一文抽丝剥茧带你掌握复杂Gremlin查询的调试方法
摘要:Gremlin是图数据库查询使用最普遍的基础查询语言。Gremlin的图灵完备性,使其能够编写非常复杂的查询语句。对于复杂的问题,我们该如何编写一个复杂的查询?以及我们该如何理解已有的复杂查询?本文带你逐步抽丝剥茧,完成复杂查询的调试。
1. Gremlin简介
Gremlin是Apache TinkerPop 框架下的图遍历语言。Gremlin是一种函数式数据流语言,可以使得用户使用简洁的方式表述复杂的属性图(property graph)的遍历或查询。每个Gremlin遍历由一系列步骤(可以存在嵌套)组成,每一步都在数据流(data stream)上执行一个原子操作。
Gremlin是一种用于描述属性图中行走的语言。图形遍历分两个步骤进行。
1.1. 遍历源(TraversalSource)
开始节点选择(Start node selection)。所有遍历都从数据库中选择一组节点开始,这些节点充当图中行走的起点。Gremlin中的遍历是从TraversalSource开始的。 GraphTraversalSource提供了两种遍历方法。
- GraphTraversalSource.V(Object … ids):从图形的顶点开始遍历(如果未提供id,则为所有顶点)。
- GraphTraversalSource.E(Object … ids):从图形的边缘开始遍历(如果未提供id,则为所有边)。
1.2. 图遍历(GraphTraversal)
走图(Walking the graph)。从上一步中选择的节点开始,遍历会沿着图形的边行进,以根据节点和边的属性和类型到达相邻的节点。遍历的最终目标是确定遍历可以到达的所有节点。您可以将图遍历视为子图描述,必须执行该子图描述才能返回节点。
V()和E()的返回类型是GraphTraversal。 GraphTraversal维护许多返回GraphTraversal的方法。GraphTraversal支持功能组合。 GraphTraversal的每种方法都称为一个步骤(step),并且每个步骤都以五种常规方式之一调制(modulates)前一步骤的结果。
- map:将传入的遍历对象转换为另一个对象(S→E)。
- flatMap:将传入的遍历对象转换为其他对象的迭代器(S\subseteq E^*S⊆E∗)。
- filter:允许或禁止遍历器进行下一步(S→S∪∅)。
- sideEffect:允许遍历器保持不变,但在过程中产生一些计算上的副作用(S↬S)。
- branch:拆分遍历器并将其发送到遍历中的任意位置(S→{S1→E^*,…,S_n→E^*S1→E∗,…,Sn→E∗}→E*)。
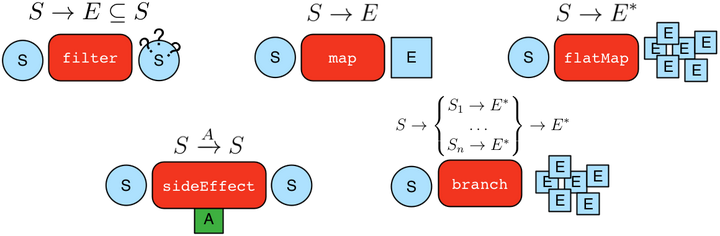
- GraphTraversal中几乎每个步骤都从MapStep,FlatMapStep,FilterStep,SideEffectStep或BranchStep扩展得到。
- 举例:找到makro认识的人
gremlin> g.V().has('name','marko').out('knows').values('name')
==>vadas
==>josh
1.3. Gremlin是图灵完备的(Turing Complete)
这也就时说任何复杂的问题,都可以用Gremlin描述。
下面就调试和编写复杂的gremlin查询,给出指导思路和方法论。
2. 复杂Gremlin查询的调试
Gremlin的查询都是由简单的查询组合成复杂的查询。所以对于复杂Gremlin查询可以分为以下三个步骤,并逐步迭代完成所有语句的验证,此方法同样适用编写复杂的Gremlin查询。
2.1. 迭代调试步骤
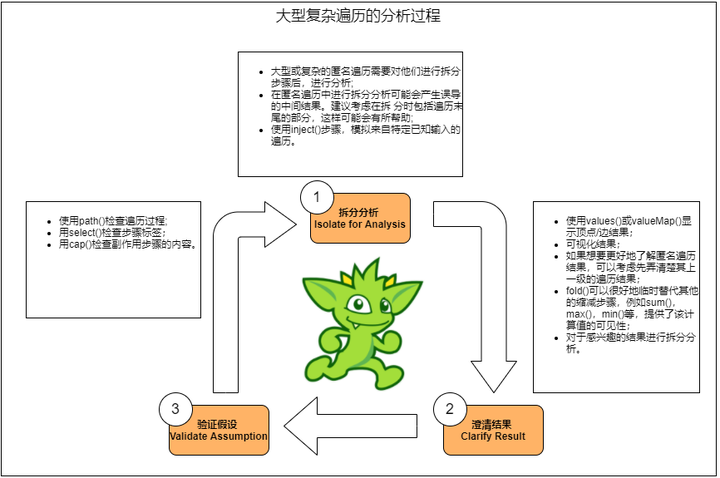
- 拆分分析步骤,划大为小,逐步求证;
- 输出分步骤的结果,明确步骤的具体输出内容;
