Innodb 锁的介绍
如下博文是参考如下博文内容,再加整理。
http://blog.chinaunix.net/uid-24111901-id-2627857.html
http://blog.csdn.net/wanghai__/article/details/7067118
InnoDB锁问题
InnoDB与MyISAM的最大不同有两点:一是支持事务(TRANSACTION);二是采用了行级锁。行级锁与表级锁本来就有许多不同之处,另外,事务的引入也带来了一些新问题。下面我们先介绍一点背景知识,然后详细讨论InnoDB的锁问题。
背景知识
1.事务(Transaction)及其ACID属性
事务是由一组SQL语句组成的逻辑处理单元,事务具有以下4个属性,通常简称为事务的ACID属性。
l 原子性(Atomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
l 一致性(Consistent):在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构(如B树索引或双向链表)也都必须是正确的。
l 隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
l 持久性(Durable):事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
银行转帐就是事务的一个典型例子。
2.并发事务处理带来的问题
相对于串行处理来说,并发事务处理能大大增加数据库资源的利用率,提高数据库系统的事务吞吐量,从而可以支持更多的用户。但并发事务处理也会带来一些问题,主要包括以下几种情况。
l 更新丢失(Lost Update):当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题--最后的更新覆盖了由其他事务所做的更新。例如,两个编辑人员制作了同一文档的电子副本。每个编辑人员独立地更改其副本,然后保存更改后的副本,这样就覆盖了原始文档。最后保存其更改副本的编辑人员覆盖另一个编辑人员所做的更改。如果在一个编辑人员完成并提交事务之前,另一个编辑人员不能访问同一文件,则可避免此问题。
l 脏读(Dirty Reads):一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些“脏”数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象地叫做"脏读"。
l 不可重复读(Non-Repeatable Reads):一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生了改变、或某些记录已经被删除了!这种现象就叫做“不可重复读”。
l 幻读(Phantom Reads):一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为“幻读”。
3.事务隔离级别
在上面讲到的并发事务处理带来的问题中,“更新丢失”通常是应该完全避免的。但防止更新丢失,并不能单靠数据库事务控制器来解决,需要应用程序对要更新的数据加必要的锁来解决,因此,防止更新丢失应该是应用的责任。
“脏读”、“不可重复读”和“幻读”,其实都是数据库读一致性问题,必须由数据库提供一定的事务隔离机制来解决。数据库实现事务隔离的方式,基本上可分为以下两种。
l 一种是在读取数据前,对其加锁,阻止其他事务对数据进行修改。
l 另一种是不用加任何锁,通过一定机制生成一个数据请求时间点的一致性数据快照(Snapshot),并用这个快照来提供一定级别(语句级或事务级)的一致性读取。从用户的角度来看,好象是数据库可以提供同一数据的多个版本,因此,这种技术叫做数据多版本并发控制(MultiVersion ConcurrencyControl,简称MVCC或MCC),也经常称为多版本数据库。
数 据库的事务隔离越严格,并发副作用越小,但付出的代价也就越大,因为事务隔离实质上就是使事务在一定程度上“串行化”进行,这显然与“并发”是矛盾的。同 时,不同的应用对读一致性和事务隔离程度的要求也是不同的,比如许多应用对“不可重复读”和“幻读”并不敏感,可能更关心数据并发访问的能力。
为 了解决“隔离”与“并发”的矛盾,ISO/ANSI SQL92定义了4个事务隔离级别,每个级别的隔离程度不同,允许出现的副作用也不同,应用可以根据自己的业务逻辑要求,通过选择不同的隔离级别来平衡 “隔离”与“并发”的矛盾。表20-5很好地概括了这4个隔离级别的特性。
表20-5 4种隔离级别比较
|
读数据一致性及允许的并发副作用 隔离级别 |
读数据一致性 |
脏读 |
不可重复读 |
幻读 |
|
未提交读(Read uncommitted) |
最低级别,只能保证不读取物理上损坏的数据 |
是 |
是 |
是 |
|
已提交度(Read committed) |
语句级 |
否 |
是 |
是 |
|
可重复读(Repeatable read) |
事务级 |
否 |
否 |
是 |
|
可序列化(Serializable) |
最高级别,事务级 |
否 |
否 |
否 |
最 后要说明的是:各具体数据库并不一定完全实现了上述4个隔离级别,例如,Oracle只提供Readcommitted和Serializable两个标准隔离级别,另外还提供自己定义的Read only隔离级别;SQL Server除支持上述ISO/ANSI SQL92定义的4个隔离级别外,还支持一个叫做“快照”的隔离级别,但严格来说它是一个用MVCC实现的Serializable隔离级别。MySQL 支持全部4个隔离级别,但在具体实现时,有一些特点,比如在一些隔离级别下是采用MVCC一致性读,但某些情况下又不是,这些内容在后面的章节中将会做进一步介绍。
获取InnoDB行锁争用情况
可以通过检查InnoDB_row_lock状态变量来分析系统上的行锁的争夺情况:
mysql> show status like 'innodb_row_lock%';
+-------------------------------+-------+
|Variable_name | Value |
+-------------------------------+-------+
| InnoDB_row_lock_current_waits | 0 |
|InnoDB_row_lock_time |0 |
| InnoDB_row_lock_time_avg |0 |
| InnoDB_row_lock_time_max |0 |
| InnoDB_row_lock_waits |0 |
+-------------------------------+-------+
5 rows in set (0.01 sec)
