Spark(十一)【SparkSQL的基本使用】
一. SparkSQL简介
Spark SQL是Spark用于结构化数据(structured data)处理的Spark模块。
Dremel ------> Drill(Apache)------>Impala(Cloudrea) Presto(Hotonworks)
Hive -------> Shark(对Hive的模仿,区别在于使用Spark进行计算)
Shark------->SparkSQL(希望拜托对Hive的依赖,兼容Hive)
SparkSQL: 如果使用SparkSQL执行Hive语句! 这种行为称为 Spark on Hive
如果使用Hive,执行Hive语句,但是在配置Hive时,修改了Hive的执行引擎,将执行引擎修改为了Spark! 这种行为称为Hive on Spark!
特点
- 易整合。 在程序中既可以使用SQL,还可以使用API!
- 统一的数据访问。 不同数据源中的数据,都可以使用SQL或DataFrameAPI进行操作,还可以进行不同数据源的Join!
- 对Hive的无缝支持
- 支持标准的JDBC和ODBC
二. 数据模型
DataFrame:DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。
DataSet:是DataFrame的一个扩展,类似于数据库中的表。
区别
DataSet是强类型。DataSet=DataSet[Person].
DataFrame是弱类型。DataFrame=DataSet[Row],是DataSet的一个特例。
三. SparkSQL核心编程
Spark Core:要执行应用程序,要首先构建上下文环境对象SparkContext.
SparkSQL
老的版本中,提供两种SQL查询起始点:一个叫SQLContext,用于Spark自己提供的SQL查询;一个叫HiveContext,用于连接Hive的查询。
最新的版本SparkSQL的查询入口是SparkSession。是SQLContext和HiveContext的组合,SparkSession内部封装了SparkContext
1. IDEA开发SparkSQL
pom依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
2. SparkSession
创建
方式一
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
val session: SparkSession = SparkSession.builder
.master("local[*]")
.appName("MyApp")
.getOrCreate()
方式二
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val session: SparkSession = SparkSession.builder().config(conf).getOrCreate()
关闭
session.stop()
获取SparkContext
session.sparkContext //获取SparkSession中的SparkContext
3. DataFrame
3.1 入门案例
/**
* DataFrame入门案例
*/
@Test
def createDF: Unit = {
//数据格式:{"username":"zhangsan","age":20}
//读取json格式文件创建DataFrame
val df: DataFrame = session.read.json("input/1.txt")
//创建临时视图:person
df.createOrReplaceTempView("person")
//查看person表
df.show()
//通过sql查询
session.sql(
"""
|select
|*
|from
|person
|""".stripMargin).show()
}
3.2 显示数据
df.show()
3.3 创建DF
①读取数据源创建
session.read
csv format jdbc json load option options orc parquet schema table text textFile
②通过RDD创建DataFrame
样例类
实际开发中,一般通过样例类将RDD转换为DataFrame
先导入隐式转换包,通过rdd.toDF()方法转换
/**
* Person样例类
*/
case class Person(name: String, age: Int)
/**
* 通过RDD创建DataFrame
*/
@Test
def creatDFByRDD {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val session: SparkSession = SparkSession.builder().config(conf).getOrCreate()
//根据样例类创建RDD
val rdd: RDD[(String, Int)] = session.sparkContext.makeRDD(List(("zhangsan", 12), ("lisi", 45), ("wangwu", 23)))
val person_RDD: RDD[Person] = rdd.map {
case (name, age) => Person(name, age)
}
//导入隐式包,session是上文创建的SparkSession对象
import session.implicits._
val df: DataFrame = person_RDD.toDF()
//查看DF
df.show()
session.stop()
}
③从hive表查询**
3.4 SQL查询语法
首先由DataFrame创建一个视图,然后用Sql语法操作
/*****************创建视图************************/
//临时视图
createOrReplaceTempView("视图名") //不会报错
