利用水文分析方法提取山脊线和山谷线(ArcPy实现)
一、背景
作为地形特征线的山脊线、山谷线对地形、地貌具有一定的控制作用。它们与山顶点、谷底点以及鞍部点等一起构成了地形起伏变化的骨架结构。同时由于山脊线具有分水性,山谷线具有合水性特征,使得它们在地形分析中具有特殊的意义。
二、目的
了解基于DEM水文分析方法提取山脊线和山谷线的原理;掌握水流方向、汇流累积量提取原理及方法。
三、要求
利用ArcGIS水文分析模块提取出样区的山脊线和山谷线。
四、数据
25m分辨率的DEM数据,区域面积约140km²(\ChP11 \Ex1目录中)。
五、算法思想
山脊线和山谷线的提取实质上也是分水线与汇水线的提取。因此,可以利用水文分析的方法进行提取。
对于山脊线而言,由于它同时也是分水线,而分水线的性质即为水流的起源点。所以,通过地表径流模拟计算之后,这些栅格的水流方向都应该只具有流出方向而不存在流入方向,即栅格的汇流累积量为零。因此,通过对零值的提取,就可得到分水线,即山脊线。
对于山谷线而言,可以利用反地形计算。即利用一个较大的数值减去原始DEM数据,得到与原始DEM地形相反的地形数据,使得原始的DEM中的山脊变成反地形的山谷,而原始DEM中的山谷在反地形中就变成了山脊。再利用山脊线的提取方法就可以实现山谷线的提取。但是此方法提取出的山脊和山谷位置有些偏差,可以利用正、负地形加以纠正。
流程图

六、模型构建器
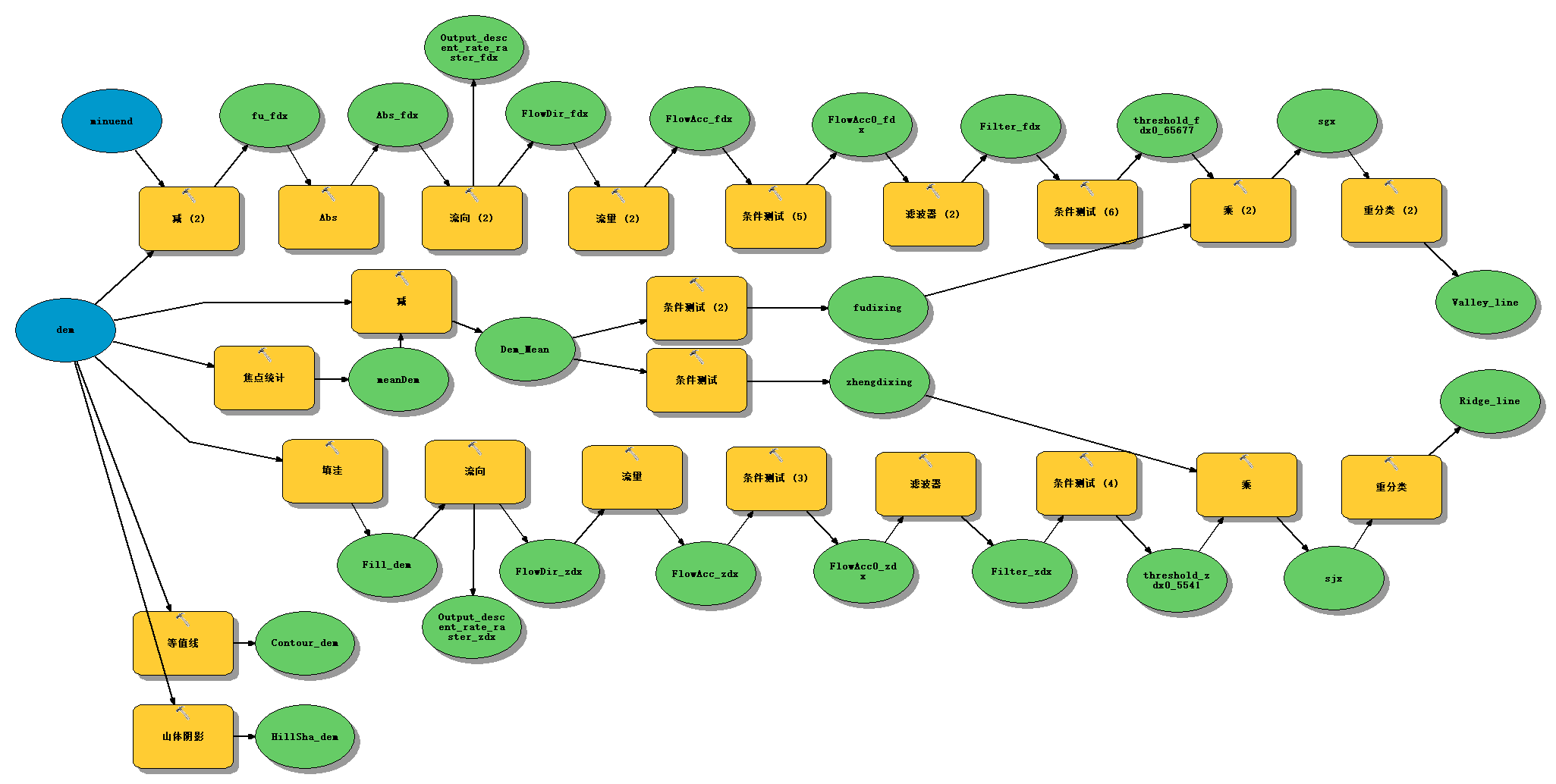
七、ArcPy实现
# -*- coding: utf-8 -*-
# ---------------------------------------------------------------------------
# 11-1 利用水文分析方法提取山脊线和山谷线.py
# Created on: 2021-10-11 10:09:40.00000
# (generated by ArcGIS/ModelBuilder)
# Description:
# ---------------------------------------------------------------------------
# Import arcpy module
import arcpy
import os
import shutil
import time
print time.asctime()
path = raw_input("请输入数据所在文件夹的绝对路径:").decode("utf-8")
# 开始计时
time_start = time.time()
paths = path + "\\result"
if not os.path.exists(paths):
os.mkdir(paths)
else:
shutil.rmtree(paths)
os.mkdir(paths)
# Local variables:
dem = path + "\\dem"
Fill_dem = "Fill_dem"
