orcl 复杂查询
测试环境:
create table bqh6 (xm varchar2(10),bmbh number(2),bmmc varchar2(15),gz int);
insert into bqh6 values ('张三',01,'技术支持',3500);
insert into bqh6 values ('李四',02,'研发',4500);
insert into bqh6 values ('王五',03,'外业测绘',5000);
insert into bqh6 values ('小崔',02,'研发',8000);
insert into bqh6 values ('钱六',01,'技术支持',5500);
insert into bqh6 values ('赵二',03,'外业测绘',4500);
select * from bqh6

create table bqh7 (xm varchar2(10),bmbh number(2),bmmc varchar2(15), gwjb varchar2(10));
insert into bqh7 values ('张三',01,'技术支持','C');
insert into bqh7 values ('李四',02,'研发','C');
insert into bqh7 values ('王五',03,'外业测绘','A');
insert into bqh7 values ('小崔',02,'研发','A');
insert into bqh7 values ('钱六',01,'技术支持','A');
insert into bqh7 values ('赵二',03,'外业测绘','B');
select * from bqh7
分组函数:max, min, avg, sum, count
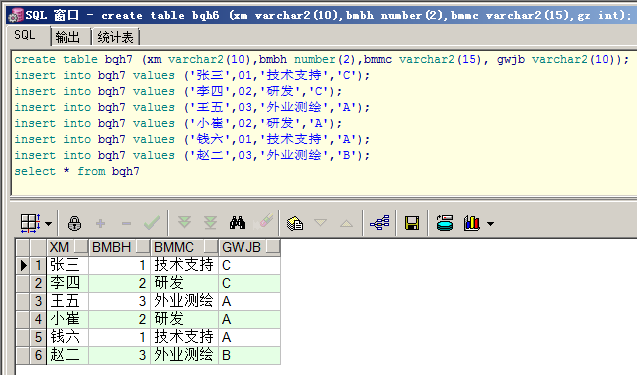
查询工资最高和最低的人的姓名:
select '最高的:'||xm,gz from bqh6 where gz=(select max(gz)from bqh6) union all
select '最低的:'||xm,gz from bqh6 where gz=(select min(gz)from bqh6)

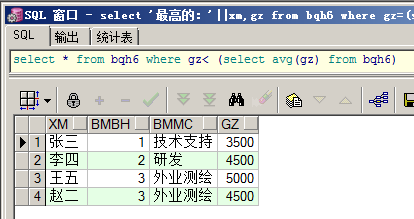
查询所有工资低于平均工资的人的信息:
select * from bqh6 where gz< (select avg(gz) from bqh6)
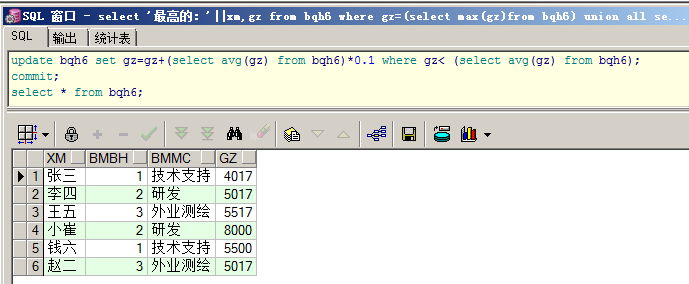
给所有低于平均工资的员工薪水上涨10%:
update bqh6 set gz=gz+(select avg(gz) from bqh6)*0.1 where gz< (select avg(gz) from bqh6);
commit;
select * from bqh6;
groupt by用于对查询结果分组统计
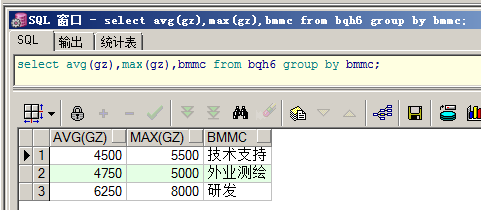
查询每个部门的平均工资和最高工资:
