Python黑客——快速编写信息收集器
环境:
Python 3
模块:
Lxml
Request
Beautifulsoup
开始:
首先看一下目标站:
http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-1.html
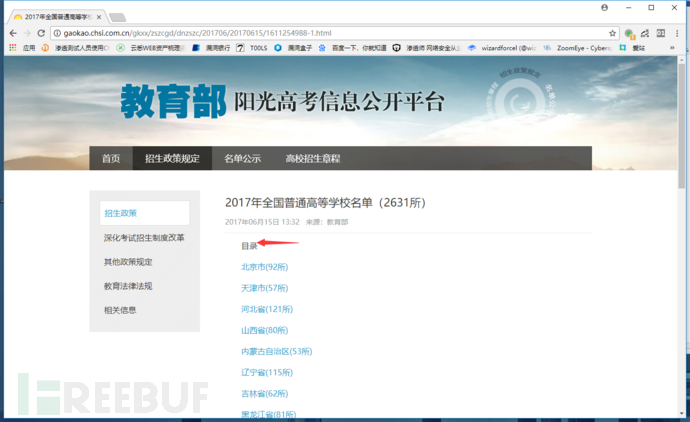
这里有一个目录:我们点击第一个北京市,就可以看到其中的表格,和北京市所有的大学名字
我们的目标就是吧每一个城市的所有大学,分别放在不同的txt文本中。
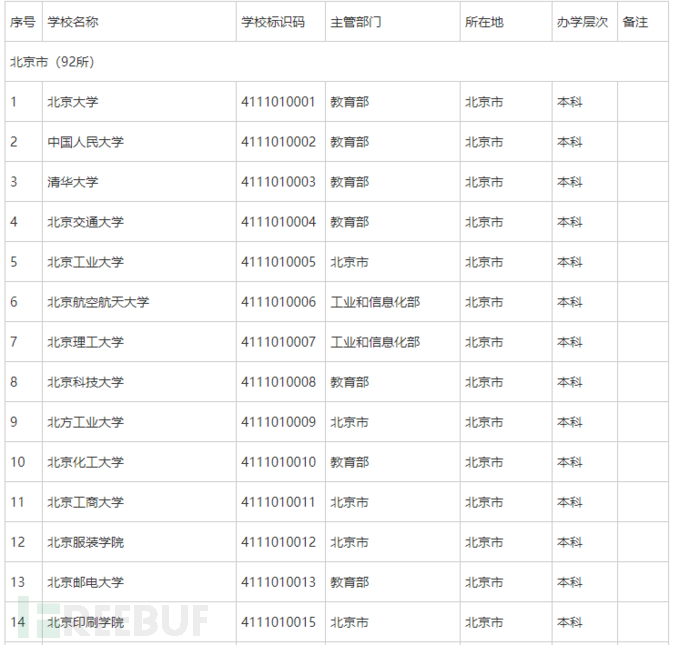
正式开始分析:
我们审查元素,我们要取的目标为学校名称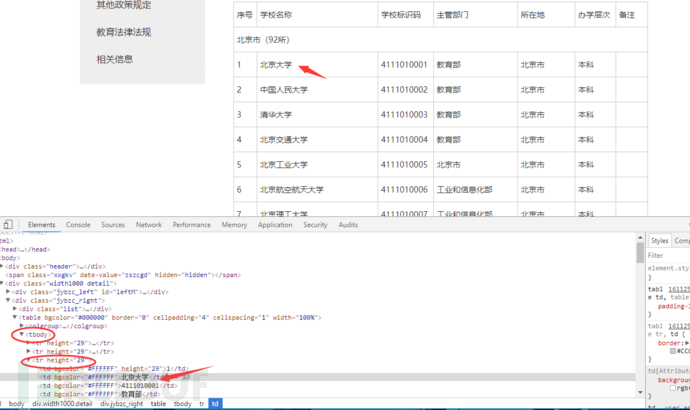
可以清晰的看到网页的结构,我们要取的目标在一个tbodyz中,并在一个tr标签内。继续分析下一个名字找到他们的规律
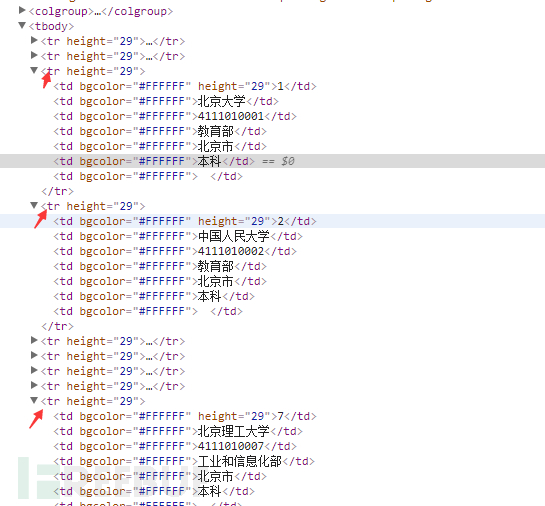
可以看到每个名字都在一个单独的tr标签中。
好我们在看一下这个北京市的url和第二个城市网页对应的url。
http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-2.html
http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-3.html
可以看到最后的数字不同,从二开始。依次增加。好我们已经基本获得了目标的信息,下面我们开始激动人心的敲代码。
我们先从一页开始。
#coding=utf-8
import requests
import lxml
from bs4 import BeautifulSoup as bs #导入我们的BF,并且命名为bs,名字太长了偷个懒。
def school(): #定义一个函数
url="http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-2.html"
r=requests.get(url=url) #利用requests请求我们的目标网站。
soup=bs(r.content,"lxml")#利用beautifulsoup解析,将返回内容赋值给soup
print (soup) #打印出内容。
if __name__ == '__main__': #程序开始运行的地方,需要调用刚才设置的函数,不然程序是不会运行的。
school()
写完之后点一下运行,成功返回发现并不需要设置头信息。省去了一些麻烦。

现在我们开始取内容:
我们的内容在<tr height=”29”>这个标签中,我们以这个标签为标准,查找所有的这个标签中的内容。代码是这样的。运行
def school(): url=”http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-2.html“
r=requests.get(url=url)
soup=bs(r.content,”lxml”) content=soup.find_all(name=”tr”,attrs={“height”:”29″})