如果发现锁争用比较严重,如InnoDB_row_lock_waits和InnoDB_row_lock_time_avg的值比较高,还可以通过设置InnoDBMonitors来进一步观察发生锁冲突的表、数据行等,并分析锁争用的原因。
具体方法如下:
mysql> CREATE TABLE innodb_monitor(a INT) ENGINE=INNODB;
Query OK, 0 rows affected (0.14 sec)
然后就可以用下面的语句来进行查看:
mysql> Show innodb status\G;
*************************** 1. row ***************************
Type: InnoDB
Name:
Status:
…
…
------------
TRANSACTIONS
------------
Trx id counter 0 117472192
Purge done for trx's n:o < 0 117472190 undo n:o< 0 0
History list length 17
Total number of lock structs in row lock hash table 0
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 0 117472185, not started, process no11052, OS thread id 1158191456
MySQL thread id 200610, query id 291197 localhost root
---TRANSACTION 0 117472183, not started, process no11052, OS thread id 1158723936
MySQL thread id 199285, query id 291199 localhost root
Show innodb status
…
监视器可以通过发出下列语句来停止查看:
mysql> DROP TABLE innodb_monitor;
Query OK, 0 rows affected (0.05 sec)
设 置监视器后,在SHOW INNODB STATUS的显示内容中,会有详细的当前锁等待的信息,包括表名、锁类型、锁定记录的情况等,便于进行进一步的分析和问题的确定。打开监视器以后,默认情况下每15秒会向日志中记录监控的内容,如果长时间打开会导致.err文件变得非常的巨大,所以用户在确认问题原因之后,要记得删除监控表以关闭监视器,或者通过使用“--console”选项来启动服务器以关闭写日志文件。
InnoDB的行锁模式及加锁方法
InnoDB实现了以下两种类型的行锁。
l 共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
l 排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。
另外,为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是表锁。
l 意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的IS锁。
l 意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的IX锁。
上述锁模式的兼容情况具体如表20-6所示。
表20-6 InnoDB行锁模式兼容性列表
|
请求锁模式 是否兼容 当前锁模式 |
X |
IX |
S |
IS |
|
X |
冲突 |
冲突 |
冲突 |
冲突 |
|
IX |
冲突 |
兼容 |
冲突 |
兼容 |
|
S |
冲突 |
冲突 |
兼容 |
兼容 |
|
IS |
冲突 |
兼容 |
兼容 |
兼容 |
如果一个事务请求的锁模式与当前的锁兼容,InnoDB就将请求的锁授予该事务;反之,如果两者不兼容,该事务就要等待锁释放。
意向锁是InnoDB自动加的,不需用户干预。对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁(X);对于普通SELECT语句,InnoDB不会加任何锁;事务可以通过以下语句显示给记录集加共享锁或排他锁。
共享锁(S):SELECT* FROM table_name WHERE ... LOCK IN SHARE MODE。
排他锁(X):SELECT* FROM table_name WHERE ... FOR UPDATE。
用SELECT... IN SHARE MODE获得共享锁,主要用在需要数据依存关系时来确认某行记录是否存在,并确保没有人对这个记录进行UPDATE或者DELETE操作。但是如果当前事 务也需要对该记录进行更新操作,则很有可能造成死锁,对于锁定行记录后需要进行更新操作的应用,应该使用SELECT... FOR UPDATE方式获得排他锁。
在如表20-7所示的例子中,使用了SELECT ... IN SHARE MODE加锁后再更新记录,看看会出现什么情况,其中actor表的actor_id字段为主键。
表20-7 InnoDB存储引擎的共享锁例子
|
session_1 |
session_2 |
|
mysql> set autocommit = 0; Query OK, 0 rows affected (0.00 sec) mysql> select actor_id,first_name,last_name from actor where actor_id = 178; +----------+------------+-----------+ | actor_id | first_name | last_name | +----------+------------+-----------+ | 178 | LISA | MONROE | +----------+------------+-----------+ 1 row in set (0.00 sec) |
mysql> set autocommit = 0; Query OK, 0 rows affected (0.00 sec) mysql> select actor_id,first_name,last_name from actor where actor_id = 178; +----------+------------+-----------+ | actor_id | first_name | last_name | +----------+------------+-----------+ | 178 | LISA | MONROE | +----------+------------+-----------+ 1 row in set (0.00 sec) |