createTempView("视图名") //视图名已存在,会报错
//永久视图
df.createGlobalTempView("person")
/******************Sql查询*************************/
//临时视图:person
//查询全局视图需要添加:global_temp.person
session.sql(
"""
|select
|*
|from
|person
|""".stripMargin).show()
注意:普通临时表是Session范围内的,如果想应用范围内有效,可以使用全局临时表。使用全局临时表时需要全路径访问,如:global_temp.people
4. DataSet
DataSet是具有强类型的数据集合,需要提供对应的类型信息。
4.1 创建DS
样例类RDD创建
/**
* Person样例类
*/
case class Person(name: String, age: Int)
/**
* 通过RDD创建DataFrame
*/
@Test
def creatDFByRDD {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val session: SparkSession = SparkSession.builder().config(conf).getOrCreate()
//根据样例类创建RDD
val rdd: RDD[(String, Int)] = session.sparkContext.makeRDD(List(("zhangsan", 12), ("lisi", 45), ("wangwu", 23)))
val person_RDD: RDD[Person] = rdd.map {
case (name, age) => Person(name, age)
}
//导入隐式包,session是上文创建的SparkSession对象
import session.implicits._
val df: Dataset[Person] = person_RDD.toDS()
//查看DF
df.show()
session.stop()
}
基本类型的序列创建DataSet
val list: Seq[Int] = List(1, 2, 3, 4)
import session.implicits._
val df1 = list.toDS()
注意:在实际使用的时候,很少用到把序列转换成DataSet,更多的是通过RDD来得到DataSet
5. RDD、DataFrame、DataSet
三者的关系
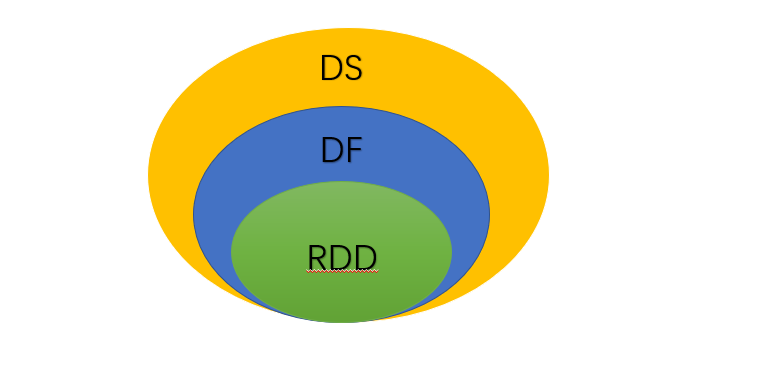
相互转换
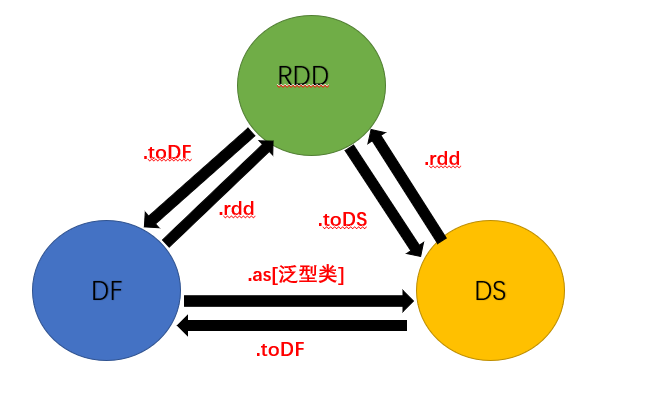
代码示例
object SparkSQL01_Demo {
def main(args: Array[String]): Unit = {
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL01_Demo")
//创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
//RDD=>DataFrame=>DataSet转换需要引入隐式转换规则,否则无法转换
//spark不是包名,是上下文环境对象名
import spark.implicits._
//读取json文件 创建DataFrame {"username": "lisi","age": 18}
val df: DataFrame = spark.read.json("input/test.json")
//df.show()
//SQL风格语法
df.createOrReplaceTempView("user")
//spark.sql("select avg(age) from user").show
//DSL风格语法
//df.select("username","age").show()
//*****RDD=>DataFrame=>DataSet*****
//RDD
val rdd1: RDD[(Int, String, Int)] = spark.sparkContext.makeRDD(List((1,"zhangsan",30),(2,"lisi",28),(3,"wangwu",20)))
//DataFrame
val df1: DataFrame = rdd1.toDF("id","name","age")
//df1.show()
//DateSet
val ds1: Dataset[User] = df1.as[User]
//ds1.show()
//*****DataSet=>DataFrame=>RDD*****
//DataFrame
val df2: DataFrame = ds1.toDF()
//RDD 返回的RDD类型为Row,里面提供的getXXX方法可以获取字段值,类似jdbc处理结果集,但是索引从0开始
val rdd2: RDD[Row] = df2.rdd
//rdd2.foreach(a=>println(a.getString(1)))
//*****RDD=>DataSet*****
rdd1.map{
case (id,name,age)=>User(id,name,age)
}.toDS()
//*****DataSet=>=>RDD*****
ds1.rdd
//释放资源
spark.stop()
}
}
case class User(id:Int,name:String,age:Int)
DataFrame
1、与RDD和Dataset不同,DataFrame每一行的类型固定为Row,只有通过解析才能获取各个字段的值,如
testDF.foreach{
line =>
val col1=line.getAs[String]("col1")
val col2=line.getAs[String]("col2")
}
每一列的值没法直接访问
2、DataFrame与Dataset一般与spark ml同时使用
3、DataFrame与Dataset均支持sparksql的操作,比如select,groupby之类,还能注册临时表/视窗,进行sql语句操作,如
