你的ES数据备份了吗?
前言:
无论使用哪种存储软件,定期的备份数据都是重中之重,在使用ElasticSearch的时候,随着数据日益积累,存放es数据的磁盘空间也捉襟见肘,
此时对于业务功能使用不到的索引数据,又不能直接删除,将它迁移到线下数据盘存储就变得十分必要。
下面就记录一下在docker中部署的单节点以月份索引的es数据的备份和迁移过程。
一:docker安装ES
1:docker的安装:Docker-常用基建的安装与部署
2:下载es镜像:
docker pull elasticsearch:5.6.8
3:elasticsearch.yml 配置:
http.host: 0.0.0.0 # Uncomment the following lines for a production cluster deployment
#transport.host: 0.0.0.0
#discovery.zen.minimum_master_nodes: 1
cluster.name: "elasticsearch"
http.cors.enabled: true
http.cors.allow-origin: "*"
path.repo: ["/usr/share/elasticsearch/backup"]
4:创建es容器
docker run -d --name es -p 9200:9200 -p 9300:9300
--net docker_default --ip 172.18.0.40
--memory-swappiness=0
-v /root/data/docker/es/data:/usr/share/elasticsearch/data
-v /root/data/docker/es/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
-v /root/data/docker/es/logs:/user/share/elasticsearch/logs
-v /root/data/docker/es/backup:/usr/share/elasticsearch/backup
-e "discovery.type=single-node"
--restart=always elasticsearch:5.6.8
上面三步简单的创建完一个可用的es容器,接下来就用它来测试es的快照功能。
二:快照索引
snapshot API 是ES备份、迁移数据的重要手段。它支持增量备份,支持多种类型的仓库存储。
ES的备份过程是"智能"的。你对一个索引的第一个快照会是这个索引的完整拷贝,但是所有后续的快照会保留的是已存快照和新数据之间的差异。
随着你不时的对相同索引进行快照,备份也在增量的添加和删除。这意味着后续备份会相当快速,因为它们只传输很小的数据量。
备份路径通过配置: path.repo: ["/usr/share/elasticsearch/backup"] ,注意该路径是es容器内部的,
所以我们在创建es容器时,可以通过 -v /宿主机目录:/容器目录,将宿主机目录挂载到容器内部。
1:创建一个备份仓库:my_backup
curl -XPUT 127.0.0.1:9200/_snapshot/my_backup -d '{
"type": "fs",
"settings": {
"location": "/usr/share/elasticsearch/backup/my_backup"
}
}'
