DFS和BFS的比较
DFS(Depth First Search,深度优先搜索)和BFS(Breadth First Search,广度优先搜索)是两种典型的搜索算法。下面通过一个实例来比较一下深度优先搜索和广度优先搜索的搜索过程。
【例1】马的行走路径
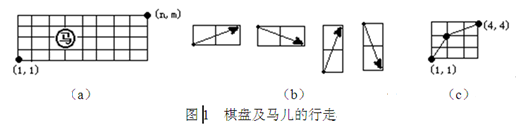
设有一个n*m的棋盘(2<=n<=50,2<=m<=50),在棋盘上任一点有一个中国象棋马,如图1(a)所示。马行走的规则为:(1)马走日字;(2)马只能向右走,即如图1(b)所示的4种走法。
编写一个程序,输入n和m,找出一条马从棋盘左下角(1,1)到右上角(n,m)的路径。例如:输入n=4、m=4时,输出路径 (1,1)->(2,3)->(4,4)。这一路经如图1(c)所示。若不存在路径,则输出"No!"
(1)编程思路。
将棋盘的横坐标规定为i,纵坐标规定为j,对于一个n×m的棋盘,i的值从1到n,j的值从1到m。棋盘上的任意点都可以用坐标(i,j)表示。
马有四种移动方向,每种移动方法用偏移值来表示,将这些偏移值分别保存在数组dx和dy中,可定义数组int dx[4]={1,1,2,2}和int dy[4]={-2,2,-1,1}。
定义数组int visit[51][51]标记某位置马儿是否已走过,初始时visit数组的所有元素值均为0,visit[i][j]=0表示坐标(i,j)处马儿未走过。同时为了后面输出路径方便,在标记visit[i][j]的值时,可以将其设置为其前一个位置的信息,例如visit[i][j] = x*100+y,它表示马儿由坐标(x,y)走到坐标(i,j)处。
(2)采用深度优先搜索编写的源程序。
#include <iostream>
using namespace std;
#define N 51
struct Node
{
int x;
int y;
};
int main()
{
int n,m;
int dx[4]={1,1,2,2};
int dy[4]={-2,2,-1,1};
int visit[N][N]={0};
Node s[N*N],cur,next; // s为栈
int top,i,x,y,t; // top为栈顶指针
cin>>n>>m;
top=-1; // 栈S初始化
cur.x=1; cur.y=1;
visit[1][1]=-1; // 点(1,1)为出发点,无前驱结点
s[++top]=cur; // 初始结点入栈;
bool flag= false; // 置搜索成功标志flag为假
while(top>=0 && !flag) // 栈不为空
{
cur=s[top--]; // 栈顶元素出栈
if (cur.x==n && cur.y==m)
{
flag=true;
x=n; y=m;
while (visit[x][y]!=-1)
{
cout<<"("<<x<<","<<y<<") <-- ";
t=visit[x][y];
x=t/100;
y=t%100;
}
cout<<"(1,1)"<<endl;
break;
}
for (i=0;i<4;i++)
{
x=cur.x+dx[i]; y=cur.y+dy[i];
if(x >=1 && x<=n && y>=0 && y<=m && visit[x][y]==0)
{
visit[x][y] = (cur.x)*100+cur.y; // 映射保存前驱结点信息
next.x=x; next.y=y; // 由cur扩展出新结点next
s[++top]=next; // next结点入栈
}
}
}
if (!flag)
cout<<"No path!"<<endl;
return 0;
}
为理解深度优先搜索的结点访问顺序,可以在上面源程序中的出栈语句后加上一条语句
cout<<"("<<cur.x<<","<<cur.y<<") -- "; 输出结点的出栈访问顺序。
(3)DFS的搜索过程。
以输入5,5为例,用树形结构表示马可能走的所有过程(如下图),求从起点到终点的路径,实际上就是从根结点开始搜索这棵树。
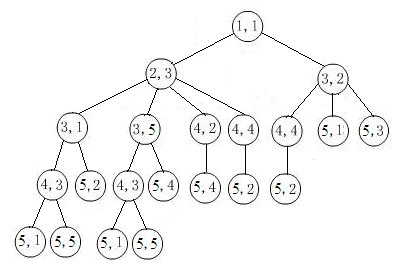
马从(1,1)开始,按深度优先搜索法,扩展出两个结点(2,3)和(3,2)依次入栈,之后(3,2)出栈,即走一步到达(3,2),判断是否到达终点,若没有,则继续往前走,扩展出结点(4,4)、(5,1)、(5,3)依次入栈,再走一步到达(5,3),没有到达终点,继续往前走,(5,3)的下一步所走的位置不在棋盘上,则另选一条路径再走;(5,1)出栈,即走到(5,1);…,直到到达(5,5),搜索过程结束。
