数据库中聚合索引(MySQL和SQL Server区别)
一、聚集索引和非聚集索引
聚集索引:类似字典的拼音目录。表中的数据按照聚集索引的规则来存储的。就像新华字典。整本字典是按照A-Z的顺序来排列。这也是一个表只能有一个聚集索引的原因。因为这个特点,具体索引应该建在那些经常需要order by,group by,按范围取值的列上。因为数据本身就是按照聚集索引的顺序存储的。不应该建在需要频繁修改的列上,因为聚集索引的每次改动都以为这表中数据的物理数据的一次重新排序。就想新华字典一样。聚集索引适合建立在大数据量但是小数目不同值的列上,就像新华字典有收录了一两万的汉字,但是其拼音只有A-Z一样。但是并不是不同值越少越好。如果一个列只有极少值,如性别只有男女,在大数据量下无论是聚集索引和非聚集索引都是不适合建立的。因为其不同值辣么少。就像要查性别为男的,那么平均有一半就符合条件。就算建立索引也用处不大。值得注意的是有些数据库如sql server在你创建主键时会默认主键即为聚集索引,如果没有指定主键数据库本身也会创建一个不可见的索引,因为表本身总要有个排序规则是吧。主键作为聚集索引与大数据量但是小数目不同值适合建立聚集索引的规则是相违背的。即使这样也需要这样做的原因刚才说过,表总是需要一个排序规则的。如果你有更加合适的列适合做聚集索引是可以修改聚集索引的,但是聚集索引的修改一定一定一定要谨慎,因为聚集索引涉及要数据的物理存放数据。不合理的聚集索引会十分严重的拖累数据库的性能。注意,虽然一般主键默认就是聚集索引,但是并不代表聚集索引的值具有唯一约束,主键不等于具体索引。这个不要弄混,刚才说过聚集索引适合大数据量但是小数目不同值的列上,聚集索引值是允许重复的,就像新华字典一样,拼音A下面会有很多字。聚集索引流程示意图:
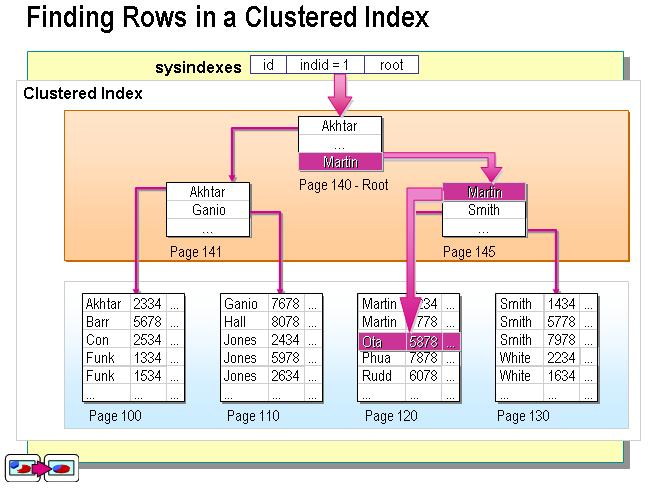
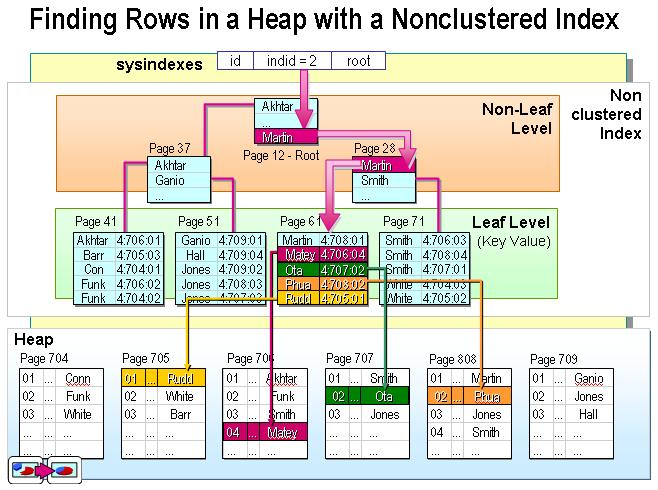
非聚集索引:非聚集索引和表里面数据的物流地址顺序无关。有些像新华字段的偏旁,如单人旁,他下面的两个挨着的字可能页数会有很大的差别。非聚集索引的查询方式和聚集索引的查询方式不一样。聚集索引找到符合条件的目标即获得该目标行的所有数据,因为直接找到是他的物理地址。非聚集索引则不一样,如果你查询的字段是非聚集索引的一部分。