移动端 CPU 的深度学习模型推理性能优化——NCHW44 和 Record 原理方法详解
用户实践系列,将收录 MegEngine 用户在框架实践过程中的心得体会文章,希望能够帮助有同样使用场景的小伙伴,更好地了解和使用 MegEngine ~
作者:王雷 | 旷视科技 研发工程师
背景
随着人工智能技术的发展及应用领域的不断扩大,算力较弱的移动设备成为模型推理的重要运算载体,优化其推理性能因此成为重要的工程问题。一般认为,让模型运行于 GPU 上会比运行于 CPU 上具有较大的优势,取得可观的性能提升。这通常是真实情况,但是,在工程实践中我们也发现,对于某些模型维度较小的模型,在移动设备上,GPU 运行并没有带来性能的提升,而且还额外引入了兼容性的问题。所以,在某些应用场景下,我们需要以 CPU 为运行载体,尝试各种方法,以提升模型推理性能。
我们在优化某关键点模型推理性能的工程实践中,基于 MegEngine 推理引擎,发现有两个优化方法比较有效,NCHW44 和 Record。本文将对它们的原理和使用方法做比较详细的说明。
NCHW44 优化
原理
众所周知,增加计算的并行程度是提升计算速度的重要手段。在 CPU 上,这就需要使用 SIMD 指令 ——Single Instruction, Multiple Data,单指令多数据,即执行单条指令,操作完成多个数据的运算。例如执行加法运算,如果使用非 SIMD 指令即一般的加法指令,每次只能操作一个数,而在模型推理中,这个数经常是 8 位、16 位,最大不过是 32 位的浮点数,这对于现代 64 位的寄存器来说,确实有些浪费。如果在寄存器中存储多个数,一条指令完成运算,则能成倍的提升计算速度。在 x86 CPU 上,SIMD 的实现是 SSE、AVX 等指令集,而在 ARM CPU 上,则是 NEON 指令集。而且 CPU 还提供了 SIMD 指令的专用寄存器,在 x86 平台上,寄存器位数为 128 位、256 位,甚至是 512 位,在 ARM 平台上,寄存器位数是 128 位,这样就可以一次完成 4 个 float32 数据的运算。因此,如果能想办法在模型推理运算中尽可能多的使用 SIMD,就能提升推理的性能。
我们来看一下在模型推理中使用 SIMD 会遇到什么问题。通常,张量在内存中的存储方式为 NCHW(即每个通道的行列数据连续排布,再顺序存储各个通道),如在处理常见的卷积操作时,卷积核的尺寸可能多种多样,比如 3x3,那么每次需要取一行的 3 个连续的像素数据与卷积核相应位置数据相乘(再处理其他列和通道),而对应 SIMD 指令,其使用的寄存器通常为 128 位,使用 float32 的话也需要一次处理 4 个数据才能充分发挥其优势,而这四个数据必须在内存中处于相邻位置,所以这种计算方式大大限制了 SIMD 指令。
作为改进,在 NCHW44(也称 NC4HW4)布局下,同一位置(HW)的 4 个通道的数据被连续排列到了一起,在卷积操作时它们一起参与计算,每次 SIMD 指令执行可以将它们一起载入寄存器,这样就提升了计算效率。下图示意了 NCHW44 的数据存储排列方式。
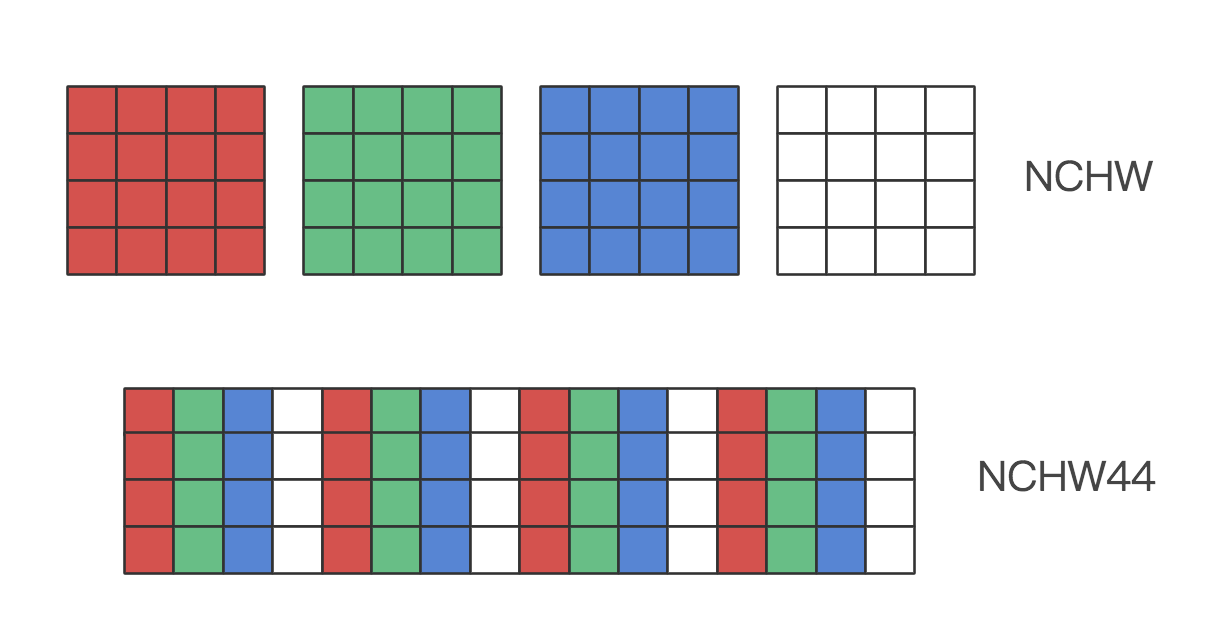
实践
MegEngine 支持两种方式使用 NCHW44 优化:
1. 离线 dump(序列化)成 NCHW44 模型,推理时 MegEngine 会自动判断出它的排列方式,执行相应的算子实现。下面两个用于 dump 的方法
megengine.jit.trace.dump