以输入5,5为例,输出的深度优先访问顺序为:
(1,1) -- (3,2) -- (5,3) -- (5,1) -- (4,4) -- (5,2) -- (2,3) -- (4,2) -- (5,4) -- (3,5) -- (4,3) -- (5,5)。
(4)采用广度优先搜索编写的源程序。
#include <iostream>
using namespace std;
#define N 51
struct Node
{
int x;
int y;
};
int main()
{
int n,m;
int dx[4]={1,1,2,2};
int dy[4]={-2,2,-1,1};
int visit[N][N]={0};
Node q[N*N],cur,next; // q为队列
int front,rear,i,x,y,t; // front为队头指针,rear队尾指针
cin>>n>>m;
front=rear=0; // 队列q初始化
cur.x=1; cur.y=1;
visit[1][1]=-1; // 点(1,1)为出发点,无前驱结点
q[rear++]=cur; // 初始结点入队
bool flag= false; // 置搜索成功标志flag为假
cout<<"结点访问顺序为:";
while(rear!=front && !flag) // 队列不为空
{
cur=q[front++]; // 队头元素出队
cout<<"("<<cur.x<<","<<cur.y<<") -- ";
if (cur.x==n && cur.y==m)
{
flag=true;
x=n; y=m;
cout<<endl;
cout<<"行走路径为:";
while (visit[x][y]!=-1)
{
cout<<"("<<x<<","<<y<<") <-- ";
t=visit[x][y];
x=t/100;
y=t%100;
}
cout<<"(1,1)"<<endl;
break;
}
for (i=0;i<4;i++)
{
x=cur.x+dx[i]; y=cur.y+dy[i];
if(x >=1 && x<=n && y>=1 && y<=m && visit[x][y]==0)
{
visit[x][y] = (cur.x)*100+cur.y; // 映射保存前驱结点信息
next.x=x; next.y=y; // 由cur扩展出新结点next
q[rear++]=next; // next结点入栈
}
}
}
if (!flag)
cout<<"No path!"<<endl;
return 0;
}
(5)BFS的搜索过程。
结合上面的搜索图,广度优先搜索采用自上而下,从左到右的顺序搜素结点。因此,结点访问顺序为:(1,1) -- (2,3) -- (3,2) -- (3,1) -- (3,5) -- (4,2) -- (4,4) -- (5,1) -- (5,3) -- (4,3) -- (5,2) -- (5,4) -- (5,5)。
DFS和BFS的比较的更多相关文章
- Clone Graph leetcode java(DFS and BFS 基础)
题目: Clone an undirected graph. Each node in the graph contains a label and a list of its neighbors. ...
- 数据结构(12) -- 图的邻接矩阵的DFS和BFS
//////////////////////////////////////////////////////// //图的邻接矩阵的DFS和BFS ////////////////////////// ...
- 数据结构(11) -- 邻接表存储图的DFS和BFS
/////////////////////////////////////////////////////////////// //图的邻接表表示法以及DFS和BFS //////////////// ...
- 在DFS和BFS中一般情况可以不用vis[][]数组标记
开始学dfs 与bfs 时一直喜欢用vis[][]来标记有没有访问过, 现在我觉得没有必要用vis[][]标记了 看代码 用'#'表示墙,'.'表示道路 if(所有情况都满足){ map[i][j]= ...
- 图论中DFS与BFS的区别、用法、详解…
DFS与BFS的区别.用法.详解? 写在最前的三点: 1.所谓图的遍历就是按照某种次序访问图的每一顶点一次仅且一次. 2.实现bfs和dfs都需要解决的一个问题就是如何存储图.一般有两种方法:邻接矩阵 ...