那么因为索引本身包含的就有相应数据就可以直接返回,但是如果你查的数据包含非索引数据,比如你用了select *,那么通过非聚集索引找到目标之后,目标体会有一个目标数据聚集索引的key,会通过这个key再通过聚集索引找到完整的目标数据。也就是说使用非聚集索引且要查询的列不包含非聚集索引列本身,那么要经过二次查询。一次查询获得聚集索引的key,二次通过key与聚集索引确定目标数据。有点像新华字段偏旁查询,但是查到字没标页数只标了读音,如果你仅仅查这字怎么写或者读什么,那么直接通过偏旁这个部分的数据即可,但是如果要查更详细的,就要通过拼音去拼音目录里面找,确定页数再去指定页获得具体数据了。当然这只是打个比喻,因为字典里面偏旁查到的字也会表明页数的。非聚集索引适合建立在大数据量下且有大数目不同值,即列中大部分值都互不相同的情况。非聚集索引流程示意图:
针对MySQL5.6版本中的innodb引擎来说,比较规范的数据库表设计(包括我们公司)都会有一条不成文的规定,那就是给每张表一个自增主键。那么自增主键除了有数据的唯一性外,还有什么所用呢?为什么要有自增主键?阅读过《58到家数据库30条军规解读》中解释道:
- 主键递增,数据行写入可以提高插入性能,可以避免page分裂,减少表碎片提升空间和内存的使用。
- 主键要选择较短的数据类型,Innodb引擎普通索引都会保存主键的值,较短的数据类型可以有效的减少索引的磁盘空间,提高索引的缓存效率。
- 无主键的表删除,在row模式的主从架构,会导致备库夯住。
第三条先不必关注,我们来看看前两条。为什么能提高插入性能呢,避免page分页又是怎么回事?这里就不得不说一下聚集索引了。
聚集索引(Clustered Index)一个聚集索引定义了表中数据的物理存储顺序。如何理解聚集索引呢,好比一个电话本,比如一个电话本是按照姓氏排序,并且电话号码紧跟着后面。因为聚集索引决定了表中数据的物理存储顺序,那么一个表则有且只有一个聚集索引。一个聚集索引可以包含多个列。好比一个电话本是基于名字,姓氏同时排序。
Innodb的聚集索引
Innodb的存储索引是基于B+tree,理所当然,聚集索引也是基于B+tree。与非聚集索引的区别则是,聚集索引既存储了索引,也存储了行值。当一个表有一个聚集索引,它的数据是存储在索引的叶子页(leaf pages)。因此innodb也能理解为基于索引的表。Innodb如何决定那个索引作为聚集索引呢?