dataDF.createOrReplaceTempView("tmp")
spark.sql("select ROW,DATE from tmp where DATE is not null order by DATE").show(100,false)
4、DataFrame与Dataset支持一些特别方便的保存方式,比如保存成csv,可以带上表头,这样每一列的字段名一目了然
//保存
val saveoptions = Map("header" -> "true", "delimiter" -> "\t", "path" -> "hdfs://172.xx.xx.xx:9000/test")
datawDF.write.format("com.databricks.spark.csv").mode(SaveMode.Overwrite).options(saveoptions).save()
//读取
val options = Map("header" -> "true", "delimiter" -> "\t", "path" -> "hdfs://172.xx.xx.xx:9000/test")
val datarDF= spark.read.options(options).format("com.databricks.spark.csv").load()
利用这样的保存方式,可以方便的获得字段名和列的对应,而且分隔符(delimiter)可以自由指定
Dataset
这里主要对比Dataset和DataFrame,因为Dataset和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同
DataFrame也可以叫Dataset[Row],每一行的类型是Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面提到的getAS方法或者共性中的第七条提到的模式匹配拿出特定字段
而Dataset中,每一行是什么类型是不一定的,在自定义了case class之后可以很自由的获得每一行的信息
case class Coltest(col1:String,col2:Int)extends Serializable //定义字段名和类型
/**
rdd
("a", 1)
("b", 1)
("a", 1)
* */
val test: Dataset[Coltest]=rdd.map{line=>
Coltest(line._1,line._2)
}.toDS
test.map{
line=>
println(line.col1)
println(line.col2)
}
可以看出,Dataset在需要访问列中的某个字段时是非常方便的,然而,如果要写一些适配性很强的函数时,如果使用Dataset,行的类型又不确定,可能是各种case class,无法实现适配,这时候用DataFrame即Dataset[Row]就能比较好的解决问题
转化
RDD、DataFrame、Dataset三者有许多共性,有各自适用的场景常常需要在三者之间转换
DataFrame/Dataset转RDD
这个转换很简单
val rdd1=testDF.rdd
val rdd2=testDS.rdd
RDD转DataFrame
import spark.implicits._
val testDF = rdd.map {line=>
(line._1,line._2)
}.toDF("col1","col2")
一般用元组把一行的数据写在一起,然后在toDF中指定字段名
RDD转Dataset
import spark.implicits._
case class Coltest(col1:String,col2:Int)extends Serializable //定义字段名和类型
val testDS = rdd.map {line=>
Coltest(line._1,line._2)
}.toDS
可以注意到,定义每一行的类型(case class)时,已经给出了字段名和类型,后面只要往case class里面添加值即可
Dataset转DataFrame
这个也很简单,因为只是把case class封装成Row
import spark.implicits._
val testDF = testDS.toDF
DataFrame转Dataset
import spark.implicits._
case class Coltest(col1:String,col2:Int)extends Serializable //定义字段名和类型
val testDS = testDF.as[Coltest]
这种方法就是在给出每一列的类型后,使用as方法,转成Dataset,这在数据类型是DataFrame又需要针对各个字段处理时极为方便
特别注意
在使用一些特殊的操作时,一定要加上 import spark.implicits._ 不然toDF、toDS无法使用
总结:在对DataFrame和Dataset进行操作许多操作都需要这个包:import spark.implicits._(在创建好SparkSession对象后尽量直接导入)
Spark(十一)【SparkSQL的基本使用】的更多相关文章
- Hive On Spark和SparkSQL
SparkSQL和Hive On Spark都是在Spark上实现SQL的解决方案.Spark早先有Shark项目用来实现SQL层,不过后来推翻重做了,就变成了SparkSQL.这是Spark官方Da ...
- 基于Spark和SparkSQL的NetFlow流量的初步分析——scala语言
基于Spark和SparkSQL的NetFlow流量的初步分析--scala语言 标签: NetFlow Spark SparkSQL 本文主要是介绍如何使用Spark做一些简单的NetFlow数据的 ...
- Spark系列-SparkSQL实战
Spark系列-初体验(数据准备篇) Spark系列-核心概念 Spark系列-SparkSQL 之前系统的计算大部分都是基于Kettle + Hive的方式,但是因为最近数据暴涨,很多Job的执行时 ...
