restframwork之序列化
一 restframwork为我们提供了一个快速实例,方便我们快速理解restframwork的序列化的原理。
二 restframwork序列化
开发我们的Web API(应用程序接口)的第一件事是为我们的Web API提供一种将代码片段实例序列化和反序列化为诸如json之类的表示形式的方式。我们可以通过声明与Django forms非常相似的序列化器(serializers)来实现。
1 首先创建一个序列化类
1 models部分:
from django.db import models # Create your models here. class Book(models.Model):
title=models.CharField(max_length=32)
price=models.IntegerField()
pub_date=models.DateField()
publish=models.ForeignKey("Publish")
authors=models.ManyToManyField("Author")
def __str__(self):
return self.title class Publish(models.Model):
name=models.CharField(max_length=32)
email=models.EmailField()
def __str__(self):
return self.name class Author(models.Model):
name=models.CharField(max_length=32)
age=models.IntegerField()
def __str__(self):
return self.name
2 view部分:
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import *
from django.shortcuts import HttpResponse
from django.core import serializers from rest_framework import serializers class BookSerializers(serializers.Serializer):
title=serializers.CharField(max_length=32)
price=serializers.IntegerField()
pub_date=serializers.DateField()
## 对于多对一的字段我们需要添加source=“publish.name” 从而取到我们对应模型类中的字段,而不是显示关联的id。
publish=serializers.CharField(source="publish.name")
#authors=serializers.CharField(source="authors.all") ### 那么对于多对多的字段我们需要自定义一个方法,来拿到对应模型类model中的所有字段,显示出来。
authors=serializers.SerializerMethodField()
def get_authors(self,obj): # 其中obj为当前模型类Book的对象。
temp=[]
for author in obj.authors.all():
temp.append(author.name) # 将author的名字添加到一个列表中。
return temp class BookViewSet(APIView): def get(self,request,*args,**kwargs):
book_list=Book.objects.all()
# 序列化方式1:使用django进行序列化操作。
# from django.forms.models import model_to_dict
# import json
# data=[]
# for obj in book_list:
# data.append(model_to_dict(obj))
# print(data)
# return HttpResponse("ok") # 序列化方式2: 继承serializers.Serialize进行自定制的序列化。
# data=serializers.serialize("json",book_list)
# return HttpResponse(data)
# 序列化方式3: ModelSerializer序列化组件
# bs=BookSerializers(book_list,many=True) return Response(bs.data)
以上三种序列化的方式:
第一种使用的还是django的序列化方式。
第二,三种则是使用restframwork的方式,分别继承:serializers.Serializer和serializers.ModelSerializer
3 ModelSerializer:
class BookSerializers(serializers.ModelSerializer):
class Meta:
model=Book
fields="__all__"
exclude=(‘nid’,)
depth=1
4 提交post的请求:
def post(self,request,*args,**kwargs):
bs=BookSerializers(data=request.data,many=False)
if bs.is_valid():
# print(bs.validated_data)
bs.save()
return Response(bs.data)
else:
return HttpResponse(bs.errors)
5 那么对于不同的请求条件不同,我们更新PUT的请求肯定与GET的请求是不用的url:


url:
urlpatterns = [
url(r'^admin/', admin.site.urls), url(r'^login/$', views.LoginView.as_view()),
url(r'^courses/$', views.CourseView.as_view()),
url(r'^publishes/$', views.PublishView.as_view()),
url(r'^books/$', views.BookView.as_view()),
url(r'^books/(?P<pk>\d+)/$', views.BookDetailView.as_view()), url(r'^authors/$', views.AuthorView.as_view()),
url(r'^authors/(?P<pk>\d+)/$', views.AuthorDetailView.as_view()),
]
view.py
class AuthorView(APIView):
def get(self, request):
author_list = Author.objects.all() # 方式1: Django的序列化组件
# ret=serialize("json",publish_list)
# 方式2:rest的序列化
As = AuthorSerializers(author_list, many=True)
# 序列化数据 return Response(As.data) def post(self, request): # 添加一条数据
print(request.data) As = AuthorSerializers(data=request.data)
if As.is_valid():
As.save() # 生成记录
return Response(As.data)
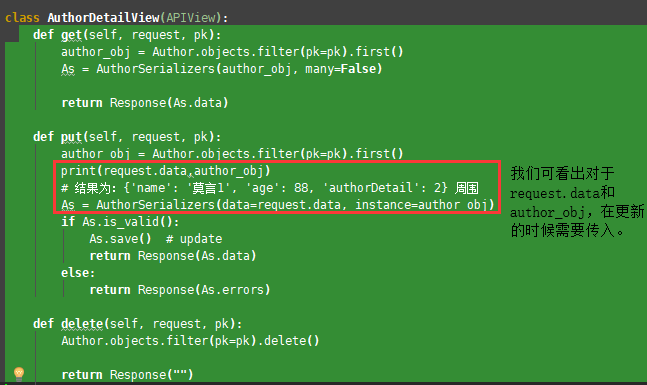
else: return Response(As.errors) class AuthorDetailView(APIView):
def get(self, request, pk):
author_obj = Author.objects.filter(pk=pk).first()
As = AuthorSerializers(author_obj, many=False) return Response(As.data) def put(self, request, pk):
author_obj = Author.objects.filter(pk=pk).first() As = AuthorSerializers(data=request.data, instance=author_obj)
if As.is_valid():
As.save() # update
return Response(As.data)
else:
return Response(As.errors) def delete(self, request, pk):
Author.objects.filter(pk=pk).delete() return Response("")
restframwork之序列化的更多相关文章
- day 94 RestFramework序列化组件与视图view
一 .复习 1. CBV流程 class BookView(View): def get(): pass def post(): pass #url(r'^books/', views.BookVie ...