- 对输出结果进行推导和检验。依据结果扩大或缩小分析步骤,回到步骤1继续,直到清楚所有结果。
- 注: 此方法参照Stephen Mallette gremlins-anatomy的分析逻辑和用例。
2.2. 用例
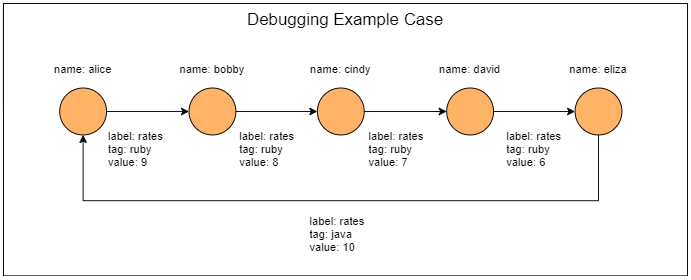
2.2.1. 图结构
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> g = graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin>g.addV().property('name','alice').as('a').
addV().property('name','bobby').as('b').
addV().property('name','cindy').as('c').
addV().property('name','david').as('d').
addV().property('name','eliza').as('e').
addE('rates').from('a').to('b').property('tag','ruby').property('value',9).
addE('rates').from('b').to('c').property('tag','ruby').property('value',8).
addE('rates').from('c').to('d').property('tag','ruby').property('value',7).
addE('rates').from('d').to('e').property('tag','ruby').property('value',6).
addE('rates').from('e').to('a').property('tag','java').property('value',10).
iterate()
gremlin> graph
==>tinkergraph[vertices:5 edges:5]
2.2.2. 查询语句
gremlin>g.V().has('name','alice').as('v').
repeat(outE().as('e').inV().as('v')).
until(has('name','alice')).
store('a').
by('name').
store('a').
by(select(all, 'v').unfold().values('name').fold()).
store('a').
by(select(all, 'e').unfold().
store('x').
by(union(values('value'), select('x').count(local)).fold()).
cap('x').
store('a').by(unfold().limit(local, 1).fold()).unfold().
sack(assign).by(constant(1d)).
sack(div).by(union(constant(1d),tail(local, 1)).sum()).
sack(mult).by(limit(local, 1)).
sack().sum()).
cap('a')
==>[alice,[alice,bobby,cindy,david,eliza,alice],[9,8,7,6,10],18.833333333333332]
好长,好复杂!头大!
看我如何抽丝剥茧,一步步验证结果。
2.3. 调试过程
2.3.1 拆分查询
按执行步骤,拆分成小的查询,如下图:
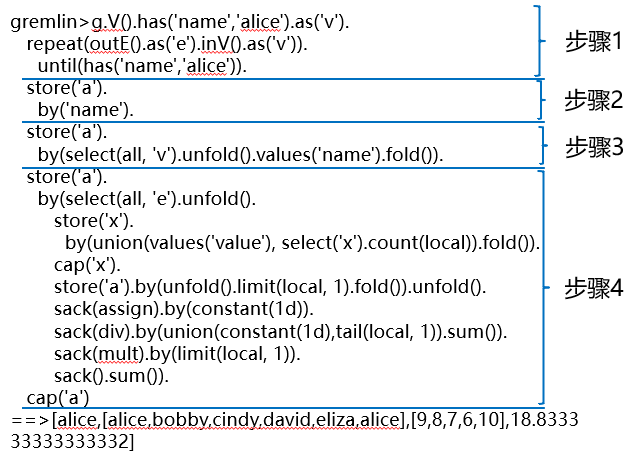
- 执行第一部分步骤
gremlin> g.V().has('name','alice').as('v').