Output_descent_rate_raster_zdx = "Descent_zdx"
FlowDir_zdx = "FlowDir_zdx"
FlowAcc_zdx = "FlowAcc_zdx"
FlowAcc0_zdx = "FlowAcc0_zdx"
Filter_zdx = "Filter_zdx"
threshold_zdx0_5541 = "thresh_zdx0"
meanDem = "meanDem"
Dem_Mean = "Dem_Mean"
zhengdixing = "zhengdixing"
sjx = "sjx"
Ridge_line = "山脊线"
minuend = "5000"
fu_fdx = "fu_fdx"
Abs_fdx = "Abs_fdx"
Output_descent_rate_raster_fdx = "Descent_fdx"
fudixing = "fudixing"
FlowDir_fdx = "FlowDir_fdx"
FlowAcc_fdx = "FlowAcc_fdx"
FlowAcc0_fdx = "FlowAcc0_fdx"
Filter_fdx = "Filter_fdx"
threshold_fdx0_65677 = "thresh_fdx0"
sgx = "sgx"
Valley_line = "山谷线"
Contour_dem = "Contour_dem"
HillSha_dem = "HillSha_dem"
# Set Geoprocessing environments
print "Set Geoprocessing environments"
arcpy.env.scratchWorkspace = paths # 临时工作空间
arcpy.env.workspace = paths # 工作空间
arcpy.env.extent = dem # 处理范围
arcpy.env.cellSize = dem # 像元大小
arcpy.env.mask = dem # 掩膜
# Process: 填洼
print "Process: 填洼"
arcpy.gp.Fill_sa(dem, Fill_dem, "")
# Process: 流向
print "Process: 流向"
arcpy.gp.FlowDirection_sa(Fill_dem, FlowDir_zdx, "NORMAL", Output_descent_rate_raster_zdx, "D8")
# Process: 流量
print "Process: 流量"
arcpy.gp.FlowAccumulation_sa(FlowDir_zdx, FlowAcc_zdx, "", "FLOAT", "D8")
# Process: 条件测试 (3)
print "Process: 条件测试 (3)"
arcpy.gp.Test_sa(FlowAcc_zdx, "value=0", FlowAcc0_zdx)