megengine.core.tensor.megbrain_graph.optimize_for_inference
支持关键字参数 enable_nchw44,将参数值设为 True,所输出的就是 NCHW44 的模型。
对应的,如果想通过 load_and_run 预先测试性能,可以在使用 sdk/load-and-run/dump_with_testcase_mge.py 脚本时添加参数 —enable-nchw44,生成的模型即是可被 load_and_run 加载执行的 nchw44 模型。
2. 在线开启转换,dump 模型时不做 nchw44 配置,运行时通过 option 开启转换:
serialization::GraphLoader::LoadConfig load_config;
load_config.comp_graph = ComputingGraph::make();
auto &&graph_opt = ret.load_config.comp_graph->options();
graph_opt.graph_opt.enable_nchw44();
对应的,如果想通过 load_and_run 预先测试性能,可以在执行 load_and_run 时,添加命令行参数 —enable-nchw44。
两种方式可以结合具体的使用情况来选择:如果我们开发的 sdk 或 app 可能加载多个模型,有些使用 NCHW44 而有些不使用,比较适合选择离线方式;如果因为某些原因,我们无法重新 dump 模型(比如原始的模型文件丢失),则只能选择在线方式。
效果
在我们的工程实践中,某模型在当前主流 android 手机上的推理速度,大概有 20%-30% 左右的提升。
record 优化
原理
当 MegEngine 执行推理时,底层执行的是静态图,它的执行序列是确定的。对于图中的每个算子,执行都要分为两个步骤:准备 kernel 和实际执行。在准备 kernel 阶段,MegEngine 会依据 filter size、stride、shape 等信息决定要执行的算法,也就是选择要执行的函数,即 kernel(对于卷积运算,可能会有多种不同的实现)。在执行阶段,再实际调用这些函数。
如果选择所需的依据不变(实际情况中主要是 shape 不要变),那么这个准备 kernel 的过程就只需被执行一次,并把选择的各个函数对象记录到一个列表中,以后再执行的时候,直接顺序地从列表中取出函数对象,执行即可。这样就节省了后续各次执行时准备 kernel 的时间。这也就是 record 这个名字的含义所在。
目前 MegEngine 存在两种级别的 record。record1 主要是为了加速执行,原理如上所述;record2 主要是为了节省内存,如果 shape 不变,MegEngine 可以析构图上存储的一些信息(这些信息可以在 shape 改变时用来做 shape 的推导)。对于我们希望提升计算性能的场景,一般 record1 比较合适。
注意 record 的一个最重要的限制条件是 shape 不能改变。对于某些检测模型,可能需要依据输入图的尺寸,对模型进行 resize,这种情况就无法使用 record。对于输入长宽和通道数不变的模型,仍需注意,batch 参数(即 NCHW 中的 N)也不能变,这是可能被忽略的。另外,模型加载后,在第一次运行之前,我们还是可以改变 shape 的,只要第一次运行之后不再改变 shape,就不影响 record 的使用。
