大数据之路week02 Collection 集合体系收尾(Set)
1、Set集合(理解)
(1)Set集合的特点
无序,唯一。
(2)HashSet集合(掌握)
A: 底层数据结构是哈希表(是一个元素为链表的数组)
B: 哈希表底层依赖两个方法: hashCode() 和 equals()
执行顺序:
首先比较哈希值是否相同
相同:继续执行equals()方法
返回true:元素重复了,不添加
返回false:直接把元素添加到集合
不同:就直接把元素添加到集合
1、人的类
package com.wyh.hashSet; /**
* @author WYH
* @version 2019年11月17日 上午9:21:02
*/
public class Person {
private String name;
private int age; public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public Person() {
super();
// TODO Auto-generated constructor stub
} public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
} //重写hashCode方法和equals方法
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
} }
2、测试类:
package com.wyh.hashSet; import java.util.HashSet; /**
* @author WYH
* @version 2019年11月17日 上午9:21:16
*/
public class HashSetDemo01 {
public static void main(String[] args) {
//创建HashSet集合
HashSet<Person> hs = new HashSet<Person>(); //创建Person类
Person p1 = new Person("小虎",22);
Person p2 = new Person("小强",23);
Person p3 = new Person("小虎",22);
Person p4 = new Person("小美",21);
Person p5 = new Person("小雪",21); //将对象添加到HashSet中去
hs.add(p1);
hs.add(p2);
hs.add(p3);
hs.add(p4);
hs.add(p5); //遍历
for(Person p : hs) {
System.out.println(p.getName()+"---"+p.getAge()); }
} }
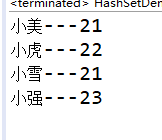
3、如下图,如果不重写hashCode()方法和equals()方法,运行结果,可以运行不报错,但是重复的元素也加入了。

4、重写后:
C:如何保证元素的唯一性呢?
由hashCode()和equals()保证的(如下图,流程)

D:开发的时候,代码非常的简单,自动生成即可。
E:HashSet存储字符串并遍历
package com.wyh.set; import java.util.HashSet; /**
* @author WYH
* @version 2019年11月16日 下午7:42:24
*
* HashSet在存储字符串的时候,为什么只存储相同的字符串只存储一个呢?
* 通过查看add方法的源码,我们发现这个方法的底层方法是依赖两个方法,hashCode()和equals()
*
*
*/
public class HashSetDemo01 {
public static void main(String[] args) {
HashSet<String> hs = new HashSet<String>(); hs.add("Hello");
hs.add("World");
hs.add("Java");
hs.add("World"); for(String s : hs) {
System.out.println(s);
} } }
F:HashSet存储自定义对象并遍历(对象的成员变量值相同即为同一个元素)
(3)TreeSet集合
A:底层数据结构是红黑树(是一个自平衡的二叉树)
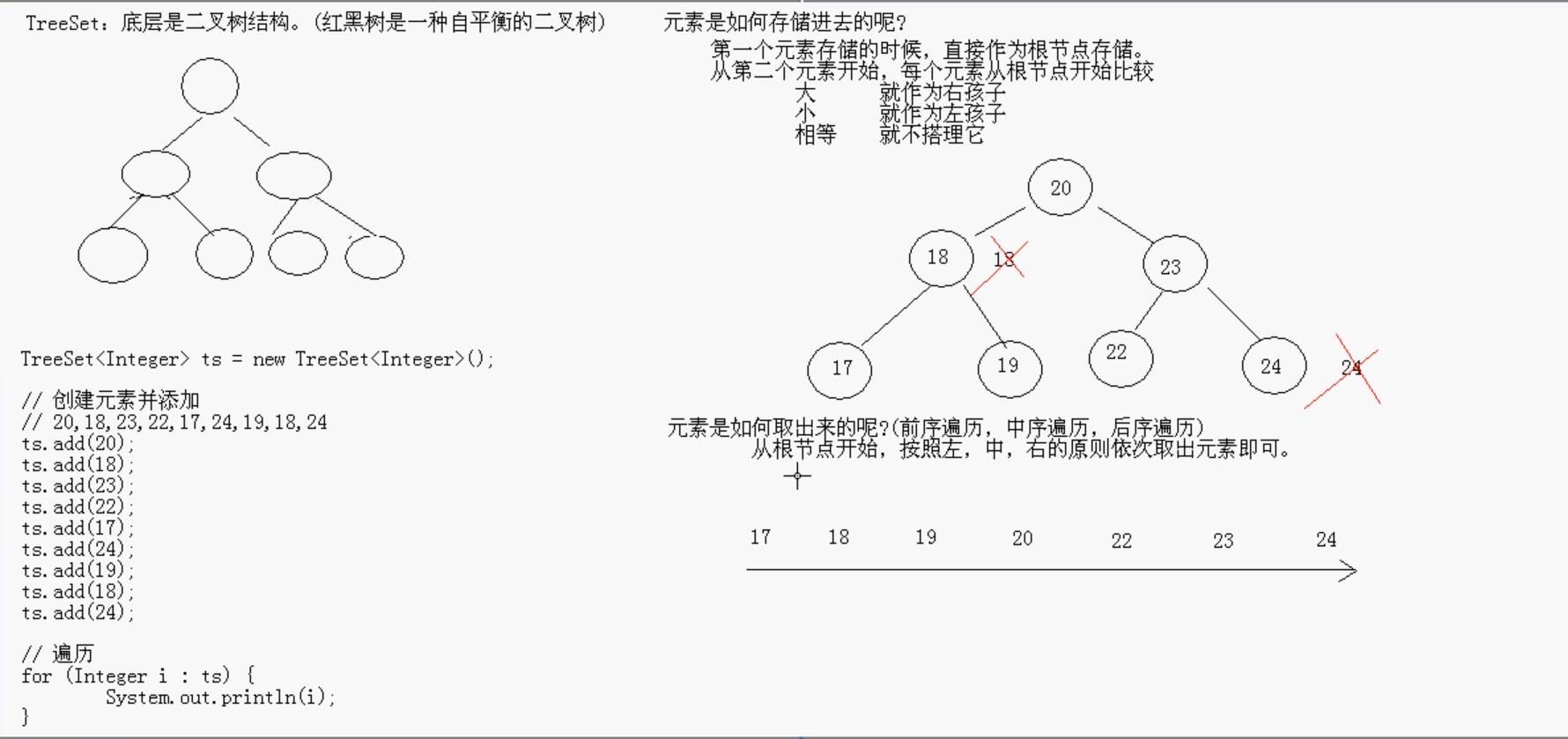
B: 保证元素的排序方式
a: 自然排序(元素具备比较性)
让元素所属的类实现Comparable接口(难点,需求会给出主要条件,但是需要我们分析次要条件,例如 需求是根据年龄的长度进行排序,但是我们还要考虑姓名的长度和内容)
学生类:
package com.wyh.treeSet; /**
* @author WYH
* @version 2019年11月17日 上午11:13:45
*/
public class Student2 implements Comparable<Student2>{
private String name;
private int age;
public Student2(String name, int age) {
super();
this.name = name;
this.age = age;
}
public Student2() {
super();