......1> repeat(outE().as('e').inV().as('v')).
......2> until(has('name','alice'))
==>v[0]
2.3.2 澄清结果
这里通过valueMap()输出节点信息。
gremlin> g.V().has('name','alice').as('v').
......1> repeat(outE().as('e').inV().as('v')).
......2> until(has('name','alice')).valueMap()
==>[name:[alice]]
2.3.3 验证假设
根据执行语句的语义推导查询过程,如下:
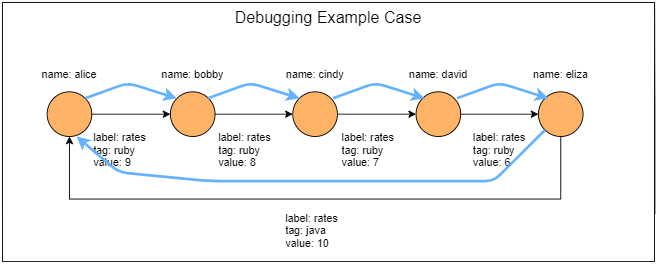
使用path(), 验证推导过程
g.V().has('name','alice').as('v').
......1> repeat(outE().as('e').inV().as('v')).
......2> until(has('name','alice')).path().next()
==>v[0]
==>e[10][0-rates->2]
==>v[2]
==>e[11][2-rates->4]
==>v[4]
==>e[12][4-rates->6]
==>v[6]
==>e[13][6-rates->8]
==>v[8]
==>e[14][8-rates->0]
==>v[0]
- 输出结果与推导结果一致,扩大查询语句, 回到步骤1;
- 如不一致或不理解结果, 缩小步骤范围, 可以采用此步骤的上一层查询步骤,回到步骤1;
- 如此循环直到完全理解整个查询。
gremlin> g.V().has('name','alice').as('v').
......1> repeat(outE().as('e').inV().as('v')).
......2> until(has('name','alice')).
......3> store('a').by('name')
==>v[0]
大家可以自己去细细的剥下笋,此处略去3000字。
3. 总结
- 在分析的过程,采用划分查询语句的方法,分步理解,采用漏斗式的方法,逐步扩大对语句的理解;
- 对每步的查询结果,可以采用利用valueMap(), path(), select(), as(), cap() 等函数输出和验证结果;
- 对于不清楚结果的步骤或与期望值不一致,缩小查询步骤,可以采用输出步骤的前一步骤作为输出点,进行输出和验证;
- 对于上一层数据的结果明确的情况下,可以采用inject()方式注入上层输出,继续后续的输出和验证;
- 要注意步骤最后的函数,对整个输出结果的影响。
4. 参考
- Introduction to Gremlin
- Gremlin’s Anatomy
- TinkerPop Documentation
- Stephen Mallette gremlins-anatomy
- Practical Gremlin - Why Graph?
本文分享自华为云社区《复杂Gremlin查询的调试方法》,原文作者:Uncle_Tom。
一文抽丝剥茧带你掌握复杂Gremlin查询的调试方法的更多相关文章
- Android绘图机制(四)——使用HelloCharts开源框架搭建一系列炫酷图表,柱形图,折线图,饼状图和动画特效,抽丝剥茧带你认识图表之美
Android绘图机制(四)--使用HelloCharts开源框架搭建一系列炫酷图表,柱形图,折线图,饼状图和动画特效,抽丝剥茧带你认识图表之美 这里为什么不继续把自定义View写下去呢,因为最近项目 ...
- win7自带wifi win7无线网络共享设置图文方法
win7自带wifi win7无线网络共享设置图文方法 点评:开启windows 7的隐藏功能:虚拟WiFi和SoftAP(即虚拟无线AP),就可以让电脑变成无线路由器,实现共享上网,节省网费和路由器 ...
- (转)MySQL数据表中带LIKE的字符匹配查询
MySQL数据表中带LIKE的字符匹配查询 2014年07月15日09:56 百科369 MySQL数据表中带LIKE的字符匹配查询 LIKE关键字可以匹配字符串是否相等. 如果字段的值与指定的 ...
