python
在python中,实现多维数组或矩阵,有两种常用方法: 内置列表方法和numpy 科学计算包方法. 下面以创建10*10矩阵或多维数组为例,并初始化为0,程序如下: # Method 1: list ...
- 快速排序(python实现)
算法导论上的快速排序采用分治算法,步骤如下: 1.选取一个数字作为基准,可选取末位数字 2.将数列第一位开始,依次与此数字比较,如果小于此数,将小数交换到左边,最后达到小于基准数的在左边,大于基准数的 ...
- 实现LRU的两种方法---python实现
这也是豆瓣2016年的一道笔试题... 参考:http://www.3lian.com/edu/2015/06-25/224322.html LRU(least recently used)就不做过多 ...
- python扩展实现方法--python与c混和编程 转自:http://www.cnblogs.com/btchenguang/archive/2012/09/04/2670849.html
前言 需要扩展Python语言的理由: 创建Python扩展的步骤 1. 创建应用程序代码 2. 利用样板来包装代码 a. 包含python的头文件 b. 为每个模块的每一个函数增加一个型如PyObj ...
- python扩展实现方法--python与c混和编程
前言 需要扩展Python语言的理由: 创建Python扩展的步骤 1. 创建应用程序代码 2. 利用样板来包装代码 a. 包含python的头文件 b. 为每个模块的每一个函数增加一个型如PyObj ...
- Python同时向控制台和文件输出日志logging的方法 Python logging模块详解
Python同时向控制台和文件输出日志logging的方法http://www.jb51.net/article/66756.htm 1 #-*- coding:utf-8 -*- 2 import ...
随机推荐
- git报错,远程克隆和更新不下来解决方法
报错: error: RPC failed; curl 18 transfer closed with outstanding read data remainingfatal: The remote ...
- Mysql学习笔记整理之选用B+tree结构
为什么mysql不使用平衡二叉树? 数据处的深度决定着他的IO操作次数,IO操作耗时大 每一个磁盘块保存的数据量太小 B+Tree和B-Tree的区别? B+树几点关键字搜索采用闭合区间 B+树非叶节 ...
- 品Spring:实现bean定义时采用的“先进生产力”
前景回顾 当我们把写好的业务代码交给Spring之后,Spring都会做些什么呢? 仔细想象一下,再稍微抽象一下,Spring所做的几乎全部都是: “bean的实例化,bean的依赖装配,bean的初 ...
- 第八届蓝桥杯java b组第八题
,标题:包子凑数 小明几乎每天早晨都会在一家包子铺吃早餐.他发现这家包子铺有N种蒸笼,其中第i种蒸笼恰好能放Ai个包子.每种蒸笼都有非常多笼,可以认为是无限笼. 每当有顾客想买X个包子,卖包子的大叔就 ...
- ASP.NET Core 3.0 WebApi中使用Swagger生成API文档简介
参考地址,官网:https://docs.microsoft.com/zh-cn/aspnet/core/tutorials/getting-started-with-swashbuckle?view ...
- Github 入门1 (下载git , 连接本地库与github仓库)
/* 本篇建立在以注册GitHub账号的前提下*/ (1) 下载 git https://www.git-scm.com // win10 可以直接红色箭头标识的 Download 2.22.0 ...
- Anaconda基本认识
Anaconda Distribution是执行Python数据科学和机器学习最简单的方法. 它包括250多种流行的数据科学软件包,以及适用于Windows,Linux和MacOS的conda软件包和 ...
- 阿里云搭建nginx + uWSGI 实现 django 项目
系统版本 CentOS/7 64位 1.安装使用python3 创建python3目录 sudo mkdir /usr/local/python3 进入python3目录 cd /usr/local/ ...
- Spring Environment的加载
这节介绍environment,默认环境变量的加载以及初始化. 之前在介绍spring启动过程讲到,第一步进行环境准备时就会初始化一个StandardEnvironment.下图为Environm ...
- java面向对象,数据类型深入
java程序员面试题day02 1.类和对象有什么区别? java中的类通过class关键字进行定义,代表的是一种抽象的集合,在类中可以定义各种的属性和方法,代表的是每一个类的实例的特定的数据和动作, ...