MapReduce学习总结之简介
执行步骤:1)准备Map处理的输入数据
2)Mapper处理
3)Shuffle
4)Reduce处理
5)结果输出
三、mapreduce核心概念:
1)split:交由MapReduce作业来处理的数据块,是MapReduce最小的计算单元。
HDFS:blocksize 是HDFS中最小的存储单元 128M
默认情况下:他们两是一一对应的,当然我们也可以手工设置他们之间的关系(不建议)
2)InputFormat:
将我们的输入数据进行分片(split): InputSplit[] getSplits(JobConf job, int numSplits) throws IOException;
TextInputFormat: 处理文本格式的数据
3)OutputFormat: 输出
4)Combiner:每一个map都可能会产生大量的本地输出,Combiner的作用就是对map端的输出先做一次合并,以减少在map和reduce节点之间的数据传输量,以提高网络IO性能,是MapReduce的一种优化手段之一,Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果
5) Partitioner:是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认是对key hash后再以reduce task数量取模
一、MapReduce概述:
1)源于Google的MapReduce论文,论文发表于2004年12月
2)Hadoop MapReduce 是Google MapReduce的克隆版
3)MapReduce的优点:海量数据离线处理,易开发,易运行。
4)MapReduce的缺点:实时流计算
二、MapReduce编程模型 word count 入门例子
word count:统计文件中单词出现的次数
word count mapreduce 计算流程图如下:
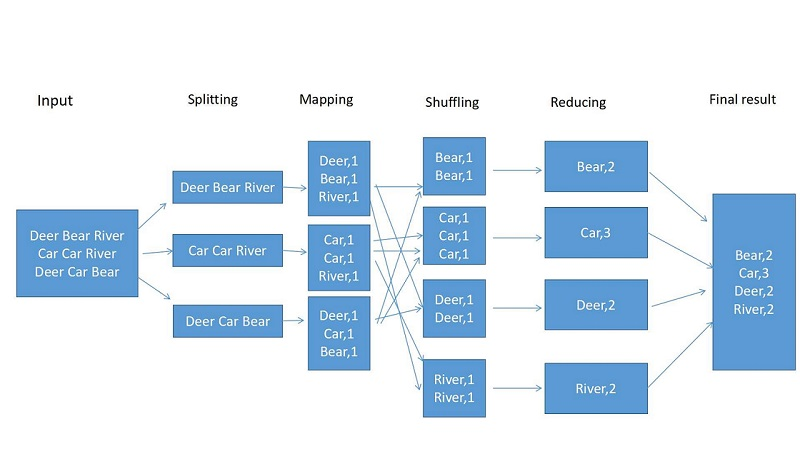
执行步骤:1)准备Map处理的输入数据
2)Mapper处理
3)Shuffle
4)Reduce处理
5)结果输出
三、mapreduce核心概念:
1)split:交由MapReduce作业来处理的数据块,是MapReduce最小的计算单元。
HDFS:blocksize 是HDFS中最小的存储单元 128M
默认情况下:他们两是一一对应的,当然我们也可以手工设置他们之间的关系(不建议)
2)InputFormat:
将我们的输入数据进行分片(split): InputSplit[] getSplits(JobConf job, int numSplits) throws IOException;
TextInputFormat: 处理文本格式的数据
3)OutputFormat: 输出
4)Combiner:每一个map都可能会产生大量的本地输出,Combiner的作用就是对map端的输出先做一次合并,以减少在map和reduce节点之间的数据传输量,以提高网络IO性能,是MapReduce的一种优化手段之一,Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果
5) Partitioner:是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认是对key hash后再以reduce task数量取模
MapReduce学习总结之简介的更多相关文章
- Linux内核学习笔记-1.简介和入门
原创文章,转载请注明:Linux内核学习笔记-1.简介和入门 By Lucio.Yang 部分内容来自:Linux Kernel Development(Third Edition),Robert L ...
- .NetCore微服务Surging新手傻瓜式 入门教程 学习日志---结构简介(二)
原文:.NetCore微服务Surging新手傻瓜式 入门教程 学习日志---结构简介(二) 先上项目解决方案图: 以上可以看出项目结构可以划分为4大块,1是surging的核心底层,2,3,4都可以 ...