共享文件系统支持的配置如下图:
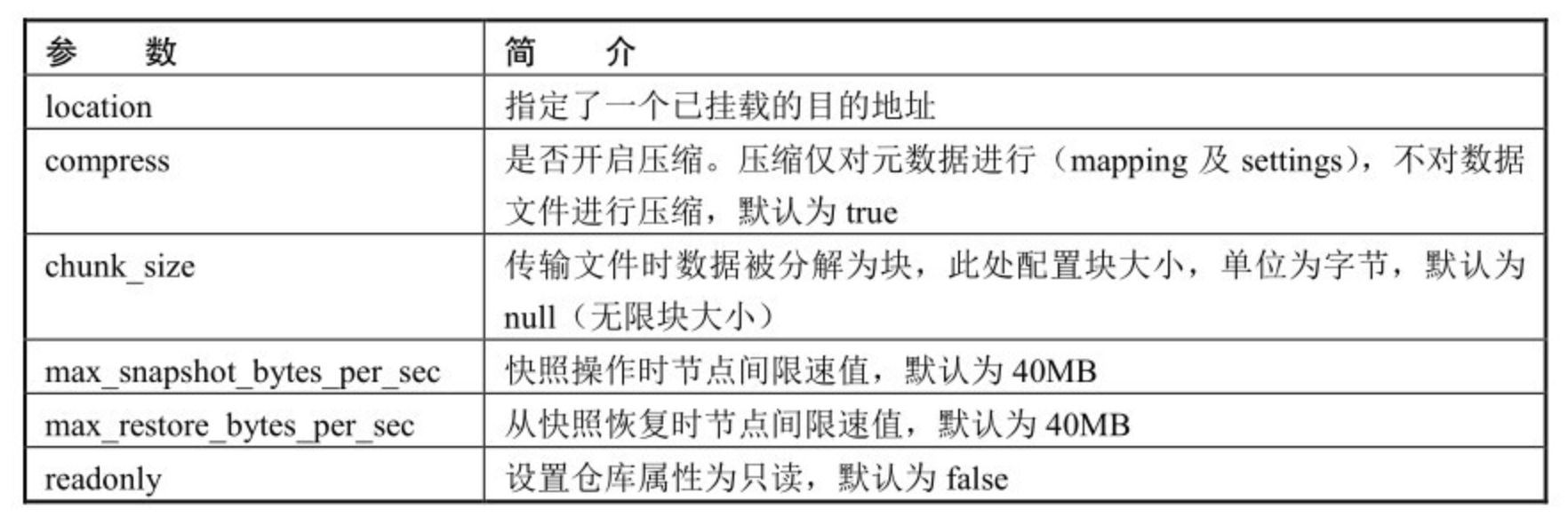
如果报错:[my_backup] failed to create repository, 执行:chmod 777 /root/data/docker/es/backup
2:开始备份指定索引(close状态的索引不可以执行快照),以 nova-202102 为例:
curl -XPUT 127.0.0.1:9200/_snapshot/my_backup/nova-202102?wait_for_completion=true -d '{
"indices": "nova-202102"
}'
如果索引文件较大,可以去掉wait_for_completion=true,该命令会后台执行备份。
如果备份是后台执行的,下面命令可以查询备份的状态
curl -XGET 127.0.0.1:9200/_snapshot/my_backup/nova-202102/_status
状态值有:
INITIALIZING 分片在检查集群状态看看自己是否可以被快照。这个一般是非常快的。
STARTED 数据正在被传输到仓库。
FINALIZING 数据传输完成;分片现在在发送快照元数据。
DONE 快照完成!
FAILED 快照处理的时候碰到了错误,这个分片/索引/快照不可能完成了。检查你的日志获取更多信息。
# 取消正在备份的索引
curl -XDELETE 127.0.0.1:9200/_snapshot/my_backup/nova-202102
curl -XGET 127.0.0.1:9200/_snapshot/my_backup/nova-202102
三:快照恢复
要恢复一个快照,该索引必须是关闭状态或者已经被删除。
curl -XPOST 127.0.0.1:9200/_snapshot/my_backup/nova-202102/_restore
监控快照恢复状态
curl -XGET 127.0.0.1:9200/restored_nova-202102/_recovery
恢复过程是基于ES标准恢复机制的,因此标准的恢复监控服务可以用来监视恢复的状态。
当执行集群恢复操作时通常会进入Red状态,这是因为恢复操作是从索引的主分片开始的,在此期间主分片状态变为不可用,因此集群状态表现为Red。
一旦ES主分片恢复完成,整个集群的状态将被转换成Yellow,并且开始创建所需数量的副分片。一旦创建了所有必需的副分片,集群转换到Green状态。
四:参考文献
2:Elasticsearch源码解析与优化实战
你的ES数据备份了吗?的更多相关文章
- ES数据备份到HDFS
1.准备好HDFS(这里我是本机测试) 2.es 安装repository-hdfs插件 (如es为多节点需在每个节点都安装插件) elasticsearch-plugin install repos ...
- elasticsearch 数据备份
ES数据备份找了一些方法,发现elasticdump 这个工具不错 elasticdump --input=http://192.168.0.92:9200/hs2840 --output ./hs2 ...
- ELK数据迁移,ES快照备份迁移
通过curl命令或者kibana快照备份,恢复的方式进行数据迁移 环境介绍 之前创建的ELK 因为VPC环境的问题,需要对ELK从新部署,但是还需要保留现有的数据,于是便有了这篇文档. 10.0.20 ...