|
当前session对actor_id=178的记录加share mode 的共享锁: mysql> select actor_id,first_name,last_name from actor where actor_id = 178 lock in share mode; +----------+------------+-----------+ | actor_id | first_name | last_name | +----------+------------+-----------+ | 178 | LISA | MONROE | +----------+------------+-----------+ 1 row in set (0.01 sec) |
|
|
其他session仍然可以查询记录,并也可以对该记录加share mode的共享锁: mysql> select actor_id,first_name,last_name from actor where actor_id = 178 lock in share mode; +----------+------------+-----------+ | actor_id | first_name | last_name | +----------+------------+-----------+ | 178 | LISA | MONROE | +----------+------------+-----------+ 1 row in set (0.01 sec) |
|
|
当前session对锁定的记录进行更新操作,等待锁: mysql> update actor set last_name = 'MONROE T' where actor_id = 178; 等待 |
|
|
其他session也对该记录进行更新操作,则会导致死锁退出: mysql> update actor set last_name = 'MONROE T' where actor_id = 178; ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction |
|
|
获得锁后,可以成功更新: mysql> update actor set last_name = 'MONROE T' where actor_id = 178; Query OK, 1 row affected (17.67 sec) Rows matched: 1 Changed: 1 Warnings: 0 |
当使用SELECT...FORUPDATE加锁后再更新记录,出现如表20-8所示的情况。
表20-8 InnoDB存储引擎的排他锁例子
|
session_1 |
session_2 |
|
mysql> set autocommit = 0; Query OK, 0 rows affected (0.00 sec) mysql> select actor_id,first_name,last_name from actor where actor_id = 178; +----------+------------+-----------+ | actor_id | first_name | last_name | +----------+------------+-----------+ | 178 | LISA | MONROE | +----------+------------+-----------+ 1 row in set (0.00 sec) |
mysql> set autocommit = 0; Query OK, 0 rows affected (0.00 sec) mysql> select actor_id,first_name,last_name from actor where actor_id = 178; +----------+------------+-----------+ | actor_id | first_name | last_name | +----------+------------+-----------+ | 178 | LISA | MONROE | +----------+------------+-----------+ 1 row in set (0.00 sec) |
|
当前session对actor_id=178的记录加for update的共享锁: mysql> select actor_id,first_name,last_name from actor where actor_id = 178 for update; +----------+------------+-----------+ | actor_id | first_name | last_name | +----------+------------+-----------+ | 178 | LISA | MONROE | +----------+------------+-----------+ 1 row in set (0.00 sec) |
|
|
其他session可以查询该记录,但是不能对该记录加共享锁,会等待获得锁: mysql> select actor_id,first_name,last_name from actor where actor_id = 178; +----------+------------+-----------+ | actor_id | first_name | last_name | +----------+------------+-----------+ | 178 | LISA | MONROE | +----------+------------+-----------+ 1 row in set (0.00 sec) mysql> select actor_id,first_name,last_name from actor where actor_id = 178 for update; 等待 |
|
|
当前session可以对锁定的记录进行更新操作,更新后释放锁: mysql> update actor set last_name = 'MONROE T' where actor_id = 178; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> commit; Query OK, 0 rows affected (0.01 sec) |
|
|