print(content)
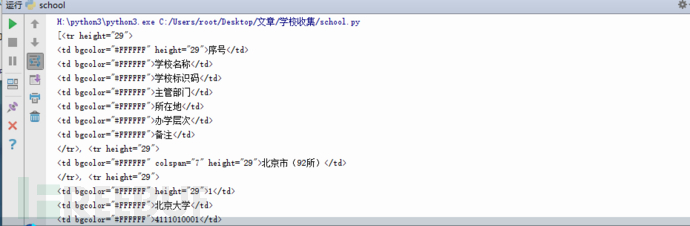 Ok 成功返回了我们需要的东西,但是有很多其他没有用的选项,现在我们要去掉这些东西。继续编辑school函数。我们需要用循环遍历我们的取出的内容。让每一个tr标签中的内容作为一个独立的列表,然后利用find_all方法找出而每一个td标签为list中的内容,方便我们取参数。学校名称位于第二个td标签中,在list中的位置则为1.代码如下。
Ok 成功返回了我们需要的东西,但是有很多其他没有用的选项,现在我们要去掉这些东西。继续编辑school函数。我们需要用循环遍历我们的取出的内容。让每一个tr标签中的内容作为一个独立的列表,然后利用find_all方法找出而每一个td标签为list中的内容,方便我们取参数。学校名称位于第二个td标签中,在list中的位置则为1.代码如下。
def school(): url="http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-2.html"
r=requests.get(url=url) soup=bs(r.content,"lxml") content=soup.find_all(name="tr",attrs={"height":"29"})
for content1 in content:
soup_content=bs(str(content1),"lxml")
soup_content1=soup_content.find_all(name="td")
print(soup_content1[1])
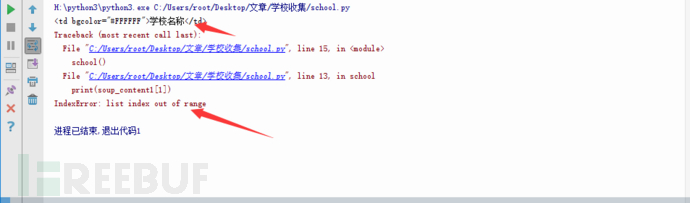
加好之后我们运行代码。发现报错了,不慌我们看一下报错的内容
报错大意为列出索引超出范围。但是我们发现还是成功返回了一个内容,我们再去分析一下网页源代码。
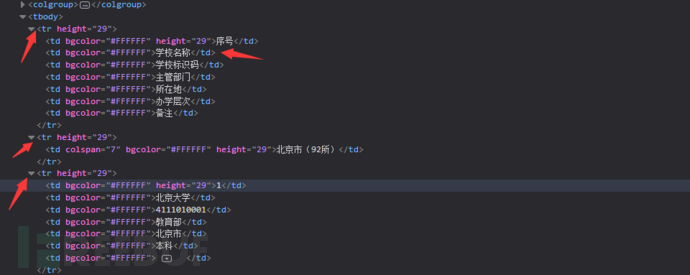
可以看到前三个tr标签,我们成功的取到了第一个tr标签中的”学校名称”这行的内容,然后第二个tr报错。我们的代码打印的的是list的第二个内容,但是在第二个tr标签中只有一个内容。然后剩下的都恢复了正常,我们怎么解决这个问题呢。可以用python的异常处理。当他报错时,然后忽略错误继续运行。把代码变成这样。
def school():
url="http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-2.html"
r=requests.get(url=url)
soup=bs(r.content,"lxml")
content=soup.find_all(name="tr",attrs={"height":"29"})
for content1 in content:
try: soup_content=bs(str(content1),"lxml") soup_content1=soup_content.find_all(name="td")
print(soup_content1[1])