# Process: 滤波器
print "Process: 滤波器"
arcpy.gp.Filter_sa(FlowAcc0_zdx, Filter_zdx, "LOW", "DATA")
# Process: 条件测试 (4)
print "Process: 条件测试 (4)"
arcpy.gp.Test_sa(Filter_zdx, "value>0.5541", threshold_zdx0_5541)
# Process: 焦点统计
print "Process: 焦点统计"
arcpy.gp.FocalStatistics_sa(dem, meanDem, "Rectangle 11 11 CELL", "MEAN", "DATA", "90")
# Process: 减
print "Process: 减"
arcpy.gp.Minus_sa(dem, meanDem, Dem_Mean)
# Process: 条件测试
print "Process: 条件测试"
arcpy.gp.Test_sa(Dem_Mean, "value>0", zhengdixing)
# Process: 乘
print "Process: 乘"
arcpy.gp.Times_sa(threshold_zdx0_5541, zhengdixing, sjx)
# Process: 重分类
print "Process: 重分类"
arcpy.gp.Reclassify_sa(sjx, "VALUE", "0 NODATA;1 1", Ridge_line, "DATA")
# Process: 减 (2)
print "Process: 减 (2)"
arcpy.gp.Minus_sa(dem, minuend, fu_fdx)
# Process: Abs
print "Process: Abs"
arcpy.gp.Abs_sa(fu_fdx, Abs_fdx)
# Process: 流向 (2)
print "Process: 流向 (2)"
arcpy.gp.FlowDirection_sa(Abs_fdx, FlowDir_fdx, "NORMAL", Output_descent_rate_raster_fdx, "D8")
# Process: 条件测试 (2)
print "Process: 条件测试 (2)"
arcpy.gp.Test_sa(Dem_Mean, "value<0", fudixing)
# Process: 流量 (2)
print "Process: 流量 (2)"
arcpy.gp.FlowAccumulation_sa(FlowDir_fdx, FlowAcc_fdx, "", "FLOAT", "D8")
# Process: 条件测试 (5)
print "Process: 条件测试 (5)"
arcpy.gp.Test_sa(FlowAcc_fdx, "value=0", FlowAcc0_fdx)
# Process: 滤波器 (2)
print "Process: 滤波器 (2)"