- 【.net 深呼吸】序列化中的“引用保留”
假设 K 类中有两个属性/字段的类型相同,并且它们引用的是同一个对象实例,在序列化的默认处理中,会为每个引用单独生成数据. 看看下面两个类. [DataContract] public class 帅 ...
- 【.net 深呼吸】设置序列化中的最大数据量
欢迎收看本期的<老周吹牛>节目,由于剧组严重缺钱,故本节目无视频无声音.好,先看下面一个类声明. [DataContract] public class DemoObject { [Dat ...
- 用dubbo时遇到的一个序列化的坑
首先,这是标题党,问题并不是出现在序列化上,这是报错的一部分: Caused by: com.alibaba.dubbo.remoting.RemotingException: Failed to s ...
- Unity 序列化
Script Serialization http://docs.unity3d.com/Manual/script-Serialization.html 自定义序列化及例子: http://docs ...
- Unity 序列化 总结
查找了 Script Serialization http://docs.unity3d.com/Manual/script-Serialization.html 自定义序列化及例子: http:// ...
- [C#] C# 知识回顾 - 序列化
C# 知识回顾 - 序列化 [博主]反骨仔 [原文地址]http://www.cnblogs.com/liqingwen/p/5902005.html 目录 序列化的含义 通过序列化保存对象数据 众 ...
- Newtonsoft.Json设置类的属性不序列化
参考页面: http://www.yuanjiaocheng.net/webapi/parameter-binding.html http://www.yuanjiaocheng.net/webapi ...
- C# 序列化与反序列化几种格式的转换
这里介绍了几种方式之间的序列化与反序列化之间的转换 首先介绍的如何序列化,将object对象序列化常见的两种方式即string和xml对象; 第一种将object转换为string对象,这种比较简单没 ...
随机推荐
- node start - hello world http server
Write a file t1.js 'use strict'; const express = require('express'); // Constants const PORT = 8080; ...
- sql server 无法用sql server身份验证
1)首先,用windows身份验证进入服务器. 2)其次找到安全性,点击进入后,找到登录名为sa,然后右击属性. 3)在属性中找到常规,然后检查下自己的账号和密码,并且在状态中将登陆状态改成启用,否则 ...
- node 各模块及对应功能
node 各模块及对应功能 node 模块 对应功能 net 处理 TCP dgram 处理 UDP http 处理 HTTP/1 http2 处理 HTTP/2 https 处理 HTTPS tls ...
- java中==与equals
== ==可用于比较基本类型与引用类型,对于基本类型变量比较的是其存储的值是否相等,对于引用类型则比较的是其是否指向同一个对象. 如: int a = 10; int b = 20; double d ...
- HTMLParser 笔记
# 关于html.parse.HTMLParser的使用 from html.parser import HTMLParser class MyHtmlParser(HTMLParser): # 使用 ...
- Linux shell 将字符串分割成数组
原文链接:http://1985wanggang.blog.163.com/blog/static/776383320121745626320/ a="one,two,three,four& ...
- 在同一台电脑安装python 2 和3,并且怎样安装各自的pip和模块
安装python2.7 和 3.6不冲突直接安装就行 安装pip 访问https://pip.pypa.io/en/stable/installing/获取地址 curl https://bootst ...
- TCP/UDP端口列表(WIKIpedia)
计算机之间依照互联网传输层TCP/IP协议不同的协议通信,都有不同的对应端口.所以,利用短信(datagram)的UDP,所采用的端口号码不一定和采用TCP的端口号码一样.以下为两种通信协议的端口列表 ...
- OpenTSDB安装
时序数据库 时序数据库全称为时间序列数据库.主要用于处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时间序列数据.时间序列数据主要由电力行业.化工行业.物联网行业等各类 ...
- SoapUI 5.2.1 调试工具
SoapUI 5.2.1 调试工具 1.打开soapUI. 2.新建一个项目,实例如下: 点击ok后在soapUI界面左侧会显示出此项目,如图: 2.创建测试用例: a.新建用例组,选择此项目右键,新 ...