1.Flink实时项目前期准备
1.日志生成项目
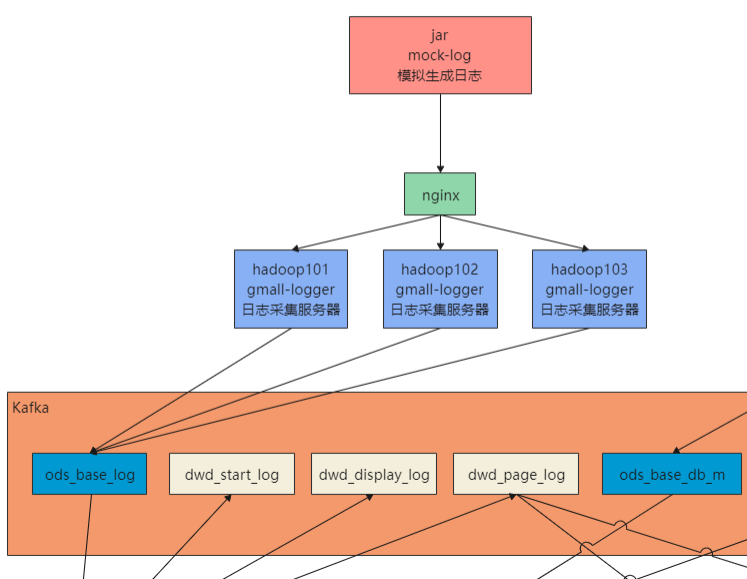
日志生成机器:hadoop101
jar包:mock-log-0.0.1-SNAPSHOT.jar
gmall_mock
|----mock_common
|----mock_db
|----mock_log
项目地址:https://github.com/zhangbaohpu/gmall-mock
将模块mock_log打包成jar,并在同级添加application.yml
cd /opt/software/applog/
vim application.yml
点击查看代码
# 外部配置打开
# logging.config=./logback.xml
#业务日期
mock.date: "2020-12-18"
#模拟数据发送模式
mock.type: "http"
#http模式下,发送的地址
mock.url: "http://hadoop101:8081/applog"
#mock:
# kafka-server: "hdp1:9092,hdp2:9092,hdp3:9092"
# kafka-topic: "ODS_BASE_LOG"
#启动次数
mock.startup.count: 1000
#设备最大值
mock.max.mid: 20
#会员最大值
mock.max.uid: 50
#商品最大值
mock.max.sku-id: 10
#页面平均访问时间
mock.page.during-time-ms: 20000
#错误概率 百分比
mock.error.rate: 3
#每条日志发送延迟 ms
mock.log.sleep: 100
#商品详情来源 用户查询,商品推广,智能推荐, 促销活动
mock.detail.source-type-rate: "40:25:15:20"
#领取购物券概率
mock.if_get_coupon_rate: 75
#购物券最大id
mock.max.coupon-id: 3
#搜索关键词
mock.search.keyword: "图书,小米,iphone11,电视,口红,ps5,苹果手机,小米盒子"
然后启动项目
java -jar mock-log-0.0.1-SNAPSHOT.jar
默认端口8080,调用以下方法,会向接口http://hadoop101:8081/applog 发送日志数据
点击查看代码
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.ConfigurableApplicationContext;
@SpringBootApplication
public class GmallMockLogApplication {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(GmallMockLogApplication.class, args);
MockTask mockTask = context.getBean(MockTask.class);
mockTask.mainTask();
}
}
2.日志采集项目
日志处理机器:hadoop101,hadoop102,hadoop103
项目地址:https://github.com/zhangbaohpu/gmall-flink-parent/tree/master/gmall-logger
jar包:gmall-logger-0.0.1-SNAPSHOT.jar
项目中配置文件:application.yml
点击查看代码
server:
port: 8081
#kafka
spring:
kafka:
bootstrap-servers: 192.168.88.71:9092,192.168.88.72:9092,192.168.88.73:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
LoggerController.java
接收日志,并把日志发送给kafka
点击查看代码
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @author zhangbao
* @date 2021/5/16 11:33
**/
@RestController
@Slf4j
public class LoggerController {
@Autowired
KafkaTemplate kafkaTemplate;
@RequestMapping("/applog")
public String logger(String param){
log.info(param);
kafkaTemplate.send("ods_base_log",param);
return param;
}
}
3.nginx配置
安装机器:hadoop101
修改nginx.conf配置,hadoop101作为负载均衡机器,hadoop101,hadoop102,hadoop103作为日志处理机器,nginx默认端口为80,主要配置如下:
点击查看代码
#在 server 内部配置