arcpy.gp.Filter_sa(FlowAcc0_fdx, Filter_fdx, "LOW", "DATA")
# Process: 条件测试 (6)
print "Process: 条件测试 (6)"
arcpy.gp.Test_sa(Filter_fdx, "value>0.65677", threshold_fdx0_65677)
# Process: 乘 (2)
print "Process: 乘 (2)"
arcpy.gp.Times_sa(fudixing, threshold_fdx0_65677, sgx)
# Process: 重分类 (2)
print "Process: 重分类 (2)"
arcpy.gp.Reclassify_sa(sgx, "VALUE", "0 NODATA;1 1", Valley_line, "DATA")
# Process: 等值线
print "Process: 等值线"
arcpy.gp.Contour_sa(dem, Contour_dem, "50", "0", "1", "CONTOUR", "")
# Process: 山体阴影
print "Process: 山体阴影"
arcpy.gp.HillShade_sa(dem, HillSha_dem, "315", "45", "NO_SHADOWS", "1")
save = ["hillsha_dem", "contour_dem", u"山脊线", u"山谷线"]
rasters = arcpy.ListRasters()
for raster in rasters:
if raster.lower() not in save:
print u"正在删除{}图层".format(raster)
arcpy.Delete_management(raster)
# 结束计时
time_end = time.time()
# 计算所用时间
time_all = time_end - time_start
print time.asctime()
print "执行完毕!>>><<< 共耗时{:.0f}分{:.2f}秒".format(time_all // 60, time_all % 60)
八、结果
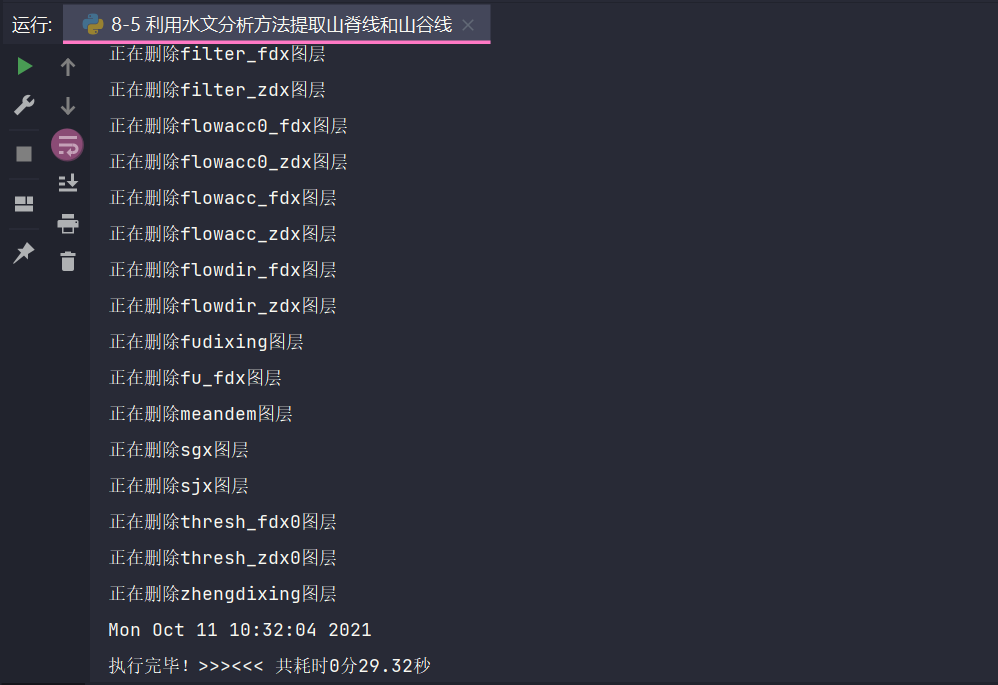



九、其它
在上实验课的时候,在老师那觅得相对上面,另一种更快捷的方式,而且也是比较通用,因为上面的那种方法,需要设置分界阈值,且的根据等值线和山体阴影来人工判断,而下面这种方法,虽然也是用水文分析方法,但不需要设置分界阈值,且对所有dem较为通用。
下面让我们来看看吧
模型构建器

跟上面的那种方法相比,主要省略了圈起来部分的步骤:
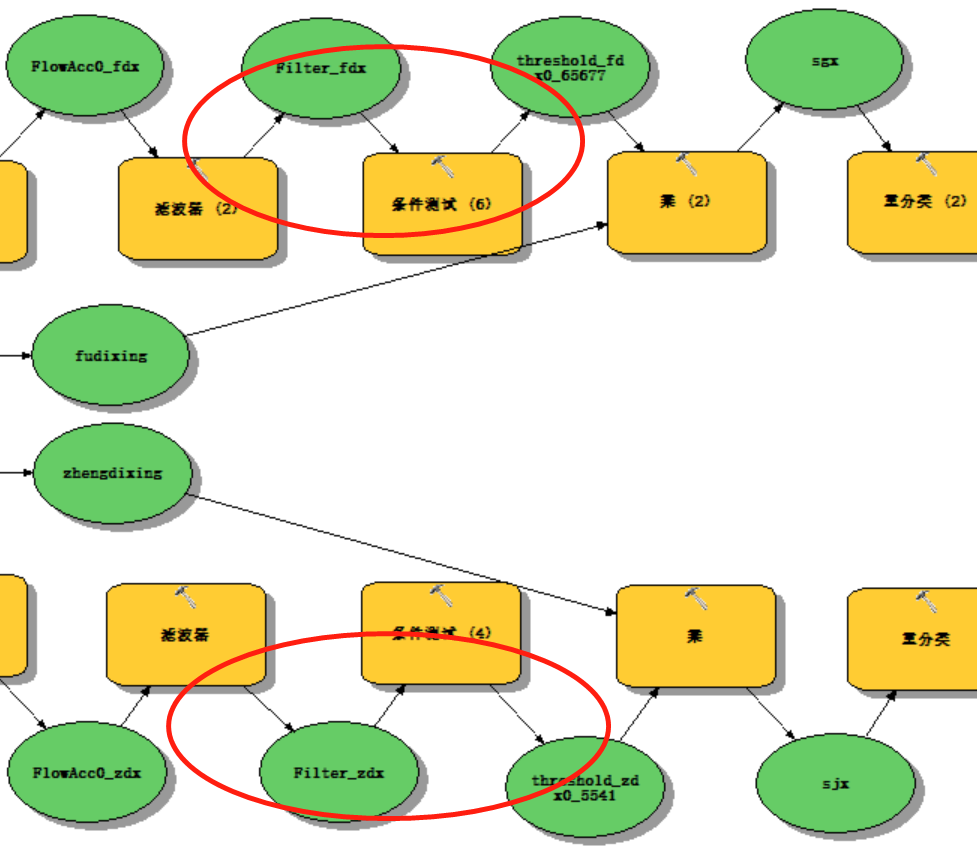
ArcPy实现