其他session获得锁,得到其他session提交的记录: mysql> select actor_id,first_name,last_name from actor where actor_id = 178 for update; +----------+------------+-----------+ | actor_id | first_name | last_name | +----------+------------+-----------+ | 178 | LISA | MONROE T | +----------+------------+-----------+ 1 row in set (9.59 sec) |
InnoDB行锁实现方式
InnoDB行锁是通过给索引上的索引项加锁来实现的,这一点MySQL与Oracle不同,后者是通过在数据块中对相应数据行加锁来实现的。InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
在实际应用中,要特别注意InnoDB行锁的这一特性,不然的话,可能导致大量的锁冲突,从而影响并发性能。下面通过一些实际例子来加以说明。
(1)在不通过索引条件查询的时候,InnoDB确实使用的是表锁,而不是行锁。
在如表20-9所示的例子中,开始tab_no_index表没有索引:
mysql> create table tab_no_index(id int,name varchar(10))engine=innodb;
Query OK, 0 rows affected (0.15 sec)
mysql> insert into tab_no_index values(1,'1'),(2,'2'),(3,'3'),(4,'4');
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
表20-9 InnoDB存储引擎的表在不使用索引时使用表锁例子
|
session_1 |
session_2 |
|
mysql> set autocommit=0; Query OK, 0 rows affected (0.00 sec) mysql> select * from tab_no_index where id = 1 ; +------+------+ | id | name | +------+------+ | 1 | 1 | +------+------+ 1 row in set (0.00 sec) |
mysql> set autocommit=0; Query OK, 0 rows affected (0.00 sec) mysql> select * from tab_no_index where id = 2 ; +------+------+ | id | name | +------+------+ | 2 | 2 | +------+------+ 1 row in set (0.00 sec) |
|
mysql> select * from tab_no_index where id = 1 for update; +------+------+ | id | name | +------+------+ | 1 | 1 | +------+------+ 1 row in set (0.00 sec) |
|
|
mysql> select * from tab_no_index where id = 2 for update; 等待 |
在 如表20-9所示的例子中,看起来session_1只给一行加了排他锁,但session_2在请求其他行的排他锁时,却出现了锁等待!原因就是在没有 索引的情况下,InnoDB只能使用表锁。当我们给其增加一个索引后,InnoDB就只锁定了符合条件的行,如表20-10所示。
创建tab_with_index表,id字段有普通索引:
mysql> create table tab_with_index(id int,name varchar(10))engine=innodb;
Query OK, 0 rows affected (0.15 sec)
mysql> alter table tab_with_index add index id(id);
Query OK, 4 rows affected (0.24 sec)
Records: 4 Duplicates: 0 Warnings: 0
表20-10 InnoDB存储引擎的表在使用索引时使用行锁例子
|
session_1 |
session_2 |
|
mysql> set autocommit=0; Query OK, 0 rows affected (0.00 sec) mysql> select * from tab_with_index where id = 1 ; +------+------+ | id | name | +------+------+ | 1 | 1 | +------+------+ 1 row in set (0.00 sec) |
mysql> set autocommit=0; Query OK, 0 rows affected (0.00 sec) mysql> select * from tab_with_index where id = 2 ; +------+------+ | id | name | +------+------+ | 2 | 2 | +------+------+ 1 row in set (0.00 sec) |
|
mysql> select * from tab_with_index where id = 1 for update; +------+------+ | id | name | +------+------+ | 1 | 1 | +------+------+ 1 row in set (0.00 sec) |
|
|
mysql> select * from tab_with_index where id = 2 for update; +------+------+ | id | name | +------+------+ | 2 | 2 | +------+------+ 1 row in set (0.00 sec) |
(2)由于MySQL的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但是如果是使用相同的索引键,是会出现锁冲突的。应用设计的时候要注意这一点。
在如表20-11所示的例子中,表tab_with_index的id字段有索引,name字段没有索引:
mysql> alter table tab_with_index drop index name;
Query OK, 4 rows affected (0.22 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> insert into tab_with_index values(1,'4');
Query OK, 1 row affected (0.00 sec)