- 图论中DFS与BFS的区别、用法、详解?
DFS与BFS的区别.用法.详解? 写在最前的三点: 1.所谓图的遍历就是按照某种次序访问图的每一顶点一次仅且一次. 2.实现bfs和dfs都需要解决的一个问题就是如何存储图.一般有两种方法:邻接矩阵 ...
- 数据结构基础(21) --DFS与BFS
DFS 从图中某个顶点V0 出发,访问此顶点,然后依次从V0的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和V0有路径相通的顶点都被访问到(使用堆栈). //使用邻接矩阵存储的无向图的深度 ...
- dfs和bfs的区别
详见转载博客:https://www.cnblogs.com/wzl19981116/p/9397203.html 1.dfs(深度优先搜索)是两个搜索中先理解并使用的,其实就是暴力把所有的路径都搜索 ...
- 邻接矩阵实现图的存储,DFS,BFS遍历
图的遍历一般由两者方式:深度优先搜索(DFS),广度优先搜索(BFS),深度优先就是先访问完最深层次的数据元素,而BFS其实就是层次遍历,每一层每一层的遍历. 1.深度优先搜索(DFS) 我一贯习惯有 ...
- 判断图连通的三种方法——dfs,bfs,并查集
Description 如果无向图G每对顶点v和w都有从v到w的路径,那么称无向图G是连通的.现在给定一张无向图,判断它是否是连通的. Input 第一行有2个整数n和m(0 < n,m < ...
随机推荐
- 离散时间信号常见函数的实现(matlab)
1. 单位样本序列 δ(n−n0)={1,n=n00,n≠n0 function [x, n] = impseq(n0, n1, n2) n = n1:n2; x = [n == n0]; 2. 单位 ...
- windows 系统文件 —— 特殊文件及文件类型
0. .mht 文件(MHTML) MHTML文件又称为聚合 HTML 文档.Web 档案或单一文件网页(聚合成单一文件).单个文件网页可将网站的所有元素(包括文本和图形)都保存到单个文件中.这种封装 ...
- blockchain_eth客户端安装 & geth使用 &批量转账(一)
这里是第一篇,主要讲eth客户端安装 eth官网 https://ethereum.org/ 国内有一个论坛内容挺多的,可以参考 http://ethfans.org/ eth客户端: eth客户端 ...
- 手把手教你开发Nginx模块
前面的哪些话 关于Nginx模块开发的博客资料,网上很多,很多.但是,每篇博客都只提要点,无法"step by step"照着做,对于初次接触Nginx开发的同学,只能像只盲目的蚂 ...
- Touch panel DTS 分析(MSM8994平台,Atmel 芯片)
Touch panel DTS 分析(MSM8994平台,Atmel 芯片) 在MSM8994平台,Touch panel的DTS写节点/kernel/arch/arm/boot/dts/qcom/m ...
- linux之tail -F命令异常file truncated
使用tail -F收集日志时,经常报出file truncated, 导致日志又重新读取.tail: `test.out' has appeared; following end of new fi ...
- EF CodeFirst的步骤
1 创建各个实体类 2 创建一个空数据模型,然后删除掉,为了引入Entity Framework和System.Data.Entity 3 为实体类增加标注 4 为实体增加导航属性 5 在App.co ...
- Linux ssh密钥自动登录 专题
在开发中,经常需要从一台主机ssh登陆到另一台主机去,每次都需要输一次login/Password,很繁琐.使用密钥登陆就可以不用输入用户名和密码了 实现从主机A免密码登陆到主机B(即把主机A的pub ...
- C#高性能大容量SOCKET并发(二):SocketAsyncEventArgs封装
原文:C#高性能大容量SOCKET并发(二):SocketAsyncEventArgs封装 1.SocketAsyncEventArgs介绍 SocketAsyncEventArgs是微软提供的高性能 ...
- WPF Aero Glass Window
原文:WPF Aero Glass Window 用法 Win7 DwmSetWindowAttribute function Win10 SetWindowCompositionAttribute ...