# -*- coding: utf-8 -*-
# ---------------------------------------------------------------------------
# 11-1 利用水文分析方法提取山脊线和山谷线2.py
# Created on: 2021-10-11 10:47:48.00000
# (generated by ArcGIS/ModelBuilder)
# Description:
# ---------------------------------------------------------------------------
# Import arcpy module
import arcpy
import os
import shutil
import time
print time.asctime()
path = raw_input("请输入数据所在文件夹的绝对路径:").decode("utf-8")
# 开始计时
time_start = time.time()
paths = path + "\\result"
if not os.path.exists(paths):
os.mkdir(paths)
else:
shutil.rmtree(paths)
os.mkdir(paths)
# Local variables:
dem = path + "\\dem"
Fill_dem = "Fill_dem"
Output_descent_rate_raster_zdx = "Descent_zdx"
meanDem = "meanDem"
Dem_Mean = "Dem_Mean"
zhengdixing = "zhengdixing"
FlowDir_zdx = "FlowDir_zdx"
FlowAcc_zdx = "FlowAcc_zdx"
FlowAcc0_zdx = "FlowAcc0_zdx"
sjx = "sjx"
Ridge_line = "山脊线"
minuend = "5000"
fu_fdx = "fu_fdx"
Abs_fdx = "Abs_fdx"
Output_descent_rate_raster_fdx = "Descent_fdx"
FlowDir_fdx = "FlowDir_fdx"
FlowAcc_fdx = "FlowAcc_fdx"
FlowAcc0_fdx = "FlowAcc0_fdx"
fudixing = "fudixing"
sgx = "sgx"
Valley_line = "山谷线"
# Set Geoprocessing environments
print "Set Geoprocessing environments"
arcpy.env.scratchWorkspace = paths # 临时工作空间
arcpy.env.workspace = paths # 工作空间
arcpy.env.extent = dem # 处理范围
arcpy.env.cellSize = dem # 像元大小
arcpy.env.mask = dem # 掩膜