// TODO Auto-generated constructor stub
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int compareTo(Student2 s) {
int num = this.name.length() - s.name.length();
//次要条件1 姓名长度一样,内容不一定一样
int num2 = num == 0 ? (this.name.compareTo(s.name)) : num;
//次要条件2 姓名长度和内容一样,年龄不一定一样
int num3 = num2 == 0 ? this.age - s.age : num2;
return num3; } }
测试类:
如果不重写自然排序方法,就会报错,因为没有给定如何排序,也没有保证唯一性
// java.lang.ClassCastException: com.wyh.treeSet.Student cannot be cast to
// java.lang.Comparable
package com.wyh.treeSet; import java.util.TreeSet; /**
* @author WYH
* @version 2019年11月17日 下午2:27:13
*
* 根据年龄的长度进行排序
*/
public class TreeSetDemo03 {
public static void main(String[] args) {
TreeSet<Student2> ts = new TreeSet<Student2>(); // 创建学生对象
Student2 s1 = new Student2("王友虎", 22);
Student2 s2 = new Student2("赵以浩", 24);
Student2 s3 = new Student2("齐博源", 21);
Student2 s4 = new Student2("李先锋", 23);
Student2 s5 = new Student2("李宏灿", 22);
Student2 s6 = new Student2("薛长城", 23);
Student2 s7 = new Student2("黄天祥", 24);
Student2 s8 = new Student2("王友虎", 23); // 添加到TreeSet中
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
ts.add(s6);
ts.add(s7);
ts.add(s8); // 遍历
// 如果不重写自然排序方法,就会报错,因为没有给定如何排序,也没有保证唯一性
// java.lang.ClassCastException: com.wyh.treeSet.Student cannot be cast to
// java.lang.Comparable
for (Student2 s : ts) {
System.out.println(s.getName() + "---" + s.getAge());
} }
b: 比较器排序(集合具备比较性)
让集合构造方法接收Comparator的实现类对象(但是我们一般用匿名内部类的方式实现)
方式1、我们不用内部类的方式实现:
定义一个类实现Comparator<T> 接口,重写compare方法:
package com.wyh.treeSet2; import java.util.Comparator; /**
* @author WYH
* @version 2019年11月17日 下午2:48:22
*/
public class MyComparator implements Comparator<Student2> { @Override
public int compare(Student2 s1, Student2 s2) {
int num = s1.getName().length() - s2.getName().length();
int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num;
int num3 = num2 == 0 ? s1.getAge() - s2.getAge() : num2;
return num3;
} }
测试类:
package com.wyh.treeSet2; import java.util.Comparator;
import java.util.TreeSet; /**
* @author WYH
* @version 2019年11月17日 下午2:27:13
*
* 根据年龄的长度进行排序
*/
public class TreeSetDemo03 {
public static void main(String[] args) {
// TreeSet<Student2> ts = new TreeSet<Student2>();
TreeSet<Student2> ts = new TreeSet<Student2>(new MyComparator()); //如果一个方法的参数是接口,那么真正要的是实现这个接口的实现类
//匿名内部类可以是实现
/* TreeSet<Student2> ts = new TreeSet<Student2>(new Comparator<Student2>(){
@Override
public int compare(Student2 s1, Student2 s2) {