select avg(gz),max(gz),bmmc from bqh6 group by bmmc;
having子句用于限制分组结果显示
查询平均工资低于5000的部门名称和它的平均工资:
select bmmc,avg(gz) from bqh6 group by bmmc having avg(gz)<5000

注意:
分组函数(max,min,avg,count)只能出现在选择列表(select后),having和order by子句中;
如果select语句中同时包含group by,having和order by,他们的顺序必须是group by,having和order by (先分组→再抑制结果显示→最后分组);
在选择列中如果有列,表达式和分组函数,那么这些列和表达式必须有一个出现在group by子句中,否则就会报错。
----------------------------------------------------------------------------------
多表查询
查询雇员姓名及工资和所在部门的的岗位级别:
select a.xm,a.gz,b.gwjb from bqh6 a,bqh7 b where a.xm=b.xm
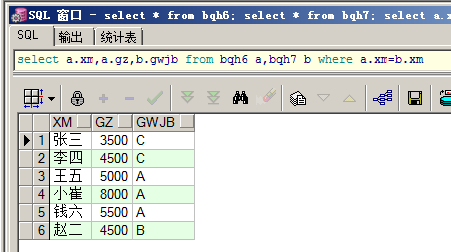
笛卡尔积,原则:多表查询的条件是至少不能少于表的个数-1
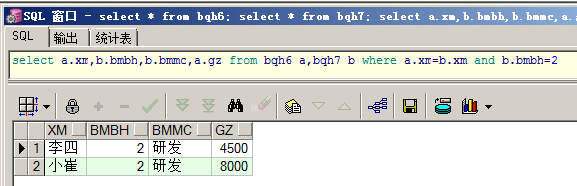
查询部门编号为10的部门名称、雇员姓名和工资:
select a.xm,b.bmbh,b.bmmc,a.gz from bqh6 a,bqh7 b where a.xm=b.xm and b.bmbh=2;
查询雇员姓名、工资以及所在部门名称并按部门排序
select a.xm,b.bmbh,b.bmmc,a.gz from bqh6 a,bqh7 b where a.xm=b.xm order by b.bmmc

order by 默认升序(asc),降序(desc)
子查询
.单行子查询
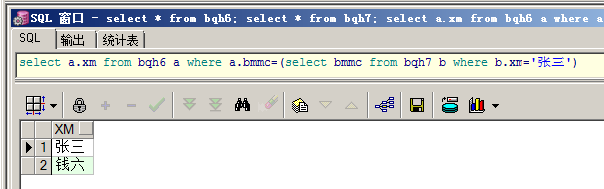
查询与张三同一部门的所有雇员姓名:
select a.xm from bqh6 a where a.bmmc=(select bmmc from bqh7 b where b.xm='张三')
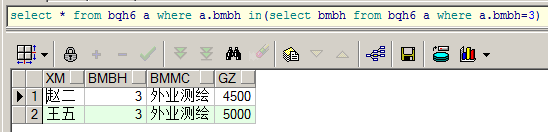
多行子查询
查询部门编号为3的雇员姓名、部门名称、工资:
all在多行子查询的使用:与每一个内容相匹配
查询工资比部门编号3的所有员工的工资高的雇员姓名、工资和部门名称:
>ALL:比子查询中返回的最大的记录还要大
<ALL:比子查询中返回的最小的记录还要小
①select xm,bmmc,gz from bqh6 where gz>all (select max(gz) from bqh6 where bmbh=3)
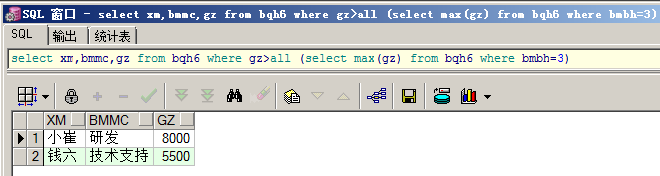