# Process: 填洼
print "Process: 填洼"
arcpy.gp.Fill_sa(dem, Fill_dem, "")
# Process: 流向
print "Process: 流向"
arcpy.gp.FlowDirection_sa(Fill_dem, FlowDir_zdx, "NORMAL", Output_descent_rate_raster_zdx, "D8")
# Process: 焦点统计
print "Process: 焦点统计"
arcpy.gp.FocalStatistics_sa(dem, meanDem, "Rectangle 11 11 CELL", "MEAN", "DATA", "90")
# Process: 减
print "Process: 减"
arcpy.gp.Minus_sa(dem, meanDem, Dem_Mean)
# Process: 条件测试
print "Process: 条件测试"
arcpy.gp.Test_sa(Dem_Mean, "value>0", zhengdixing)
# Process: 流量
print "Process: 流量"
arcpy.gp.FlowAccumulation_sa(FlowDir_zdx, FlowAcc_zdx, "", "FLOAT", "D8")
# Process: 条件测试 (3)
print "Process: 条件测试 (3)"
arcpy.gp.Test_sa(FlowAcc_zdx, "value=0", FlowAcc0_zdx)
# Process: 乘
print "Process: 乘"
arcpy.gp.Times_sa(zhengdixing, FlowAcc0_zdx, sjx)
# Process: 重分类
print "Process: 重分类"
arcpy.gp.Reclassify_sa(sjx, "VALUE", "0 NODATA;1 1", Ridge_line, "DATA")
# Process: 减 (2)
print "Process: 减 (2)"
arcpy.gp.Minus_sa(dem, minuend, fu_fdx)
# Process: Abs
print "Process: Abs"
arcpy.gp.Abs_sa(fu_fdx, Abs_fdx)
# Process: 流向 (2)
print "Process: 流向 (2)"
arcpy.gp.FlowDirection_sa(Abs_fdx, FlowDir_fdx, "NORMAL", Output_descent_rate_raster_fdx, "D8")
# Process: 流量 (2)
print "Process: 流量 (2)"
arcpy.gp.FlowAccumulation_sa(FlowDir_fdx, FlowAcc_fdx, "", "FLOAT", "D8")