except IndexError:
pass
再次运行。
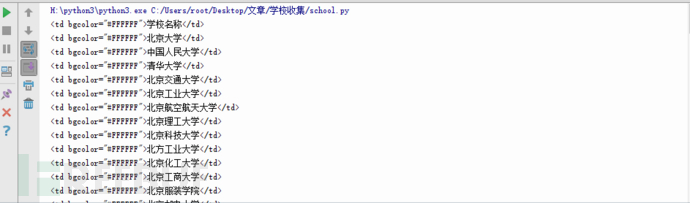
成功了,但这只是一个城市,我们还需要其他的。接下来我们需要用一个for循环,从2到33,每次加1,并修改url中的控制页面的参数中。
#coding=utf-8
import requests
import lxml
from bs4 import BeautifulSoup as bs
def school():
for i in range(2,34,1):
url="http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-%s.html"%(str(i))
r=requests.get(url=url)
soup=bs(r.content,"lxml")
content=soup.find_all(name="tr",attrs={"height":"29"})
for content1 in content:
try:
soup_content=bs(str(content1),"lxml")
soup_content1=soup_content.find_all(name="td")
print(soup_content1[1])
except IndexError:
pass
if __name__ == '__main__':
school()

我们可以看到不仅有北京的学校,还有天津的,当然下面所有的学校都打印出来了。我们还要去掉标签。修改打印为如下代码,这样就只会看到文本。
print(soup_content1[1].string)
主要功能就写完了,我们还需要,将他们分别存放在不同的文件夹内并保持为特定的文件名,当然我们不可能手动输入每个城市的名字。还记的我们刚才报错的地方吗,那个地方刚刚好有我们要的城市名称。理一下思路,我们首先从网页中取出城市名称,并新建一个对应城市名称的TXT文本,然后把我们取得的内容分别放入不同的文件内。为了防止报错停止,我们再加一个异常处理好让我们继续把我们的代码写完。
def school():
for i in range(2,34,1):
try:
url="http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-%s.html"%(str(i))
r=requests.get(url=url)
soup=bs(r.content,"lxml")
content2=soup.find_all(name="td",attrs={"colspan":"7"})[0].string
f1=open("%s.txt"%(content2),"w")
content=soup.find_all(name="tr",attrs={"height":"29"})
for content1 in content:
try:
soup_content=bs(str(content1),"lxml")
soup_content1=soup_content.find_all(name="td")
f1.write(soup_content1[1].string+"/n")