②select xm,bmmc,gz from bqh6 where gz>(select max(gz) from bqh6 where bmbh=3)
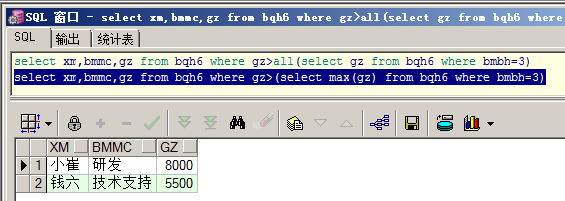
②的效率要高于①,因为①会逐条的对比,而②直接比较结果。
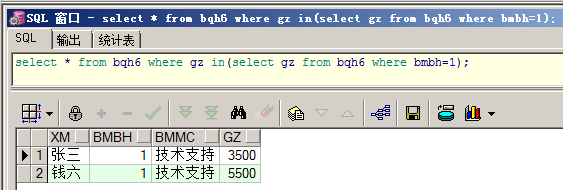
IN在子查询的使用:用于指定一个子查询的判断范围
查询部门编号为1的雇员姓名、部门名称及工资信息。
select * from bqh6 where gz in(select gz from bqh6 where bmbh=1);
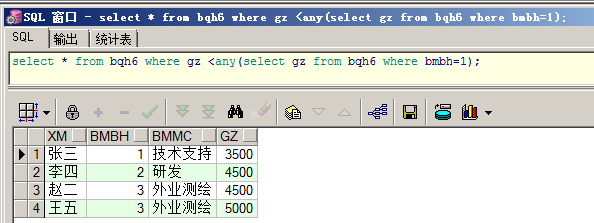
any在多行子查询的使用:与每一个内容相匹配,有三种匹配形式
①=any:功能与IN操作符是完全一样的
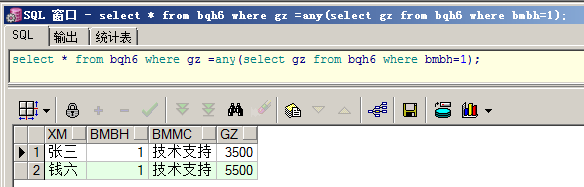
②>any:比子查询中返回记录最小的还要大的数据
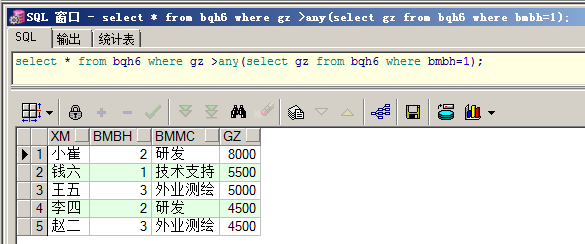
③<any:比子查询中返回记录最大的还要小的数据
FROM子句中使用子查询一般都是返回多行多列,可以将其当作一张数据表:
查询出每个部门的编号,名称,部门人数,平均工资
select a.xm,a.bmbh,a.bmmc,b.部门人数,b.平均工资 from bqh6 a,
(select bmbh bh,count(xm) 部门人数,avg(gz) 平均工资 from bqh6 group by bmbh) b
where a.bmbh=b.bh

注意:
当在from子句中使用子查询时,该子查询会被作为一个视图对待,因此叫做内嵌视图,当在from子句中使用子查询时,必须给子查询指定别名。给列取别名可以使用as,但是给表、视图、子查询起别名不可以用as
分页查询:ROWNUM为显示每一条记录动态自动生成行号。
为显示每一条记录动态自动生成行号
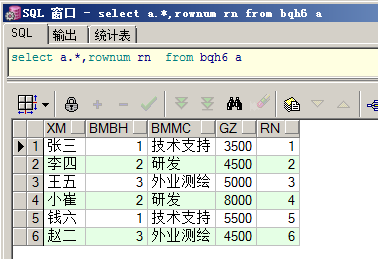
查询结果就会多出一列,rn,表示rownum,行号数,是Orcl分配的。
查询前条记录:
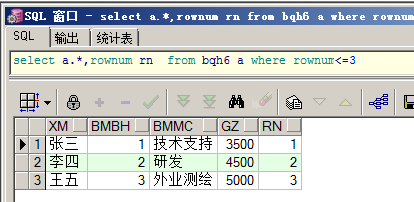
查询前3-6条记录:
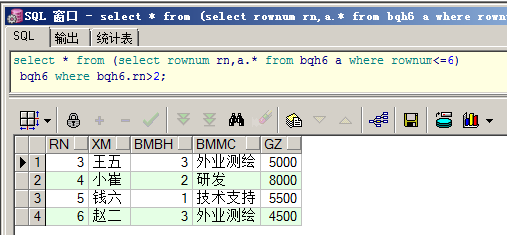
Oracle的分页是最复杂的,要使用2次子查询,但效率也是最高的,因为内部使用了2分查找的原理。MySql的分页是最简单的,直接一个limit就实现了
orcl 复杂查询的更多相关文章
- orcl数据库查询重复数据及删除重复数据方法
工作中,发现数据库表中有许多重复的数据,而这个时候老板需要统计表中有多少条数据时(不包含重复数据),只想说一句MMP,库中好几十万数据,肿么办,无奈只能自己在网上找语句,最终成功解救,下面是我一个实验 ...
- Orcl分页查询的语法示例
Orcle分页查询SQL sql = SELECT T.* FROM (SELECT X.*, ROWNUM AS RN FROM (SELECT * FROM +表名) X WHERE ROWNU ...