# Process: 条件测试 (5)
print "Process: 条件测试 (5)"
arcpy.gp.Test_sa(FlowAcc_fdx, "value=0", FlowAcc0_fdx)
# Process: 条件测试 (2)
print "Process: 条件测试 (2)"
arcpy.gp.Test_sa(Dem_Mean, "value<0", fudixing)
# Process: 乘 (2)
print "Process: 乘 (2)"
arcpy.gp.Times_sa(FlowAcc0_fdx, fudixing, sgx)
# Process: 重分类 (2)
print "Process: 重分类 (2)"
arcpy.gp.Reclassify_sa(sgx, "VALUE", "0 NODATA;1 1", Valley_line, "DATA")
save = [u"山脊线", u"山谷线"]
rasters = arcpy.ListRasters()
for raster in rasters:
if raster.lower() not in save:
print u"正在删除{}图层".format(raster)
arcpy.Delete_management(raster)
# 结束计时
time_end = time.time()
# 计算所用时间
time_all = time_end - time_start
print time.asctime()
print "执行完毕!>>><<< 共耗时{:.0f}分{:.2f}秒".format(time_all // 60, time_all % 60)
结果
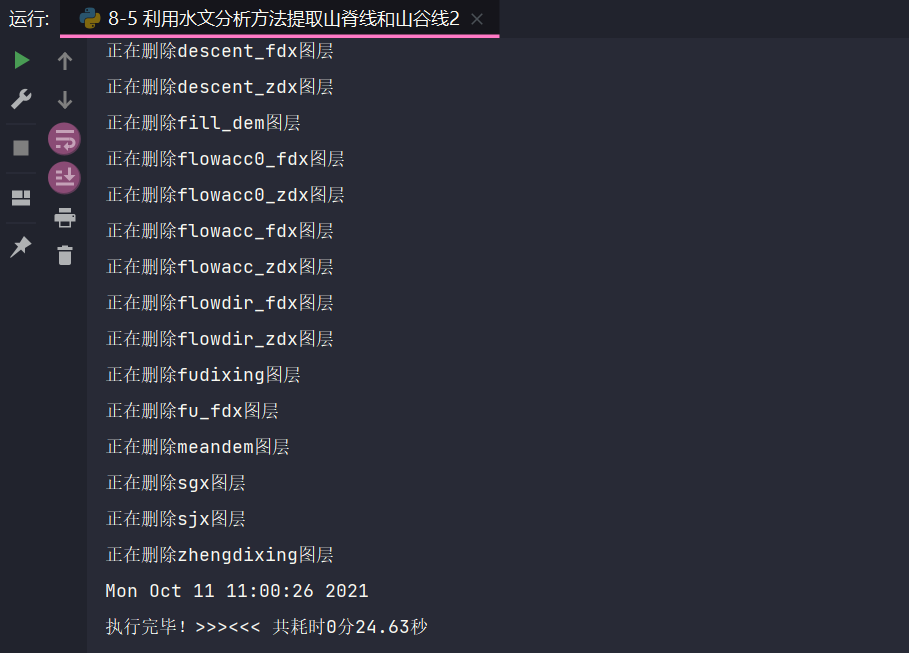

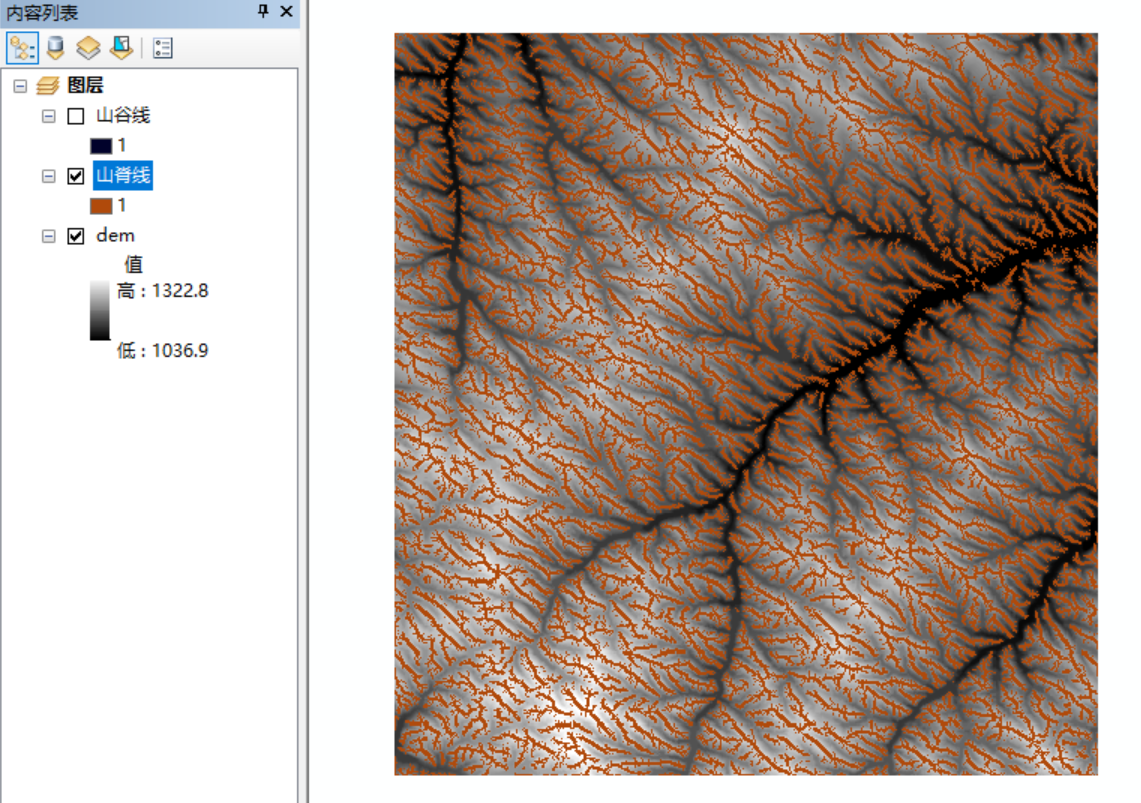
感觉上述二者差别不是很大,但是第一种的分界阈值对不同dem数据,需要再做判断,而第二种不需要设置分界阈值,就很方便,所以,比较推荐第二种。
实验结束 byebye~~~
利用水文分析方法提取山脊线和山谷线(ArcPy实现)的更多相关文章
- 利用ArcGIS水文分析工具提取河网
转自原文 利用ArcGIS水文分析工具提取河网(转) DEM包含有多种信息,ArcToolBox提供了利用DEM提取河网的方法,但是操作比较烦琐(帮助可参看Hydrologic analysis sa ...
- GIS案例学习笔记-水文分析河网提取地理建模
GIS案例学习笔记-水文分析河网提取地理建模 联系方式:谢老师,135-4855-4328,xiexiaokui#qq.com 目的:针对数字高程模型,通过水文分析,提取河网 操作时间:25分钟 数据 ...
- GIS与水文分析(1)GIS与水文学
GIS与水文分析(1)GIS与水文学 对于大部分GIS从业人员或者利用GIS作为研究方向的人员来说,水文学过于专业,更偏重于理论化,很难从GIS的角度来模拟和分析水文的过程.这其实是个普遍性的问题,任 ...