print(soup_content1[1].string)
except IndexError:
pass
except IndexError:
pass
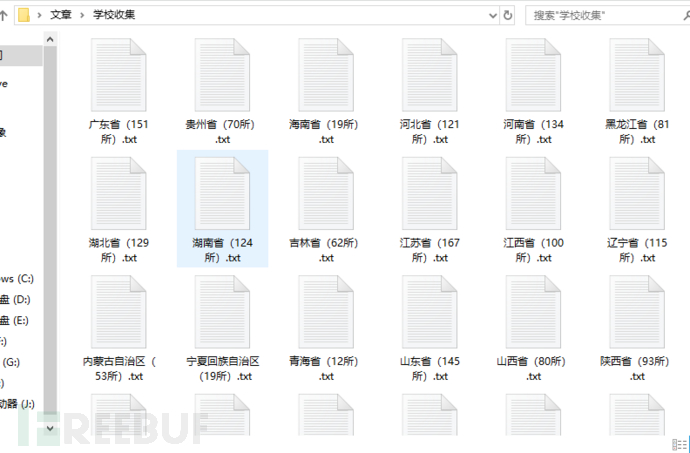 完整代码:
完整代码:
#coding=utf-8
import requests
import lxml
from bs4 import BeautifulSoup as bs
def school():
for i in range(2,34,1):
try:
url="http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-%s.html"%(str(i))
r=requests.get(url=url)
soup=bs(r.content,"lxml")
content2=soup.find_all(name="td",attrs={"colspan":"7"})[0].string
f1=open("%s.txt"%(content2),"w")
content=soup.find_all(name="tr",attrs={"height":"29"})
for content1 in content:
try:
soup_content=bs(str(content1),"lxml")
soup_content1=soup_content.find_all(name="td")
f1.write(soup_content1[1].string+"/n")
print(soup_content1[1].string)
except IndexError:
pass
except IndexError:
pass if __name__ == '__main__':
school()
总结:
这个程序的难度并不大,也没有用什么多线程,类,非常的简单,并不一定是代码越多的程序越好,有的时候我们只是想快速的完成我们的要实现的目标,这时候代码就要越简洁越好。希望可以给初学者一些好的学习思路,最后我之所以要再加一个异常处理,是因为又出现了一个和上面一样的报错,而为了快速实现我们的目标,我直接尝试添加一个异常处理,程序正常运行。最后,写的不好的地方,希望大家多多指点。
PS:附件我就不打包了,自己动手丰衣足食,虽然附上了所有代码但是还是希望大家可以自己动手写一下。
有问题大家可以留言哦,也欢迎大家到春秋论坛中来耍一耍 >>>点击跳转
Python黑客——快速编写信息收集器的更多相关文章
- python 信息收集器和CMS识别脚本
前言: 信息收集是渗透测试重要的一部分 这次我总结了前几次写的经验,将其 进化了一下 正文: 信息收集脚本的功能: 1.端口扫描 2.子域名挖掘 3.DNS查询 4.whois查询 5.旁站查询 CM ...
- 基于Python的渗透测试信息收集系统的设计和实现
信息收集系统的设计和实现 渗透测试是保卫网络安全的一种有效且必要的技术手段,而渗透测试的本质就是信息收集,信息搜集整理可为后续的情报跟进提供强大的保证,目标资产信息搜集的广度,决定渗透过程的复杂程度, ...