除了 shape 不变这个条件之外,还有一些限制条件:
所有的算子不能依赖动态内存分配,因为记录的函数对象还包含输入输出的指针,动态内存情况下会发生变化;
Host 端的输入输出指针不能变;
同步只能发生在网络执行的末尾,即不能在网络执行过程中,在某中间节点执行同步;
整个图中不能存在多个 compnode。
这些条件对于一般的使用,基本可以满足。
实践
在 option 中开启
serialization::GraphLoader::LoadConfig load_config;
load_config.comp_graph = ComputingGraph::make();
auto &&graph_opt = load_config.comp_graph->options();
graph_opt.comp_node_seq_record_level = 1; // 2
对应的,如果想通过 load_and_run 预先测试性能,可以在执行 load_and_run 时,添加命令行参数 --record-comp-seq 或 --record-comp-seq2。
效果
在我们的工程实践中,某模型在当前主流 android 手机上的推理速度,大概有 10% 左右的提升。
总结
本文从原理和使用方面介绍了 MegEngine 的 NCHW44 和 record 两个优化方法,它们只是我们在优化某关键点模型推理性能时尝试发现比较有效的两个方法。优化方法的有效性取决于模型的特点,因此对于具体的模型,可以尝试 MegEngine 的其他优化选项,选择比较合适的方法。当然,优化是多方面的,除了模型推理本身之外,优化预处理和后处理,减少数据复制,对于 Android 设备合理的设置 CPU 亲缘性等等,也是可以尝试和考虑的方案。
移动端 CPU 的深度学习模型推理性能优化——NCHW44 和 Record 原理方法详解的更多相关文章
- CUDA上的量化深度学习模型的自动化优化
CUDA上的量化深度学习模型的自动化优化 深度学习已成功应用于各种任务.在诸如自动驾驶汽车推理之类的实时场景中,模型的推理速度至关重要.网络量化是加速深度学习模型的有效方法.在量化模型中,数据和模型参 ...
- 『高性能模型』Roofline Model与深度学习模型的性能分析
转载自知乎:Roofline Model与深度学习模型的性能分析 在真实世界中,任何模型(例如 VGG / MobileNet 等)都必须依赖于具体的计算平台(例如CPU / GPU / ASIC 等 ...
- Roofline Model与深度学习模型的性能分析
原文链接: https://zhuanlan.zhihu.com/p/34204282 最近在不同的计算平台上验证几种经典深度学习模型的训练和预测性能时,经常遇到模型的实际测试性能表现和自己计算出的复 ...
- 人工智能之深度学习-初始环境搭建(安装Anaconda3和TensorFlow2步骤详解)
前言: 本篇文章主要讲解的是在学习人工智能之深度学习时所学到的知识和需要的环境配置(安装Anaconda3和TensorFlow2步骤详解),以及个人的心得体会,汇集成本篇文章,作为自己深度学习的总结 ...
- 深度学习基础系列(十一)| Keras中图像增强技术详解
在深度学习中,数据短缺是我们经常面临的一个问题,虽然现在有不少公开数据集,但跟大公司掌握的海量数据集相比,数量上仍然偏少,而某些特定领域的数据采集更是非常困难.根据之前的学习可知,数据量少带来的最直接 ...