mysql> select * from tab_with_index where id = 1;
+------+------+
| id | name |
+------+------+
| 1 | 1 |
| 1 | 4 |
+------+------+
2 rows in set (0.00 sec)
表20-11 InnoDB存储引擎使用相同索引键的阻塞例子
|
session_1 |
session_2 |
|
mysql> set autocommit=0; Query OK, 0 rows affected (0.00 sec) |
mysql> set autocommit=0; Query OK, 0 rows affected (0.00 sec) |
|
mysql> select * from tab_with_index where id = 1 and name = '1' for update; +------+------+ | id | name | +------+------+ | 1 | 1 | +------+------+ 1 row in set (0.00 sec) |
|
|
虽然session_2访问的是和session_1不同的记录,但是因为使用了相同的索引,所以需要等待锁: mysql> select * from tab_with_index where id = 1 and name = '4' for update; 等待 |
(3)当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,另外,不论是使用主键索引、唯一索引或普通索引,InnoDB都会使用行锁来对数据加锁。
在如表20-12所示的例子中,表tab_with_index的id字段有主键索引,name字段有普通索引:
mysql> alter table tab_with_index add index name(name);
Query OK, 5 rows affected (0.23 sec)
Records: 5 Duplicates: 0 Warnings: 0
表20-12 InnoDB存储引擎的表使用不同索引的阻塞例子
|
session_1 |
session_2 |
|
mysql> set autocommit=0; Query OK, 0 rows affected (0.00 sec) |
mysql> set autocommit=0; Query OK, 0 rows affected (0.00 sec) |
|
mysql> select * from tab_with_index where id = 1 for update; +------+------+ | id | name | +------+------+ | 1 | 1 | | 1 | 4 | +------+------+ 2 rows in set (0.00 sec) |
|
|
Session_2使用name的索引访问记录,因为记录没有被索引,所以可以获得锁: mysql> select * from tab_with_index where name = '2' for update; +------+------+ | id | name | +------+------+ | 2 | 2 | +------+------+ 1 row in set (0.00 sec) |
|
|
由于访问的记录已经被session_1锁定,所以等待获得锁。: mysql> select * from tab_with_index where name = '4' for update; |
(4) 即便在条件中使用了索引字段,但是否使用索引来检索数据是由MySQL通过判断不同执行计划的代价来决定的,如果MySQL认为全表扫描效率更高,比如对一些很小的表,它就不会使用索引,这种情况下InnoDB将使用表锁,而不是行锁。因此,在分析锁冲突时,别忘了检查SQL的执行计划,以确认是否真正使 用了索引。关于MySQL在什么情况下不使用索引的详细讨论,参见本章“索引问题”一节的介绍。
在下面的例子中,检索值的数据类型与索引字段不同,虽然MySQL能够进行数据类型转换,但却不会使用索引,从而导致InnoDB使用表锁。通过用explain检查两条SQL的执行计划,我们可以清楚地看到了这一点。
例子中tab_with_index表的name字段有索引,但是name字段是varchar类型的,如果where条件中不是和varchar类型进行比较,则会对name进行类型转换,而执行的全表扫描。
mysql> alter table tab_no_index add index name(name);
Query OK, 4 rows affected (8.06 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> explain select * from tab_with_index where name = 1 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tab_with_index
type: ALL
possible_keys: name
key: NULL
key_len: NULL
ref: NULL
rows: 4
Extra: Using where
1 row in set (0.00 sec)
mysql> explain select * from tab_with_index where name = '1' \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tab_with_index
type: ref
possible_keys: name
key: name
key_len: 23
ref: const
rows: 1
Extra: Using where
1 row in set (0.00 sec)
InnoDB Record, Gap, andNext-Key Locks
在INNODB中,record-level lock大致有三种:Record, Gap, and Next-KeyLocks。
简单的说,Record Lock就是锁住某一行记录;
而Gap Lock会锁住某一段范围中的记录;Next-key Lock 则是前两者加起来的效果。
下面是MYSQL官方文档中相关内容的链接
https://dev.mysql.com/doc/refman/5.6/en/innodb-record-level-locks.html
幻影读问题
典型的幻影读问题如下,即在事务A的两次读过程中,有事务B插入了一条新的记录,导致同一事务两次读出的内容不同。具体见下图Fig.5.28.