- elasticsearch数据备份与sshfs建立共享文件
1.背景: 最近公司为了适应业务的发展,利用elasticsearch搜索引擎搭建了两个节点.为了防止数据丢失的特殊情况,需要定时做数据备份,而由于elasticsearch为两个节点分别在不同的服务 ...
- elasticsearch数据备份还原
elasticsearch数据备份还原 1.在浏览器中运行http://XXX.XXX.XXX.XXX:9200/_flush,确保索引数据能保存到硬盘中. 2.原数据的备份.主要是elasticse ...
- es snapshot备份到hdfs及从hdfs恢复snapshot
snapshot可以将es整个集群,具体索引数据备份到磁盘,hdfs等.需要时,可以从磁盘,hdfs恢复数据到es. 具体参考: https://elasticsearch.cn/article/61 ...
- ElasticSearch 集群 & 数据备份 & 优化
ElasticSearch 集群相关概念 ES 集群颜色状态 ①. - 红色:数据都不完整 ②. - 黄色:数据完整,但是副本有问题 ③. - 绿色:数据和副本全都没有问题 ES 集群节点类型 ①. ...
- 实际使用Elasticdump工具对Elasticsearch集群进行数据备份和数据还原
文/朱季谦 目录 一.Elasticdump工具介绍 二.Elasticdump工具安装 三.Elasticdump工具使用 最近在开发当中做了一些涉及到Elasticsearch映射结构及数据导出导 ...
- 数据备份的OSS接口
最近在做一个新的项目,从RDS备份到OSS,进行数据备份以及后续的还原.这边对阿里云的OSS数据上传接口进行说明,先做下笔记先简单介绍下OSS: ①Object 在OSS中,用户操作的基本数据单元是O ...
随机推荐
- 23、nginx动态添加nginx_upstream_check_module健康检查模块
nginx_upstream_check_module模块地址:https://github.com/yaoweibin/nginx_upstream_check_module 23.1.说明: 1. ...
- C. Learning Languages 求联通块的个数
C. Learning Languages 1 #include <iostream> 2 #include <cstdio> 3 #include <cstring&g ...
- consul 多节点/单节点集群搭建
三节点配置 下载安装包 mkdir /data/consul mkdir /data/consul/data curl -SLO https://github.com/consul/1.9.5/con ...
- MyBatis:MyBatis-Plus条件构造器EntityWrapper
EntityWrapper 简介 1. MybatisPlus 通过 EntityWrapper(简称 EW,MybatisPlus 封装的一个查询条件构造器)或者 Condition(与 EW 类似 ...
- leetcode 861 翻转矩阵后的得分
1. 题目描述 2.思路分析: 1. 首先这里的翻转分为了行翻转和列翻转,我们这里只需要求如何翻转后得到最大值,有点贪心的思想,因为最大值一定是固定的 至于是什么路径到达的最大值不是我们所关心的,我们 ...
- leetcode TOP100 字母异位词分组
字母异位词分组 给定一个字符串数组,将字母异位词组合在一起.字母异位词指字母相同,但排列不同的字符串. 思路: 一个map,将每个字符串字符进行记数,字符作为map的key,次数初始为零,以此来标识字 ...
- mysql 索引介绍与运用
索引 (1)什么是索引? 是一种提升查询速度的 特殊的存储结构. 它包含了对数据表里的记录的指针,类似于字典的目录. 当我们添加索引时会单独创建一张表来去存储和管理索引,索引比原数据大,会占用更多的资 ...
- Python----MongoDB数据库
什么是MongoDB ? MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统. 在高负载的情况下,添加更多的节点,可以保证服务器性能. MongoDB 旨在为WEB应用提供 ...
- ctf杂项之easy_nbt
下载附件查看 除了几个文件之外,没有思路 搜索nbt可知,可以使用nbtexplorer工具 果断下载,然后打开题目下载的目录 crrl+f搜索flag 猜测kflag{Do_u_kN0w_nbt?} ...
- 简单DOS命令
1.nslookup命令 nslookup命令是用来解析域名的,举个例子:我们只知道百度的域名是www.baidu.com 想要知道它的ip的话就要使用nslookup命令了nslookup www. ...