- Netty学习——Apache Thrift 简介和下载安装
Netty学习——Apache Thrift 简介和下载安装 Apache Thrift 简介 本来由Facebook开发,捐献给了Apache,成了Apache的一个重要项目 可伸缩的,跨语言的服务 ...
- [转帖]Hyperledger Fabric 学习一:简介
Hyperledger Fabric 学习一:简介 https://www.jianshu.com/p/f971858b70f3?utm_campaign=maleskine&utm_cont ...
- Mahout学习之Mahout简介、安装、配置、入门程序测试
一.Mahout简介 查了Mahout的中文意思——驭象的人,再看看Mahout的logo,好吧,想和小黄象happy地玩耍,得顺便陪陪这位驭象人耍耍了... 附logo: (就是他,骑在象头上的那个 ...
- mapreduce学习指导及疑难解惑汇总
原文链接http://www.aboutyun.com/thread-7091-1-1.html 1.思想起源: 我们在学习mapreduce,首先我们从思想上来认识.其实任何的奇思妙想,抽象的,好的 ...
- 大数据技术之_14_Oozie学习_Oozie 的简介+Oozie 的功能模块介绍+Oozie 的部署+Oozie 的使用案列
第1章 Oozie 的简介第2章 Oozie 的功能模块介绍2.1 模块2.2 常用节点第3章 Oozie 的部署3.1 部署 Hadoop(CDH版本的)3.1.1 解压缩 CDH 版本的 hado ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- Uml学习-类图简介
类图(Class Diagram)简介 类图是面向对象分析(OOA,Object-Oriented Analysis)和面向对象设计(OOP,Object-Oriented Deisgn)思想的重要 ...
随机推荐
- MindSpore技术理解(上)
MindSpore技术理解(上) 引言 深度学习研究和应用在近几十年得到了爆炸式的发展,掀起了人工智能的第三次浪潮,并且在图像识别.语音识别与合成.无人驾驶.机器视觉等方面取得了巨大的成功.这也对算法 ...
- GStreamer 1.0 series序列示例
GStreamer 1.0 series序列示例 OpenEmbedded layer for GStreamer 1.0 这layer层为GStreamer 1.0框架提供了非官方的支持,用于Ope ...
- 5.7w字?GitHub标星120K的Java面试知识点总结,真就物超所值了
如果你觉得在一些程序员平台获取到的资料太乱学习起来毫无头绪,但是单看<Java编程思想>相似的一类的Java圣经"枯燥无味",那我推荐你看一下这份GitHub获得过12 ...
- JAVA复习题(一)基础知识
类的构造方法描述正确的是( )A. 类中的构造方法不能省略B. 构造方法必须与类同名,但方法不能与class同名C. 构造方法在一个对象被new时执行D. 一个类只能有一个构造方法我的答案:C正确答案 ...
- NX二次开发-创建(临时)坐标系
函数:UF_CSYS_create_csys() . UF_CSYS_create_temp_csys() 函数说明:创建坐标系 .创建临时坐标系 用法: #include <uf.h> ...
- 【VBA】测试程序运行时间,延时方法
测试程序运行时间 Dim start As Date start = Now() Dim i As Long For i = 0 To 10000000 ' 10 million Next Debug ...
- guavacache源码阅读笔记
guavacache源码阅读笔记 官方文档: https://github.com/google/guava/wiki/CachesExplained 中文版: https://www.jianshu ...
- csp-s模拟测试49(9.22)养花(分块/主席树)·折射(神仙DP)·画作
最近有点头晕........... T1 养花 考场我没想到正解,后来打的主席树,对于每个摸数查找1-(k-1),k-(2k-1)...的最大值,事实上还是很容易被卡的但是没有数据好像还比较友善, 对 ...
- 第11章 PADS功能使用技巧(2)-最全面
原文链接点击这里 七.Flood与Hatch有什么区别? 我们先看看PADS Layout Help 文档是怎么说的,如下图所示: 从检索到的帮助信息,我们可以得到Hatch与Pour的区别,原文如下 ...
- 从0到1用react+antd+redux搭建一个开箱即用的企业级管理后台系列(基础篇)
背景 最近因为要做一个新的管理后台项目,新公司大部分是用vue写的,技术栈这块也是想切到react上面来,所以,这次从0到1重新搭建一个react项目架子,需要考虑的东西的很多,包括目录结构.代码 ...