int num = s1.getName().length() - s2.getName().length();
int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num;
int num3 = num2 == 0 ? s1.getAge() - s2.getAge() : num2;
return num3;
}
});*/ // 创建学生对象
Student2 s1 = new Student2("王友虎", 22);
Student2 s2 = new Student2("赵以浩", 24);
Student2 s3 = new Student2("齐博源", 21);
Student2 s4 = new Student2("李先锋", 23);
Student2 s5 = new Student2("李宏灿", 22);
Student2 s6 = new Student2("薛长城", 23);
Student2 s7 = new Student2("黄天祥", 24);
Student2 s8 = new Student2("王友虎", 23); // 添加到TreeSet中
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
ts.add(s6);
ts.add(s7);
ts.add(s8); // 遍历
// 如果不重写自然排序方法,就会报错,因为没有给定如何排序,也没有保证唯一性
// java.lang.ClassCastException: com.wyh.treeSet.Student cannot be cast to
// java.lang.Comparable
for (Student2 s : ts) {
System.out.println(s.getName() + "---" + s.getAge());
} } }
方式2、用匿名内部类的方式实现:
package com.wyh.treeSet2; import java.util.Comparator;
import java.util.TreeSet; /**
* @author WYH
* @version 2019年11月17日 下午2:27:13
*
* 根据年龄的长度进行排序
*/
public class TreeSetDemo03 {
public static void main(String[] args) {
// TreeSet<Student2> ts = new TreeSet<Student2>();
// TreeSet<Student2> ts = new TreeSet<Student2>(new MyComparator()); //如果一个方法的参数是接口,那么真正要的是实现这个接口的实现类
//匿名内部类可以是实现
TreeSet<Student2> ts = new TreeSet<Student2>(new Comparator<Student2>(){
@Override
public int compare(Student2 s1, Student2 s2) {
int num = s1.getName().length() - s2.getName().length();
int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num;
int num3 = num2 == 0 ? s1.getAge() - s2.getAge() : num2;
return num3;
}
}); // 创建学生对象
Student2 s1 = new Student2("王友虎", 22);
Student2 s2 = new Student2("赵以浩", 24);
Student2 s3 = new Student2("齐博源", 21);
Student2 s4 = new Student2("李先锋", 23);
Student2 s5 = new Student2("李宏灿", 22);
Student2 s6 = new Student2("薛长城", 23);
Student2 s7 = new Student2("黄天祥", 24);
Student2 s8 = new Student2("王友虎", 23); // 添加到TreeSet中
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
ts.add(s6);
ts.add(s7);
ts.add(s8); // 遍历
// 如果不重写自然排序方法,就会报错,因为没有给定如何排序,也没有保证唯一性
// java.lang.ClassCastException: com.wyh.treeSet.Student cannot be cast to
// java.lang.Comparable
for (Student2 s : ts) {
System.out.println(s.getName() + "---" + s.getAge());
} } }
(4)案例:
A: 获取无重复的随机数(HashSet实现)
package com.wyh.HashSet_random; import java.util.Arrays;
import java.util.HashSet;
import java.util.Random; /**
* @author WYH