- 数据库---实验四 oracle的安全性和完整性控制
实验内容: (一) 授权 . 以dba用户的身份登陆oracle,创建用户u1+学号后四位,u2+学号后四位. SQL> create user u1_3985 identified by &q ...
- Oracle 删除数据后释放数据文件所占磁盘空间
测试的时候向数据库中插入了大量的数据,测试完成后删除了测试用户以及其全部数据,但是数据文件却没有缩小.经查阅资料之后发现这是 Oracle “高水位”所致,那么怎么把这些数据文件的大小降下来呢?解决办 ...
- DBlink 创建 删除 脚本
--配置SQLSERVER数据库的DBLINK --删除dblink Exec sp_droplinkedsrvlogin test,Null Exec sp_dropserver test --创建 ...
- python 连接 oracle 统计指定表格所有字段的缺失值数
python连接oracle -- qlalchemy import cx_Oracle as co import pandas as pd from sqlalchemy import crea ...
- 从零开始教你安装Oracle数据库
1.数据库安装 1.1下载 根据自己的操作系统位数,到oracle官网下载(以oracle 11g 为例) 之后把两个压缩包解压到同一个文件夹内(需要注意的是,这个文件夹路径名称中最好不要出现中文.空 ...
- JDBC_part1_Oracle数据库连接JDBC以及查询语句
本文为博主辛苦总结,希望自己以后返回来看的时候理解更深刻,也希望可以起到帮助初学者的作用. 转载请注明 出自 : luogg的博客园 谢谢配合! JDBC part1 JDBC概述 jdbc是一种用于 ...
- Mybatis框架的模糊查询(多种写法)、删除、添加(四)
学习Mybatis这么多天,那么我给大家分享一下我的学习成果.从最基础的开始配置. 一.创建一个web项目,看一下项目架构 二.说道项目就会想到需要什么jar 三.就是准备大配置链接Orcl数据库 & ...
随机推荐
- KVM:日常管理常用命令
1.查看.编辑及备份KVM 虚拟机配置文件 以及查看KVM 状态: 1.1.KVM 虚拟机默认的配置文件在 /etc/libvirt/qemu 目录下,默认是以虚拟机名称命名的.xml 文件,如下,: ...
- 玩转mongodb(八):分布式计算--MapReduce
MongoDB提供了MapReduce的聚合工具来实现任意复杂的逻辑,它非常强大,非常灵活.MapReduce使用JavaScript作为“查询语言”,能够在多台服务器之间并行执行.它会将一个大问题拆 ...
- helm之chartmuseum
1.概述 helm使得在k8s集群里面部署应用变得更简单,就像在linux系统里面使用yum安装软件一样,helm主要是利用的chart,首先看一下chart的结构: # tree zipkin zi ...
- docker搭建rabbitmq
Docker部署rabbitmq 1. 准备docker环境: # yum -y install docker # docker ps @如果有输出 CONTAINER ID IMA ...
- 【SpringBoot系列3】SpringBoot使用事务和AOP
前言: 因为SpringBoot操作两者实在太简单了,我就放一起来写了. 正文(事务): /** * springboot中运用事务 * 真的超级方便,直接加上注解就ok了,连配置都省了 * @ret ...
- MySQL5.7+版本一些问题
今天有一个需求.我要用本地的Java调用远程服务器的MySQL,因为我的MySQL版本为5.7.2,即比较新的版本.网上找的很多都比较旧,故贴此贴. 无密码: 初次安装MySQL可能没有设置密码,网上 ...
- java权限控制以及变量的初始化
知识是靠积累的,不断的温习会帮你让你遇到许多问题,解决完这些问题之后,会收获许多,233333333333333. 1.java访问控制符 2.java变量初始化问题 默认构造方法的名字与类名相同,它 ...
- 大明A+B(hdu1753)大数,java
大明A+B Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submissi ...
- XJad反编译工具
XJad反编译工具 我们写的java文件,编译后就会生成相应的字节码文件,也就是.java文件经过编译以后生成.class文件 现在,假设我们现在存在这样一个问题:就是我们想自己动手验证注释会不会被编 ...
- Windows平台如何部署scrapy
0.安装Anaconda 这个不教了,自己去Anaconda官网上下个安装包,装上就好. https://www.anaconda.com/distribution/ 1.使用Anaconda创建一个 ...