location /
{
proxy_pass http://www.logserver.com;
}
#切记:在 server 外部配置反向代理
upstream www.logserver.com{
server hadoop101:8081 weight=1;
server hadoop102:8081 weight=2;
server hadoop103:8081 weight=3;
}
4.将日志采集项目jar分发
将日志采集jar包分发到其他机器,供nginx负载均衡转发调用
xsync gmall-logger-0.0.1-SNAPSHOT.jar
5.修改模拟日志生成的配置
我们将生成的日子发送给nginx,然后在分发到其他采集日志的机器,生成日志的机器在hadoop101
cd /opt/software/applog/
vim application.yml
点击查看代码
#模拟数据发送模式
mock.type: "http"
#http模式下,发送的地址
mock.url: "http://hadoop101/applog"
6.集群群起脚本
将采集日志服务和nginx服务放在脚本中
在/home/zhangbao/bin创建脚本logger.sh
cd /home/zhangbao/bin,并授予执行权限
点击查看代码
#!/bin/bash
JAVA_HOME=/opt/module/jdk1.8.0_144/bin/java
APPNAME=gmall-logger-0.0.1-SNAPSHOT.jar
case $1 in
"start"){
for i in hadoop101 hadoop102 hadoop103
do
echo "================$i================="
ssh $i "$JAVA_HOME -Xms32m -Xmx64m -jar /opt/software/applog/$APPNAME >/dev/null 2>&1 &"
done
echo "===============NGINX================="
/opt/module/nginx/sbin/nginx
};;
"stop"){
echo "===============NGINX================="
/opt/module/nginx/sbin/nginx -s stop
for i in hadoop101 hadoop102 hadoop103
do
echo "================$i==============="
ssh $i "ps -ef|grep $APPNAME |grep -v grep|awk '{print \$2}'|xargs kill" >dev/null 2>&1
done
};;
esac
7.测试
| hadoop101 | hadoop102 | hadoop103 | |
|---|---|---|---|
| gmall_mock(生产日志) | √ | ||
| gmall-logger(采集日志) | √ | √ | √ |
| nginx | √ | ||
| kafka | √ | √ | √ |
注意以下操作需要在linux的zhangbao用户下操作,因为这些组件是在此用户下安装,不然起不来,脚本都在hadoop101这台机器:
启动zookeeper
su zhangbao
zk.sh start
启动kafka
kf.sh start
然后本项目的jar包可以在root用户下操作
手动执行
- 启动kafka消费者
kafka-console-consumer.sh --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181 --topic ods_base_log
- 启动nginx
/opt/module/nginx/sbin/nginx,地址:http://hadoop101/
启动日志采集服务
日志采集服务做了负责均衡,分别在hadoop101,hadoop102,hadoop103
java -jar /opt/software/applog/gmall-logger-0.0.1-SNAPSHOT.jar生产日志服务
生产日志服务在hadoop101,一台即可
java -jar /opt/software/applog/mock-log-0.0.1-SNAPSHOT.jar
使用脚本启停采集日志服务和nginx服务
./bin/logger.sh start
./bin/logger.sh stop
1.Flink实时项目前期准备的更多相关文章
- 5.Flink实时项目之业务数据准备
1. 流程介绍 在上一篇文章中,我们已经把客户端的页面日志,启动日志,曝光日志分别发送到kafka对应的主题中.在本文中,我们将把业务数据也发送到对应的kafka主题中. 通过maxwell采集业务数 ...
- 10.Flink实时项目之订单维度表关联
1. 维度查询 在上一篇中,我们已经把订单和订单明细表join完,本文将关联订单的其他维度数据,维度关联实际上就是在流中查询存储在 hbase 中的数据表.但是即使通过主键的方式查询,hbase 速度 ...