* @version 2019年11月17日 下午3:14:10
*
* 实现10个1-20的随机数
*
*
*
*/
public class HashSet_random_Demo {
public static void main(String[] args) {
//创建随机数对象
Random r = new Random(); //创建HashSet集合
HashSet<Integer> hs = new HashSet<Integer>(); //判断元素是否小于10
while(hs.size()<10) {
int num = r.nextInt(20)+1;
hs.add(num);
} Object[] obj = hs.toArray();
Arrays.sort(obj); //遍历集合
for(Object i : obj) {
System.out.println(i);
}
}
}
B: 键盘录入学生按照总分从搞到底输出(TreeSet且用匿名内部类实现)
package TreeSet_Scanner; import java.util.Comparator;
import java.util.Scanner;
import java.util.TreeSet; /**
* @author WYH
* @version 2019年11月17日 下午3:25:25
*
* 键盘录入5个学生信息,并且按照总分高低排序
*/
public class TreeSetDemo {
public static void main(String[] args) {
//创建控制台输入对象
Scanner sc = new Scanner(System.in); TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>(){
@Override
public int compare(Student s1, Student s2) {
/*int num = s1.getName().length() - s2.getName().length();
int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num;
int num3 = num2 == 0 ? s1.getSum() - s2.getSum() : num2;
return num3;*/
int num = s2.getSum() - s1.getSum();
int num2 = num == 0 ? s1.getMathNum() - s2.getMathNum() : num;
int num3 = num2 == 0 ? s1.getChinaNum() - s2.getChinaNum() : num2;
int num4 = num3 == 0 ? s1.getEngnishNum() - s2.getEngnishNum() : num3;
int num5 = num4 == 0 ? s1.getName().compareTo(s2.getName()) : num4;
return num5;
}
}); System.err.println("录入开始:");
for(int i = 0 ; i < 5 ; i++) {
Student s = new Student();
System.out.print("请输入第"+(i+1)+"个学生的姓名:");
String name = sc.next();
s.setName(name);
System.out.print("请输入该学生的数学成绩:");
int mNum = sc.nextInt();
s.setMathNum(mNum);
System.out.print("请输入该学生的语文成绩:");
int cNum = sc.nextInt();
s.setChinaNum(cNum);
System.out.print("请输入该学生的英语成绩:");
int eNum = sc.nextInt();
s.setEngnishNum(eNum); int sum = mNum + cNum + eNum;
s.setSum(sum); ts.add(s);
System.out.println();
}
System.err.println("录入结束!"); System.out.println("姓名\t数学成绩\t语文成绩\t英语成绩\t总分");
for(Student s : ts) {
System.out.println(s.getName()+"\t"+s.getMathNum()+"\t"+s.getChinaNum()+"\t"+s.getEngnishNum()
+"\t"+s.getSum());
} } }
2、Collection 集合体系 总结:
我们学完了Set集合,这个Collection体系下的另一个大模块,我们再来总结一下,把漏的LinkedList也总结一下:
Collection
| - - List 有序,可重复
| - - ArrayList
底层数据结构是数组,查询快,增删慢。
线程不安全,效率高。
| - - Vector
底层数据结构是数组,查询快,增删慢。
线程安全,效率低。
| - - LinkedList
底层数据结构是链表,查询慢,增删快。
线程不安全,效率高。
| - - Set 无序,唯一
| - - HashSet
底层数据结构是哈希表。
如何保证元素唯一性的呢?