Innodb如何选择一个聚集索引,对于Innodb,主键毫无疑问是一个聚集索引。但是当一个表没有主键,或者没有一个索引,Innodb会如何处理呢。请看如下规则
1. 如果一个主键被定义了,那么这个主键就是作为聚集索引
2. 如果没有主键被定义,那么该表的第一个唯一非空索引被作为聚集索引
3. 如果没有主键也没有合适的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个6个字节的列,改列的值会随着数据的插入自增。
还有一个需要注意的是:次级索引的叶子节点并不存储行数据的物理地址。而是存储的该行的主键值。
所以:一次级索引包含了两次查找。一次是查找次级索引自身。然后查找主键(聚集索引)现在应该明白了吧,建立自增主键的原因是:Innodb中的每张表都会有一个聚集索引,而聚集索引又是以物理磁盘顺序来存储的,自增主键会把数据自动向后插入,避免了插入过程中的聚集索引排序问题。聚集索引的排序,必然会带来大范围的数据的物理移动,这里面带来的磁盘IO性能损耗是非常大的。
而如果聚集索引上的值可以改动的话,那么也会触发物理磁盘上的移动,于是就可能出现page分裂,表碎片横生。
解读中的第二点相信看了上面关于聚集索引的解释后就很清楚了。
虽然遵循上面的原则也没错,但某些特殊的情况也是可以自己指定一些非自增主键为聚集索引的。如:
当数据量大,但长时间不会被更新的;
新生成的数据的索引本来就是按照自增的顺序增加的等等。首先,必须了解一些基本知识:对于一张表来说,聚集索引只能有一个,因为数据真实的物理存储顺序就是按照聚集索引存储的。基于这个原理,现在可以用这样的方案来测试:对一张表设置一个主键, 之后再建立一个聚集索引,假如聚集索引能创建成功, 表明主键就不是聚集索引, 如果不可以建立聚集索引,就表明主键是聚集索引。

--建立一张TABLE 同时设置主键
CREATE TABLE student
(
stud_id INT IDENTITY(1,1) NOT NULL,
stud_name NVARCHAR(50) NOT NULL,
CONSTRAINT pk_student PRIMARY KEY(stud_id)
);
接下来就尝试对这张表建立一个聚集索引吧。
CREATE CLUSTERED INDEX index_stud_name ON student(stud_name);
执行这条语句的时候,SQLServer的消息框弹出了这样的处理信息:“无法对 表 'student' 创建多个聚集索引。请在创建新聚集索引前删除现有的聚集索引 'pk_student'。"
这就说明主键一定是聚合索引吗?来看看下面的实验。
再看一下关于主键的定义吧,主键是表中的一个字段或多个字段,用来唯一地标识表中的一条记录。唯一性是主键最主要的特性。在查阅建立主键的方法的时候, 一个之前被我完全忽略的创建方式突然出现在我的眼前, 在建立主键的时候可以声明为CLUETERED(聚集)或NONCLUETERED(非聚集)!也就是说主键也可以声明为非聚集索引,如下:
CREATE TABLE student
(
stud_id INT IDENTITY(1,1) NOT NULL,
stud_name NVARCHAR(20) NOT NULL,
CONSTRAINT pk_student PRIMARY KEY NONCLUSTERED (stud_id)
);
在SQLServer中,主键的创建必须依赖于索引,默认创建的是聚集索引,这就解释了在上面的尝试中为什么表中已建立了聚集索引。
所以从上面看出:在SQLServer中主键可以是聚合索引也可以是非聚合索引。
数据库中聚合索引(MySQL和SQL Server区别)的更多相关文章
- 用户、组或角色 '' 在当前数据库中已存在。 (Microsoft SQL Server,错误: 15023)
SQLServer2008用户组或角色'*****'在当前数据库中已存在问题的解决办法 在迁移数据库的过程中SQLServer SDE的问题 为一个数据库添加一个用户时,提示以下信息:用户.组或角色 ...
- 无法将数据库从SINGLE_USER模式切换回MULTI_USER模式(Error 5064),及查找SQL Server数据库中用户spid(非SQL Server系统spid)的方法
今天公司SQL Server数据库无意间变为SINGLE_USER模式了,而且使用如下语句切换回MULTI_USER失败: ALTER DATABASE [MyDB] SET MULTI_USER W ...
- 用户、组或角色 'zgb' 在当前数据库中已存在。 (Microsoft SQL Server,错误: 15023)
在使用SQL Server 时,我们经常会遇到一个情况:需要把一台服务器上的数据库转移到另外一台服务器上.而转移完成后,需要给一个"登录"关联一个"用户"时,往 ...
- (在数据库中调用webservices。)SQL Server 阻止了对组件 'Ole Automation Procedures' 的 过程'sys.sp_OACreate' 的访问
--开启 Ole Automation Procedures sp_configure 'show advanced options', 1; GO RECONFIGURE; GO sp_config ...