- hive on spark VS SparkSQL VS hive on tez
http://blog.csdn.net/wtq1993/article/details/52435563 http://blog.csdn.net/yeruby/article/details/51 ...
- Spark(四): Spark-sql 读hbase
SparkSQL是指整合了Hive的spark-sql cli, 本质上就是通过Hive访问HBase表,具体就是通过hive-hbase-handler, 具体配置参见:Hive(五):hive与h ...
- Spark记录-SparkSql官方文档中文翻译(部分转载)
1 概述(Overview) Spark SQL是Spark的一个组件,用于结构化数据的计算.Spark SQL提供了一个称为DataFrames的编程抽象,DataFrames可以充当分布式SQL查 ...
- Spark记录-SparkSQL相关学习
$spark-sql --help 查看帮助命令 $设置任务个数,在这里修改为20个 spark-sql>SET spark.sql.shuffle.partitions=20; $选择数据 ...
- Spark之 SparkSql整合hive
整合: 1,需要将hive-site.xml文件拷贝到Spark的conf目录下,这样就可以通过这个配置文件找到Hive的元数据以及数据存放位置. 2,如果Hive的元数据存放在Mysql中,我们还需 ...
- Spark之 SparkSql、DataFrame、DataSet介绍
SparkSql SparkSql是专门为spark设计的一个大数据仓库工具,就好比hive是专门为hadoop设计的一个大数据仓库工具一样. 特性: .易整合 可以将sql查询与spark应用程序进 ...
随机推荐
- 记一次线上环境 ES 主分片为分配故障
故障前提 ElasticSearch 版本:5.2 集群节点数:5 索引主分片数:5 索引分片副本数:1 线上环境ES存储的数据量很大,当天由于存储故障,导致一时间 5个节点的 ES 集群,同时有两个 ...
- 剖析虚幻渲染体系(12)- 移动端专题Part 1(UE移动端渲染分析)
目录 12.1 本篇概述 12.1.1 移动设备的特点 12.2 UE移动端渲染特性 12.2.1 Feature Level 12.2.2 Deferred Shading 12.2.3 Groun ...
- 设计模式学习-使用go实现桥接模式
桥接模式 前言 定义 优点 缺点 应用场景 代码实现 参考 桥接模式 前言 桥接模式的代码实现非常简单,但是理解起来稍微有点难度,并且应用场景也比较局限,所以,相当于代理模式来说,桥接模式在实际的项目 ...
- JVM启动参数详解
JVM启动参数以及具体的解释: -Xmx1024M 最大堆内存 -Xms1024M 初始化堆内存,正常和最大堆内存相同,减少动态改变的内存损耗 -Xmn384M 年轻代内存 -XX:PermSize= ...
- RabbitMQ 线上事故!慌的一批,脑袋一片空白。。。
前言 那天我和同事一起吃完晚饭回公司加班,然后就群里就有人@我说xxx商户说收不到推送,一开始觉得没啥.我第一反应是不是极光没注册上,就让客服通知商户,重新登录下试试.这边打开极光推送的后台进行检查. ...
- 9组-Alpha冲刺-2/6
一.基本情况 队名:不行就摆了吧 组长博客:https://www.cnblogs.com/Microsoft-hc/p/15534079.html 小组人数: 8 二.冲刺概况汇报 谢小龙 过去两天 ...
- Web优化躬行记(5)——网站优化
最近阅读了很多优秀的网站性能优化的文章,所以自己也想总结一些最近优化的手段和方法. 个人感觉性能优化的核心是:减少延迟,加速展现. 本文主要从产品设计.前端.后端和网络四个方面来诉说优化过程. 一.产 ...
- [atARC116F]Deque Game
假设两个操作者分别为$A$和$B$,其中$A$希望最大.$B$希望最小 (并不默认$A$为整局游戏的先手,仅是最终的结果考虑$A$为先手时) 记第$i$个队列第$j$个元素为$a_{i,j}$(其中$ ...
- [atARC077F]SS
(以下字符串下标从0开始,并定义$2s=s+s$) 考虑$f(S)$,即令$l=\max_{2i<|S|且S[0,i)=S[|S|-i,|S|)]}i$,则$f(S)=S+S[l,|S|-l)$ ...
- vue create is a Vue CLI 3 only command and you are using Vue CLI 2.9.6. You
这是因为你安装的是2.9的版本用了3.0的命令 解决方法:1.用2.9的命令初始化项目 vue init webpack my-project 2.卸载2.9升级到3.0