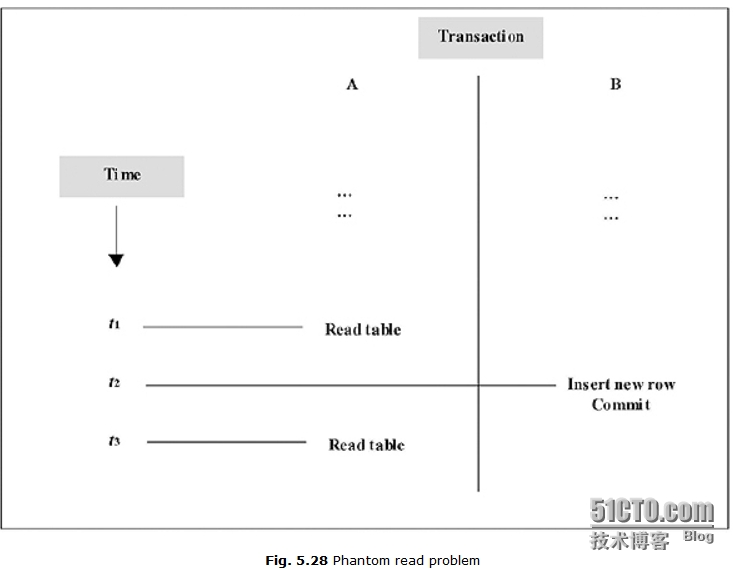
Gap Lock
MySQL通过锁定记录,以及前后记录间的间隙(Gap)来阻止上面的事件发生。即所谓Gap Lock。 它会导致了锁定范围的增大,在某些情况下可能会造成一些不符合预期的现象。下面是一个简单的测试例子,先对Gap Lock有个感性的认识
mysql> desc ts_column_log_test
-> ;
+------------+-------------+------+-----+---------------------+----------------+
| Field |Type | Null | Key|Default |Extra |
+------------+-------------+------+-----+---------------------+----------------+
|id |int(11) | NO | PRI|NULL |auto_increment |
| col_id |int(11) | NO | MUL|NULL | |
| start_time | timestamp |NO | | 0000-00-0000:00:00| |
| end_time |timestamp |NO | |0000-00-0000:00:00| |
| data_time | timestamp |NO | | 0000-00-0000:00:00| |
| status |varchar(30) |NO | |NULL | |
+------------+-------------+------+-----+---------------------+----------------+
6 rows in set (0.01 sec)
mysql> select * from ts_column_log_test;
+----+--------+---------------------+---------------------+---------------------+---------+
| id | col_id|start_time |end_time |data_time |status |
+----+--------+---------------------+---------------------+---------------------+---------+
| 1 | 2| 2011-12-1311:51:11 | 2011-12-13 11:51:11 | 2011-12-09 00:00:00 | running |
| 2 | 20 |2011-12-13 11:51:16| 2011-12-13 11:51:16 | 2011-12-09 00:00:00 | running |
| 3 | 120 |2011-12-13 11:51:20 |2011-12-13 11:51:20 | 2011-12-09 00:00:00 | running |
+----+--------+---------------------+---------------------+---------------------+---------+
3 rows in set (0.00 sec)
开启两个不同的会话,分别执行一些语句观察一下结果:
session1
mysql> set autocommit=0;
mysql> delete from ts_column_log_testwhere col_id=10;
Query OK, 0 rows affected(0.00sec) --此时[2,20)这个区间内的记录都已经被GAP LOCK锁住了,如果在其他事务中尝试插入这些值,则会等待
session2
mysql> set autocommit=0;
mysql> INSERT INTO ts_column_log_test(col_id,start_time, end_time, data_time, status) VALUES (1, NULL, NULL,'20111209','running'); --成功
...
mysql> INSERT INTO ts_column_log_test(col_id,start_time, end_time, data_time, status) VALUES (2, NULL, NULL,'20111209','running'); --等待
...
mysql> INSERT INTO ts_column_log_test(col_id,start_time, end_time, data_time, status) VALUES (19, NULL, NULL,'20111209','running'); --等待
...