- 3.Flink实时项目之流程分析及环境搭建
1. 流程分析 前面已经将日志数据(ods_base_log)及业务数据(ods_base_db_m)发送到kafka,作为ods层,接下来要做的就是通过flink消费kafka 的ods数据,进行简 ...
- 4.Flink实时项目之数据拆分
1. 摘要 我们前面采集的日志数据已经保存到 Kafka 中,作为日志数据的 ODS 层,从 kafka 的ODS 层读取的日志数据分为 3 类, 页面日志.启动日志和曝光日志.这三类数据虽然都是用户 ...
- 6.Flink实时项目之业务数据分流
在上一篇文章中,我们已经获取到了业务数据的输出流,分别是dim层维度数据的输出流,及dwd层事实数据的输出流,接下来我们要做的就是把这些输出流分别再流向对应的数据介质中,dim层流向hbase中,dw ...
- 7.Flink实时项目之独立访客开发
1.架构说明 在上6节当中,我们已经完成了从ods层到dwd层的转换,包括日志数据和业务数据,下面我们开始做dwm层的任务. DWM 层主要服务 DWS,因为部分需求直接从 DWD 层到DWS 层中间 ...
- 9.Flink实时项目之订单宽表
1.需求分析 订单是统计分析的重要的对象,围绕订单有很多的维度统计需求,比如用户.地区.商品.品类.品牌等等.为了之后统计计算更加方便,减少大表之间的关联,所以在实时计算过程中将围绕订单的相关数据整合 ...
- 11.Flink实时项目之支付宽表
支付宽表 支付宽表的目的,最主要的原因是支付表没有到订单明细,支付金额没有细分到商品上, 没有办法统计商品级的支付状况. 所以本次宽表的核心就是要把支付表的信息与订单明细关联上. 解决方案有两个 一个 ...
- 8.Flink实时项目之CEP计算访客跳出
1.访客跳出明细介绍 首先要识别哪些是跳出行为,要把这些跳出的访客最后一个访问的页面识别出来.那么就要抓住几个特征: 该页面是用户近期访问的第一个页面,这个可以通过该页面是否有上一个页面(last_p ...
随机推荐
- Going Deeper with Convolutions (GoogLeNet)
目录 代码 Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]. computer vision and pattern ...
- Log4j2进阶使用(Pattern Layout详细设置)
1.进阶说明 通过配置Layout打印格式化的日志, Log4j2支持很多的Layouts: CSV GELF HTML JSON Pattern Serialized Syslog XML YAML ...
- python接口自动化,从excel取param的内容太多,使用eval转换报错'EOL while scanning string literal
背景: 做接口自动化时,有个接口的参数内容很多,可以从excel中读取出来,但是在eval()进行转化时,就报错"'EOL while scanning string literal&quo ...
- pymysql防止SQL注入的方法
import pymysql class Db(object): def __init__(self): self.conn = pymysql.connect(host="192.168. ...
- linux 下安装minconda3
一.关于bashrc目录,此文件是隐藏的,如果要打开此文件需要用: vim /root/.bashrc 二.linux下关于防火墙的命令 1.查看防火墙状态 firewall-cmd --state ...
- Ant 调用 Shell/CMD 命令
Ant中调用Makefile,使用shell中的make命令 <?xml version="1.0" encoding="utf-8" ?> < ...
- 解决ubuntu 18.04(桌面版)搜狗输入法不能正常使用的问题
ubuntu下搜狗输入法的配置文件在~/.config目录下,一般有三个目录SogouPY.SogouPY.users.sogou-qimpanel 执行命令 $ cd ~/.config $ rm ...
- Java实现单词统计
原文链接: https://www.toutiao.com/i6764296608705151496/ 单词统计的是统计一个文件中单词出现的次数,比如下面的数据源 其中,最终出现的次数结果应该是下面的 ...
- Word文档学习小练习链接
1. < Word2010初学> https://www.toutiao.com/i6487370439910752782/ 2. <Word2010格式化可爱的家乡> htt ...
- Backbone.js 0.9.2 源码分析收藏
Backbone 为复杂Javascript应用程序提供模型(models).集合(collections).视图(views)的结构.其中模型用于绑定键值数据和自定义事件:集合附有可枚举函数的丰富A ...