- Linux学习之让进程在后台可靠运行的方法详解
我们经常会碰到这样的问题,用 telnet/ ssh 登录了远程的 Linux 服务器http://www.maiziedu.com/course/592/,运行了一些耗时较长的任务, 结果却由于网络 ...
- 使用函数计算三步实现深度学习 AI 推理在线服务
目前深度学习应用广发, 其中 AI 推理的在线服务是其中一个重要的可落地的应用场景.本文将为大家介绍使用函数计算部署深度学习 AI 推理的最佳实践, 其中包括使用 FUN 工具一键部署安装第三方依赖 ...
- Apple的Core ML3简介——为iPhone构建深度学习模型(附代码)
概述 Apple的Core ML 3是一个为开发人员和程序员设计的工具,帮助程序员进入人工智能生态 你可以使用Core ML 3为iPhone构建机器学习和深度学习模型 在本文中,我们将为iPhone ...
- 【翻译】借助 NeoCPU 在 CPU 上进行 CNN 模型推理优化
本文翻译自 Yizhi Liu, Yao Wang, Ruofei Yu.. 的 "Optimizing CNN Model Inference on CPUs" 原文链接: h ...
随机推荐
- c++11 线程间同步---利用std::condition_variable实现
1.前言 很多时候,我们在写程序的时候,多多少少会遇到下面种需求 一个产品的大致部分流程,由工厂生产,然后放入仓库,最后由销售员提单卖出去这样. 在实际中,仓库的容量的有限的,也就是说,工厂不能一直生 ...
- ES2021 新特性!
大家好,我是前端队长Daotin,想要获取更多前端精彩内容,关注我(全网同名),解锁前端成长新姿势. 以下正文: 2021 年 6 月 22 日,第 121 届 Ecma 国际(Ecma Intern ...
- leetcode 861 翻转矩阵后的得分
1. 题目描述 2.思路分析: 1. 首先这里的翻转分为了行翻转和列翻转,我们这里只需要求如何翻转后得到最大值,有点贪心的思想,因为最大值一定是固定的 至于是什么路径到达的最大值不是我们所关心的,我们 ...
- [转载]实现DDOS攻击自动封禁IP
1 #!/bin/bash 2 ############################################################# 3 # File Name: ddos_ch ...
- 从零搭建一个IdentityServer——资源与访问控制
IdentityServer作为授权服务器它的最终目的是用于对资源进行管控,这里所说的资源有两种,其一是API资源,实际上也就是OIDC协议中客户端(RP)所需要访问的一系列受保护的资源(API),授 ...
- C语言:赋值语句
赋值语句 1.赋值号:= 2.赋值号具有方向性,只能将右边的常数 变量的值 表达式的值赋值给左边的变量 3.赋值号左边只能是变量,不能是表达式.常数.符号常量.常量 如下列是非法的语句:a+b=3; ...
- c++中的静态成员
引言 有时候需要类的一些成员与类本身相关联,而不是与类的每个对象相关联.比如类的所有对象都要共享的变量,这个时候我们就要用到类的静态成员. 声明类的静态成员 声明静态成员的方法是使用static关键字 ...
- [刘阳Java]_什么是EasyUI_第1讲
jQuery EasyUI在Java后台开发中用得还是比较多.当然客观来讲虽然前端技术的发展,很多后台界面设计都植入了前端技术的框架.但是这篇文章我个人觉得也不会妨碍我们对jQuery EasyUI的 ...
- python -- 模块与类库
一.模块 模块(Module)是由一组类.函数和变量组成的,模块文件的扩展名是.py或.pyc 在使用模块之前,需要先使用import语句导入这个模块. 语法格式如下: import 模块名 from ...
- JavaScript实现拖放效果
JavaScript实现拖放效果 笔者实现该效果也是套用别人的轮子的.传送门 然后厚颜无耻的贴别人的readme~,笔者为了方便查阅就直接贴了,有不想移步的可以看这篇.不过还是最好请到原作者的GitH ...