- My SQL 和SQL Server区别
MySQL 与SQL Server区别 今天了解了二者区别,整理网上查阅资料,总结列举如下: MSSQL == SQL server 是sybase与微软合作时期的产物. 对于程序开发人员而言,目前使 ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- 小麦苗数据库巡检脚本,支持Oracle、MySQL、SQL Server和PG等数据库
目录 一.巡检脚本简介 二.巡检脚本特点 三.巡检结果展示 1.Oracle数据库 2.MySQL数据库 3.SQL Server数据库 4.PG数据库 5.OS信息 四.脚本运行方式 1.Oracl ...
- [转载]C#中使用ADO.NET连接SQL Server数据库,自动增长字段用作主键,处理事务时的基本方法
问题描述: 假设在数据库中存在以下两张数据表: User表,存放用户的基本信息,基本结构如下所示: 类型 说明 ID_User int 自动增长字段,用作该表的主键 UserName varcha ...
- 分布式SQL数据库中部分索引的好处
在优锐课的java学习分享中,探讨了分布式SQL数据库中部分索引的优势,并探讨了性能测试,结果等. 如果使用局部索引而不是常规索引,则在可为空的列上(其中只有一小部分行的该列不具有空值),然后可以大大 ...
随机推荐
- 小程序开发框架----WXSS
规定了屏幕宽度为750个RPX,从而可以通过屏幕宽度来进行自适应
- mysql数据表的编辑
创建数据表 create table [if not exists] 表名(字段列表, [约束或索引列表]) [表选项列表]; 删除数据表 drop table [if exists] ...
- 洛谷 题解 P1772 【[ZJOI2006]物流运输】
题目描述 物流公司要把一批货物从码头\(A\)运到码头\(B\).由于货物量比较大,需要\(n\)天才能运完.货物运输过程中一般要转停好几个码头.物流公司通常会设计一条固定的运输路线,以便对整个运输过 ...
- 任务调度Quartz.Net之Windows Service
这个应该是关于Quartz.Net使用的最后一篇文章了,之前的介绍都是基于Web的,这种实现任务调度的方式很少见,因为不管是MVC.WebApi还是WebService,它们都需要寄宿在IIS上运行, ...
- [转帖]CentOS 7 安装 GlusterFS
CentOS 7 安装 GlusterFS https://www.cnblogs.com/jicki/p/5801712.html 改天测试一下 我一直没有搞这一块呢. CentOS 7 Glu ...
- STM32之复用功能
复用功能分复用输入,复用输出,STM32芯片内部集成多种模块,如GPIO.串口.i2c等,为使IO端口支持这些模块,厂家对IO端口进行扩展,同一个端口通过设置寄存器会有不同的功能.如下图IO结构图: ...
- CentOS7+Docker+MangoDB下部署简单的MongoDB分片集群
简单的在Docker上快速部署MongoDB分片集群 前言 文中使用的环境如下 OS:CentOS Linux release 7.5.1804 (Core) Docker:Docker versio ...
- 细说浏览器输入URL后发生了什么
本文摘要: 1.DNS域名解析: 2.建立TCP连接: 3.发送HTTP请求: 4.服务器处理请求: 5.返回响应结果: 6.关闭TCP连接: 7.浏览器解析HTML: 8.浏览器布局渲染: 总结 ...
- Springboot模板(thymeleaf、freemarker模板)
目的: 1.thymeleaf模板 2.Freemarker模板 thymeleaf模板 thymeleaf 的优点: 支持html5标准,页面无须部署到servlet开发到服务器上,直接通过浏览器就 ...
- JAVA堆,栈的区别,用AarrayList、LinkedList自定义栈
大家都知道java模拟机在运行时要开辟空间所以它有特定的五个内存划分: 1.寄存器: 2.本地方法区: 3.方法区: 4.栈内存: 5.堆内存: 但是我们今天来注重讲一下栈和堆 ...