依赖两个方法:hashCode()和equals()方法
开发中自动生成这两个方法即可。
| - - LinkedHashSet
底层数据结构是链表和哈希表
由链表保证元素有序
由哈希表保证元素唯一
人的类:重写方法
package com.wyh.linkedHashSet; /**
* @author WYH
* @version 2019年11月17日 上午9:21:02
*/
public class Person {
private String name;
private int age; public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public Person() {
super();
// TODO Auto-generated constructor stub
} public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
} //重写hashCode方法和equals方法
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
} }
测试类:
package com.wyh.linkedHashSet; import java.util.LinkedHashSet; /**
* @author WYH
* @version 2019年11月17日 上午9:40:25
*
* LinkedHashSet: 底层是由哈希表和链表实现的
*
* 哈希表确保元素的唯一性
* 链表确保元素有序(存储和取出一致 )
*/
public class LinkedHashSetDemo1 {
public static void main(String[] args) {
LinkedHashSet<Person> lhs = new LinkedHashSet<Person>();
//创建Person类
Person p1 = new Person("小虎",22);
Person p2 = new Person("小强",23);
Person p3 = new Person("小虎",22);
Person p4 = new Person("小美",21);
Person p5 = new Person("小雪",21); lhs.add(p1);
lhs.add(p2);
lhs.add(p3);
lhs.add(p4);
lhs.add(p5); //
for(Person p : lhs) {
System.out.println(p.getName()+"---"+p.getAge());
} } }
| - - TreeSet
底层数据结构是红黑树。
如何保证元素的排序的呢?
自然排序
比较器排序
如何保证元素唯一性呢?
根据比较的返回值是否是0来决定
3、针对Collection集合我们到底使用谁呢?
唯一吗?
是:Set
排序吗?
是:TreeSet
否:HashSet
如果知道是Set,但是不知道是哪个Set,就用HashSet。
否:List
要安全吗?
是:vector
否:ArrayList 或者 LinkedList
查询多:ArrayList
增删多:LinkedList
如果知道是List,但是不知道是哪个List,就用ArrayList。
如果知道使用Collection集合,但是不知道使用谁,就用ArrayList。
如果知道是用集合,就用ArrayList.
4、在集合中常见的数据结构
ArrayXxx:底层数据结构是数组,查询快,增删慢。
LinkedXxx: 底层数据结构是链表,查询慢,增删快。
HashXxx: 底层数据结构是哈希表,依赖两个方法:hashCode() 和equals()方法
TreeXxx: 底层数据结构是二叉树,两种方式排序,自然排序和比较器排序。
大数据之路week02 Collection 集合体系收尾(Set)的更多相关文章
- 大数据之路week02 List集合的子类
1:List集合的子类(掌握) (1)List的子类特点 ArrayList: 底层数据结构是数组,查询快,增删慢. 线程不安全,效率高. Vector: 底层数据结构是数组,查询快,增删慢. 线程安 ...
- 大数据之路week02--day03 Map集合、Collections工具类的用法
1.Map(掌握) (1)将键映射到值的对象.一个映射不能包含重复的键:每个键最多只能映射到一个值. (2)Map和Collection的区别? A: Map 存储的是键值对形式的元素,键唯一,值可以 ...
- 黑马基础阶段测试题:创建一个存储字符串的集合list,向list中添加以下字符串:”C++”、”Java”、” Python”、”大数据与云计算”。遍历集合,将长度小于5的字符串从集合中删除,删除成功后,打印集合中的所有元素
package com.swift; import java.util.ArrayList; import java.util.List; import java.util.ListIterator; ...
- 大数据之路week01--自学之集合_1(Collection)
经过我个人的调查,发现,在今后的大数据道路上,集合.线程.网络编程变得尤为重要,为什么? 因为大数据大数据,我们必然要对数据进行处理,而这些数据往往是以集合形式存放,掌握对集合的操作非常重要. 在学习 ...