上面的实验很简单,大家可以自己测一下。这里解释一下会产生这种现象的原因:session1中的delete语句中指定条件where col_id=10,这时MYSQL会去扫描索引,但是这个时候delete语句获取的不是一个RECORD LOCK,而是一个NEXT-KEY LOCK。以当前值(10)为例,会向左扫描至col_id=2这条记录,向右扫描至col_id=20这条记录,锁定区间为前闭后开,即[2,20)。
下面是摘自官方手册里的一句话:
DELETE FROM ... WHERE ... sets an exclusivenext-key lock onevery record the search encounters.
下面的链接里面有INNODB中各种不同的语句可能持有哪些锁的解释
http://dev.mysql.com/doc/refman/5.6/en/innodb-locks-set.html
间隙锁(Next-Key锁)
有了上面的Gap Lock的介绍作为铺垫,我想下面的内容应该容易理解多了。
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的 记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key锁)。
举例来说,假如emp表中只有101条记录,其empid的值分别是1,2,...,100,101,下面的SQL:
Select * from emp where empid > 100 for update;
是一个范围条件的检索,InnoDB不仅会对符合条件的empid值为101的记录加锁,也会对empid大于101(这些记录并不存在)的“间隙”加锁。
InnoDB 使用间隙锁的目的,一方面是为了防止幻读,以满足相关隔离级别的要求,对于上面的例子,要是不使用间隙锁,如果其他事务插入了empid大于100的任何 记录,那么本事务如果再次执行上述语句,就会发生幻读;另外一方面,是为了满足其恢复和复制的需要。文章的最末尾展示了由于幻读导致复制失效的一种场景。
很显然,在使用范围条件检索并锁定记录时,InnoDB这种加锁机制会阻塞符合条件范围内键值的并发插入,这往往会造成严重的锁等待。因此,在实际应用开发中,尤其是并发插入比较多的应用,我们要尽量优化业务逻辑,尽量使用相等条件来访问更新数据,避免使用范围条件。
还要特别说明的是,InnoDB除了通过范围条件加锁时使用间隙锁外,如果使用相等条件请求给一个不存在的记录加锁,InnoDB也会使用间隙锁!
在如表20-13所示的例子中,假如emp表中只有101条记录,其empid的值分别是1,2,......,100,101。
表20-13 InnoDB存储引擎的间隙锁阻塞例子
|
session_1 |
session_2 |
|
mysql> select @@tx_isolation; +-----------------+ | @@tx_isolation | +-----------------+ | REPEATABLE-READ | +-----------------+ 1 row in set (0.00 sec) mysql> set autocommit = 0; Query OK, 0 rows affected (0.00 sec) |
mysql> select @@tx_isolation; +-----------------+ | @@tx_isolation | +-----------------+ | REPEATABLE-READ | +-----------------+ 1 row in set (0.00 sec) mysql> set autocommit = 0; Query OK, 0 rows affected (0.00 sec) |
|
当前session对不存在的记录加for update的锁: mysql> select * from emp where empid = 102 for update; Empty set (0.00 sec) |
|
|
这时,如果其他session插入empid为201的记录(注意:这条记录并不存在),也会出现锁等待: mysql>insert into emp(empid,...) values(201,...); 阻塞等待 |
|
|
Session_1 执行rollback: mysql> rollback; Query OK, 0 rows affected (13.04 sec) |
|
|
由于其他session_1回退后释放了Next-Key锁,当前session可以获得锁并成功插入记录: mysql>insert into emp(empid,...) values(201,...); Query OK, 1 row affected (13.35 sec) |
幻读导致复制失效的问题

Innodb 锁的介绍的更多相关文章
- show engine innodb status 详细介绍
Contents Header1 SEMAPHORES. 1 LATEST DETECTED DEADLOCK. 3 TRANSACTIONS. 5 什么是purge操作... 5 FILE I/O. ...
- InnoDB锁机制分析
InnoDB锁机制常常困扰大家,不同的条件下往往表现出不同的锁竞争,在实际工作中经常要分析各种锁超时.死锁的问题.本文通过不同条件下的实验,利用InnoDB系统给出的各种信息,分析了锁的工作机制.通过 ...
- [转载] 数据库分析手记 —— InnoDB锁机制分析
作者:倪煜 InnoDB锁机制常常困扰大家,不同的条件下往往表现出不同的锁竞争,在实际工作中经常要分析各种锁超时.死锁的问题.本文通过不同条件下的实验,利用InnoDB系统给出的各种信息,分析了锁的工 ...