- ArcGIS案例学习笔记4_2_水文分析批处理地理建模
ArcGIS案例学习笔记4_2_水文分析批处理地理建模 联系方式:谢老师,135_4855_4328,xiexiaokui#139.com 概述 计划时间:第4天下午 目的:自动化,批量化,批处理,提 ...
- ArcGIS案例学习笔记4_1_水文分析
ArcGIS案例学习笔记4_1_水文分析 联系方式:谢老师,135_4855_4328,xiexiaokui#139.com 概述 计划时间:第4天上午 教程: pdf page478 数据:实验数据 ...
- ArcGIS水文分析实战教程(15)库容和淹没区计算
库容和淹没区计算 的基本流程 要计算库容就必须先计算出该集水区面积,并且通过不同的水位计算出淹没区,并利用淹没区去裁剪DEM数据,将水面与下垫面的体积计算出来,这就是水库的库容.由于有了前面的基础,这 ...
- Java安全之C3P0链利用与分析
Java安全之C3P0链利用与分析 0x00 前言 在一些比较极端情况下,C3P0链的使用还是挺频繁的. 0x01 利用方式 利用方式 在C3P0中有三种利用方式 http base JNDI HEX ...
- Android APP性能分析方法及工具
近期读到<Speed up your app>一文.这是一篇关于Android APP性能分析.优化的文章.在这篇文章中,作者介绍他的APP分析优化规则.使用的工具和方法.我觉得值得大家借 ...
- Linux下java进程CPU占用率高分析方法
Linux下java进程CPU占用率高分析方法 在工作当中,肯定会遇到由代码所导致的高CPU耗用以及内存溢出的情况.这种情况发生时,我们怎么去找出原因并解决. 一般解决方法是通过top命令找出消耗资源 ...
随机推荐
- 华为音频编辑服务(Audio Editor Kit),快速构建应用音频编辑能力
音频编辑服务(Audio Editor Kit)是华为为开发者开放的各类场景音频处理能力的集合,汇聚了华为在音乐.语音等相关音频领域的先进技术.音频编辑服务提供基础编辑.伴奏提取.空间渲染.变声降噪等 ...
- 源码解析.Net中Middleware的实现
前言 本篇继续之前的思路,不注重用法,如果还不知道有哪些用法的小伙伴,可以点击这里,微软文档说的很详细,在阅读本篇文章前,还是希望你对中间件有大致的了解,这样你读起来可能更加能够意会到意思.废话不多说 ...
- Git工具的使用教程二
1.3时光穿梭机--版本回退 版本回退分为两步骤进行操作: 步骤: 1.查看版本,确定需要回到的时候点 指令: git log git log ...
- golang channel原理
channel介绍 channel一个类型管道,通过它可以在goroutine之间发送和接收消息.它是Golang在语言层面提供的goroutine间的通信方式. 众所周知,Go依赖于称为CSP(Co ...
- NOIP模拟26「神炎皇·降雷皇·幻魔皇」
T1:神炎皇 又是数学题,气死,根本不会. 首先考虑式子\(a+b=ab\),我们取\(a\)与\(b\)的\(gcd\):\(d\),那么式子就可以改写成: \[(a'+b')*d=a'b' ...
- Android线程池使用介绍
本文主要使用kotlin,讨论Android开发中的线程池用法. 我们想使用线程的时候,可以直接创建子线程并启动 Thread { Log.d("rfDev", "rus ...
- 判断页面是在pc端还是移动端打开不同的页面
在pc端页面上的判断 var mobileAgent = new Array("iphone", "ipod", "ipad", " ...
- ARM架构安装ubuntu系统
一.简介 arm开发板制作系统是比较麻烦,不论使用busybox还是yocto制作根文件系统对新手都比太友好,除非深度定制,否则使用ubuntu系统既可以满足,把更多的精力放在应用开发上. 二.准备材 ...
- tomcat服务字符编码改为UTF-8
-Dfile.encoding=UTF-8 --仅供参考
- RocketMQ详解(三)启动运行原理
专题目录 RocketMQ详解(一)原理概览 RocketMQ详解(二)安装使用详解 RocketMQ详解(三)启动运行原理 RocketMQ详解(四)核心设计原理 RocketMQ详解(五)总结提高 ...