- mysql进阶(五)数据表中带OR的多条件查询
MySQL数据表中带OR的多条件查询 OR关键字可以联合多个条件进行查询.使用OR关键字时: 条件 1) 只要符合这几个查询条件的其中一个条件,这样的记录就会被查询出来. 2) 如果不符合这些查询条件 ...
- mysql 数据操作 多表查询 子查询 带IN关键字的子查询
1 带IN关键字的子查询 #查询平均年龄在25岁以上的部门名关键点部门名 以查询员工表的dep_id的结果 当作另外一条sql语句查询条件使用 in (sql语句) mysql ; +-------- ...
- mysql 数据操作 多表查询 子查询 带比较运算符的子查询
带比较运算符的子查询 #比较运算符:=.!=.>.>=.<.<=.<> #查询大于所有人平均年龄的员工名与年龄 思路 先拿到所有人的平均年龄然后 再用另外一条sql ...
- mysql 数据操作 多表查询 子查询 带EXISTS关键字的子查询
带EXISTS关键字的子查询 EXISTS关字键字表示存在. EXISTS 判断某个sql语句的有没有查到结果 有就返回真 true 否则返回假 False 如果条件成立 返回另外一条sql语句的返 ...
- VS2013中带命令行参数的调试方法---C++
今天先记录一下(也是传说中大神喜欢装逼的comment line)c++中向主函数int main(int argc,char** argv )传递4中方法,欢迎添加新方法, 然后可以参考别人写的很好 ...
- MFC单文档带窗体创建
我用的vs05.先随便起个名字qwerty. 确定以后在左边最下面有一个生成的类,点击生成的类,把基类改成CFormView 最后点击完成就创建好了. 单文档的窗口不是后来创建后插入的,是在创建后就自 ...
随机推荐
- Hexo一键部署到阿里云OSS并设置浏览器缓存
自建博客地址:https://bytelife.net,欢迎访问! 本文为博客自动同步文章,为了更好的阅读体验,建议您移步至我的博客 本文作者: Jeffrey 本文链接: https://bytel ...
- FPGA的开发板
板卡架构 板载FPGA(K7-325T)处理24端口10/100/1000M以太网数据: FPGA外挂4Gbit的DDR3颗粒,最大支持800MHz: 板载CPU进行系统配置.管理,并与客户端软件通信 ...
- redhat安装python3.7
下载并解压: 1 wget https://www.python.org/ftp/python/3.7.2/Python-3.7.2.tgz 2 tar -xzvf Python-3.7.2.tgz ...
- Less常用变量与方法记录
需求:仅记录Lsee常用变量与方法定义,便于使用.-- @color: #000; @title-color: #000; @bg-color: #fff; @small-font: 12px; @l ...
- Java传参:值传递 or 引用传递 ?
刚开始学Java的时候一度以为:基本数据类型是值传递,引用类型是引用传递.新人很容易在这两个概念上面被搞糊涂,后来看了Hollis的文章才明白了Java中只有值传递. 接下来我能用简单明了的方式来说明 ...
- EF Core 源码分析
最近在接触DDD+micro service来开发项目,因为EF Core太适合DDD模式需要的ORM设计,所以这篇博客是从代码角度去理解EF core的内部实现,希望大家能从其中学到一些心得体会去更 ...
- 2019 GDUT Rating Contest III : Problem D. Lemonade Line
题面: D. Lemonade Line Input file: standard input Output file: standard output Time limit: 1 second Memo ...
- 这个Bug的排查之路,真的太有趣了。
这是why哥的第 92 篇原创文章 在<深入理解Java虚拟机>一书中有这样一段代码: public class VolatileTest { public static volat ...
- Qt 自定义 进度条 纯代码
一 结果图示 二 代码 头文件 #ifndef CPROGRESS_H #define CPROGRESS_H #include <QWidget> #include <QPaint ...
- Hznu_0j 1533 计算球体积(水)
题意:根据输入的半径值,计算球的体积: Input 输入数据有多组,每组占一行,每行包括一个实数,表示球的半径. Output 输出对应的球的体积,对于每组输入数据,输出一行,计算结果保留三位小数. ...