- MySQL · 引擎特性 · InnoDB 事务子系统介绍
http://mysql.taobao.org/monthly/2015/12/01/ 前言 在前面几期关于 InnoDB Redo 和 Undo 实现的铺垫后,本节我们从上层的角度来阐述 InnoD ...
- Innodb 锁系列2 事务锁
上一篇介绍了Innodb的同步机制锁:Innodb锁系列1 这一篇介绍一下Innodb的事务锁,只所以称为事务锁,是因为Innodb为实现事务的ACID特性,而添加的表锁或者行级锁. 这一部分分两篇来 ...
- Mysql锁机制介绍
Mysql锁机制介绍 一.概况MySQL的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制.比如,MyISAM和MEMORY存储引擎采用的是表级锁(table-level locking ...
- MySQL- InnoDB锁机制
InnoDB与MyISAM的最大不同有两点:一是支持事务(TRANSACTION):二是采用了行级锁.行级锁与表级锁本来就有许多不同之处,另外,事务的引入也带来了一些新问题.下面我们先介绍一点背景知识 ...
- MySQL InnoDB锁机制
概述: 锁机制在程序中是最常用的机制之一,当一个程序需要多线程并行访问同一资源时,为了避免一致性问题,通常采用锁机制来处理.在数据库的操作中也有相同的问题,当两个线程同时对一条数据进行操作,为了保证数 ...
- mysql InnoDB锁等待的查看及分析
说明:前面已经了解了InnoDB关于在出现锁等待的时候,会根据参数innodb_lock_wait_timeout的配置,判断是否需要进行timeout的操作,本文档介绍在出现锁等待时候的查看及分析处 ...
随机推荐
- 新的微芯片MCU增加了来自外部闪存的安全引导保护
新的微芯片MCU增加了来自外部闪存的安全引导保护 New Microchip MCU Adds Secure Boot Protection from External Flash 对于从外部SPI闪 ...
- Spring Cloud Data Flow整合Cloudfoundry UAA服务做权限控制
我最新最全的文章都在南瓜慢说 www.pkslow.com,欢迎大家来喝茶! 1 前言 关于Spring Cloud Data Flow这里不多介绍,有兴趣可以看下面的文章.本文主要介绍如何整合Dat ...
- Golang的一致性哈希实现
Golang的一致性哈希实现 一致性哈希的具体介绍,可以参考:http://www.cnblogs.com/haippy/archive/2011/12/10/2282943.html 1 imp ...
- 《面试补习》- Java集合知识梳理
一.ArrayList ArrayList 底层数据结构为 动态数组 ,所以我们可以将之称为数组队列. ArrayList 的依赖关系: public class ArrayList<E> ...
- 2、SpringBoot整合之SpringBoot整合servlet
SpringBoot整合servlet 一.创建SpringBoot项目,仅选择Web模块即可 二.在POM文件中添加依赖 <!-- 添加servlet依赖模块 --> <depen ...
- Pandas高级教程之:统计方法
目录 简介 变动百分百 Covariance协方差 Correlation相关系数 rank等级 简介 数据分析中经常会用到很多统计类的方法,本文将会介绍Pandas中使用到的统计方法. 变动百分百 ...
- 【译】在运行时编辑代码的 .NET 热重载
今天,我们很高兴向你介绍 Visual Studio 2019 中 16.11(预览版1)中的 .NET 热重载(通过 .NET 6(预览版4)中的 dotnet watch 命令行工具).在这篇文章 ...
- Vue $emit
案例演示 需求:点击子组件触发一个事件改变父组件的字体大小. <div id="app"> <p :style="{fontSize: fontSize ...
- 堆&&优先队列&&TreeMap
题目描述 5710. 积压订单中的订单总数 题解 题目不难,主要是要读懂题意,一步步模拟,代码较长,需要细心检查. 坑较多,比如我犯了很多傻逼问题:想都不想就拿1<<9+7当作100000 ...
- SpringBoot:SpringBoot项目的配置文件放在Jar包外加载
SpringBoot读取配置文件的优先级为: 第一.项目jar包同级下的config文件夹是优先级最高的,是在执行命令的目录下建config文件夹.(在jar包的同一目录下建config文件夹,执行命 ...