- 大数据之路week01--day02_2 集合方面的总结
(初稿 太晚了,明天再进行补充) 1.对象数组(掌握) (1)数组既可以存储基本数据类型,也可以存储引用类型.它存储引用类型的时候的数组就叫对象数组. (2)案例: 用数组存储5个学生对象,并遍历数组 ...
- 胖子哥的大数据之路(9)-数据仓库金融行业数据逻辑模型FS-LDM
引言: 大数据不是海市蜃楼,万丈高楼平地起只是意淫,大数据发展还要从点滴做起,基于大数据构建国家级.行业级数据中心的项目会越来越多,大数据只是技术,而非解决方案,同样面临数据组织模式,数据逻辑模式的问 ...
- 胖子哥的大数据之路(6)- NoSQL生态圈全景介绍
引言: NoSQL高级培训课程的基础理论篇的部分课件,是从一本英文原著中做的摘选,中文部分参考自互联网.给大家分享. 正文: The NoSQL Ecosystem 目录 The NoSQL Eco ...
- 大数据之路week04--day06(I/O流阶段一 之异常)
从这节开始,进入对I/O流的系统学习,I/O流在往后大数据的学习道路上尤为重要!!!极为重要,必须要提起重视,它与集合,多线程,网络编程,可以说在往后学习或者是工作上,起到一个基石的作用,没了地基,房 ...
- C#码农的大数据之路 - 使用C#编写MR作业
系列目录 写在前面 从Hadoop出现至今,大数据几乎就是Java平台专属一般.虽然Hadoop或Spark也提供了接口可以与其他语言一起使用,但作为基于JVM运行的框架,Java系语言有着天生优势. ...
随机推荐
- IBM.WMQ订阅消息
网上关于IBM这个消息队列中间件的资料相对比较少,C#相关的资料就更少了,最近因为要对接这个队列中间件,花了不少功夫去搜索.整理各种资料,遇到很多问题,因此记录下来. 1.基于 amqmdnet.dl ...
- vue中的$attrs属性和inheritAttrs属性
一.vue中,默认情况下,调用组件时,传入一些没有在props中定义的属性,会把这些“非法”属性渲染在组件的根元素上(有一些属性除外),而这些“非法”的属性会记录在$attrs属性上. 二.如何控制不 ...
- linux环境启动rocketmq服务 报connect to <10.4.86.6:10909> failed异常
解决方式: 需要给Producer和Consumer的DefaultMQPushConsumer对象set这个参数,生产者和消费者都需要,否则不能正常消费消息: 这个问题解决后可能还会出现: conn ...
- LeetCode 15. 三数之和(3Sum)
15. 三数之和 15. 3Sum 题目描述 Given an array nums of n integers, are there elements a, b, c in nums such th ...
- Visual Studio中Debug与Release以及x86、x64、Any CPU的区别
Visual Studio中Debug与Release的区别: 在Visual Studio中,编译模式有2种:Debug与Release.这也是默认的两种方式,在新建一个project的时候,就已经 ...
- Python之数字的四舍五入(round(value, ndigits) 函数)
round(value, ndigits) 函数 print(round(1.23)) # 1 print(round(1.27)) # 1 print(round(1.23,1)) # 1.2 第二 ...
- golang以服务方式运行
golang开发的二进制程序,一般需要长期后台运行的,在linux上可以用supervisor或upstart或systemd等第三方守护进程来实现.其实golang自己也可以实现以服务的形式常驻后台 ...
- YAML 语言格式
1. 认识 YAML YAML(Yet Another Markup Language)语言(发音 /ˈjæməl/ )是一个类似 XML.JSON 的标记性语言.YAML 强调以数据为中心,并不是以 ...
- elasticsearch 集群详解
ES为什么要实现集群 在单台ES服务器节点上,随着业务量的发展索引文件慢慢增多,会影响到效率和内存存储问题等. 如果使用ES集群,会将单台服务器节点的索引文件使用分片技术,分布式的存放在多个不同的物理 ...
- 怎样确保页面中的js代码一定是在DOM结构生成之后再调用
有这样一类问题, 如下所示, 就是在dom结构没有生成时就在js代码中调用了, 此时就会报错: <head> <script> console.log(document.bod ...