- python练习笔记——编写一个装饰器,模拟登录的简单验证
编写一个装饰器,模拟登录的简单验证(至验证用户名和密码是否正确) 如果用户名为 root 密码为 123则正确,否则不正确.如果验证不通过则不执行被修饰函数 #编写一个装饰器,模拟登录的简单验证 #只 ...
- Python练习笔记——编写一个装饰器,测算出一个函数的运行时间
import time def time_value(dec): def wrapper(*args,**kwargs): start_time = time.time() get_str = dec ...
- 小白日记5:kali渗透测试之被动信息收集(四)--theHarvester,metagoofil,meltag,个人专属密码字典--CUPP
1.theHarvester theHarvester是一个社会工程学工具,它通过搜索引擎.PGP服务器以及SHODAN数据库收集用户的email,子域名,主机,雇员名,开放端口和banner信息. ...
- python写一个信息收集四大件的脚本
0x0前言: 带来一首小歌: 之前看了小迪老师讲的课,仔细做了些笔记 然后打算将其写成一个脚本. 0x01准备: requests模块 socket模块 optparser模块 time模块 0x02 ...
- python信息收集之子域名
python信息收集之子域名 主要是以下3种思路: 字典爆破 搜索引擎 第三方网站 0x00 背景知识 list Python内置的一种数据类型是列表:list是一种有序的集合. >>&g ...
- python信息收集(一)
在渗透测试初期,需要进行大量的信息收集.一般情况下,信息收集可以分为两大类----被动信息收集和主动信息收集. 其中,被动信息收集主要是通过各种公开的渠道来获取目标系统的信息,例如:站 ...
- python编写实现抽奖器
这篇文章主要为大家详细介绍了python编写实现抽奖器,文中代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下 # coding=utf-8 import sys import os ...
随机推荐
- 尼克的任务(P1280)
题目链接:尼克的任务 这道题,有点难度,也不是太难,因为我都做出来了. 好,下面分析一下: 这道题,显然的动规,我们这样设计状态. 我们设d[i]为从第i分钟初开始到结束有多少空闲时间. 那么我们的转 ...
- Bootstrap之javascript组件
一 模态框 模态框放在body标签里面的,是body标签的子元素 静态实例: <div class="modal fade" tabindex="-1" ...
- 【转】python 修改os环境变量
举一个很简单的例子,如果你发现一个包或者模块,明明是有的,但是会发生这样的错误: >>> from algorithm import *Traceback (most recent ...
- 简单实现"Tomcat"
Tomcat的主要功能就是接收客户端的Http请求,然后将请求分发,并且将请求封装,最后返回资源给到客户端.话不多说,开干. 一.实现设计图 (禁止盗图,除非先转支付宝!!!) ...
- C[a,b]向量空间中的函数的线性相关性
- 学以致用十四-----打造一个简单的vim IDE
一.安装dircolors git clone https://github.com/seebi/dircolors-solarized.git cd dircolors-solarized/ mv ...
- CYS-Sqlite数据导入工具
界面: 曹永思 下载地址:asp.net 2.0版 Sqlite数据导入工具.zip 欢迎转载,转载请注明出处,希望帮到更多人.
- Angularjs的directive封装ztree
一般我们做web开发都会用到树,恰好ztree为我们提供了多种风格的树插件. 接下来就看看怎么用Angularjs的directive封装ztree <!DOCTYPE html> < ...
- DC画线
CClientDC hdc(this);//获取DC CPen pen(PS_SOLID,4,RGB(255,0,0));//创建一支红笔 CPen * pOldPen=hdc.SelectObjec ...
- js基础学习笔记(二)
2.1 输出内容(document.write) document.write() 可用于直接向 HTML 输出流写内容.简单的说就是直接在网页中输出内容. 第一种:输出内容用“”括起,直接输出&q ...