[论文理解] An Analysis of Scale Invariance in Object Detection – SNIP
An Analysis of Scale Invariance in Object Detection – SNIP
简介
小目标问题一直是目标检测领域一个比较难解决的问题,因为小目标提供的信息比较少,当前的很多目标检测框架并不能充分捕捉小目标的全部信息,这导致了小目标检测的MAP比较低,在COCO数据集中,小目标所占的尺度也非常的小,尺度差距非常之大(scale variance),SNIP这篇文章很好的缓解了scale variance所带来的问题。
文章主要是围绕几个实验展开的,通过这几个实验,我们能很清楚的走进作者的思路以及如何提出SNIP的想法的。
Image Classification at Multiple Scales
首先作者做的实验是探究分类器在使用不用scale的训练策略,结果如何。这是因为本文后面使用的是Two Stage的网络结构,所以作者这里单独去探究分类网络对不同scale的训练结果的影响,为后面打下铺垫。

首先是第一个实验:
作者将ImageNet的原图分别下采样为48x48、64x64、80x80、96x96、128x128,在训练的时候把图片统一reshape到224x224进行训练。网络结构的第一层为conv7x7和pool2x2。结构是上图中的CNN-B。

结果如上图,横轴是下采样后的尺度,我们发现,尺度越接近于原图尺度,分类的结果是越准确的。
对此的解释是,是浅层的网络使用了2x2pooling,pooling使得信息损失,small scale的图片本来信息就少,还在浅层feature map使用了pooling,使得后面的层无法捕捉到有用信息,所以small scale的图片准确率要低一些。
因此对结构进行修改,改成了上面图中的CNN-S,这里和上面实验的区别是,网络的输入不再是224,对于3x3 stride 1 的结构,输入就是48x48,对于96x96的输入,第一个conv层对应改为conv5x5 stride2,所以测试只针对48x48和96x96的经过下采样的图像进行测试。
结果如图:

我们发现CNN-S比CNN-B有提升,这也证明了上面我们的观点,在相同尺度下训练和测试往往能取得更好的结果,并且左右两个图对比我们也可以得出随着分辨率的提高,这种改进的增益是减小的。
随后作者又做了一组实验,就是上图中的CNN-B-FT。
这组实验是使用CNN-B的结构,首先在224也就是原图高分辨率情况下训练,然后再去使用48x48和96x96 upsample之后的图像再去Fine-tune,结果要更好。
这就说明了,高分辨率的预训练对低分辨率的分类有帮助,也就是说,高分辨率的训练能帮助低分辨率特征的提取。
Data Variation of Correct Scale
这里作者采用了DRFCN网络来实验,这个网络类似SPPNet,能接受不同shape的输入,输出是统一的,所以跟上面的分类网络刚好是相反的。这样可以使得我们可以将不同尺度的图片输入给网络去做下面的实验。
实验中原始图像是640x480的,实际会上采样原始图像,训练的时候要么使用800x1200,要么用1400x2000,而测试的时候是在1400x2000下测试的。


第一组实验:
分别去训练800x1400的图片和1400x2000的图片,他们对应的分别是上图中的Medium Scale和Large Scale,在1400x2000下测试。结果如表中800all和1400all所示。
首先1400的比800的map要高,这符合我们的预期,因为测试图片是1400尺度的,但是为什么提升这么少呢?结论是在Large Scale里,有些Object太大啦,这些太大的Object网络是很难检测的,而小目标在large-scale里被放大了,所以检测难度降低了。
第二组实验:
用1400x2000的图像,在1400x2000上测试,只训练小目标,也就是小于80pixel的目标,结果如表里面第一项,结果要更差了,这说明了其实大目标的训练对小目标的检测是有帮助的,而没了大目标只训练小目标,结果自然就差一些。这其实跟第一组实验有些照应,因为如果没了大目标小目标要训练的更好,说明了第一组实验中大目标最好不训练,我们针对每种尺度去单独训练应该要更好,但实际并不是,多种尺度的object一起训练尽管在800x1400的分辨率下要差于1400x2000,但是比只单独训练小目标要好得多。我觉得这里作者应该再做一组只训练大中目标的实验,证明只训练大中目标的结果也要差于上面的结果,这就说明了确实是大目标太大很难检测。所以这两组对比其实还差一步。
第三组实验:
既然我有800x1400的和1400x2000的图像,有多种分辨率的图像,自然就想到了多种分辨率混合训练,于是作者在第三组实验中使用了多种分辨率混合训练(包含演示分辨率480x800),结果如表中的第四项。可以看到,MAP其实是低于单独训练一种尺度的,这里作者解释为多尺度训练中,large scale中太大的目标难于检测,所以导致了MAP的下降,由于不容易检测,这反而使得MAP要低于800x1400训练的图像。
所以,为了解决第三组实验的问题,本文提出的SNIP就诞生了,思路就是在上面MST上进行改进,使得高分辨率图像只训练小目标,低分辨率图片只训练大目标。
Scale Normalization for Image Pyramids
这里提出SNIP方法,方法的目的就是限制太大或者太小的目标不训练,只训练特定尺度的目标,方法大大减少的在尺度域domain shift,通过上面表格中SNIP的优异表现其实就可以说明。
由于本文是使用DRFCN做的实验,这是一个2-stage网路。大尺度输入图像不仅要和gt看IOU,而且要预定义一个可分配的范围,在这个范围内的GT才会和anchor进行匹配,称为Valid Anchor,否则称为InValid Anchor,InValid Anchor训练时候梯度置0.如图所示。
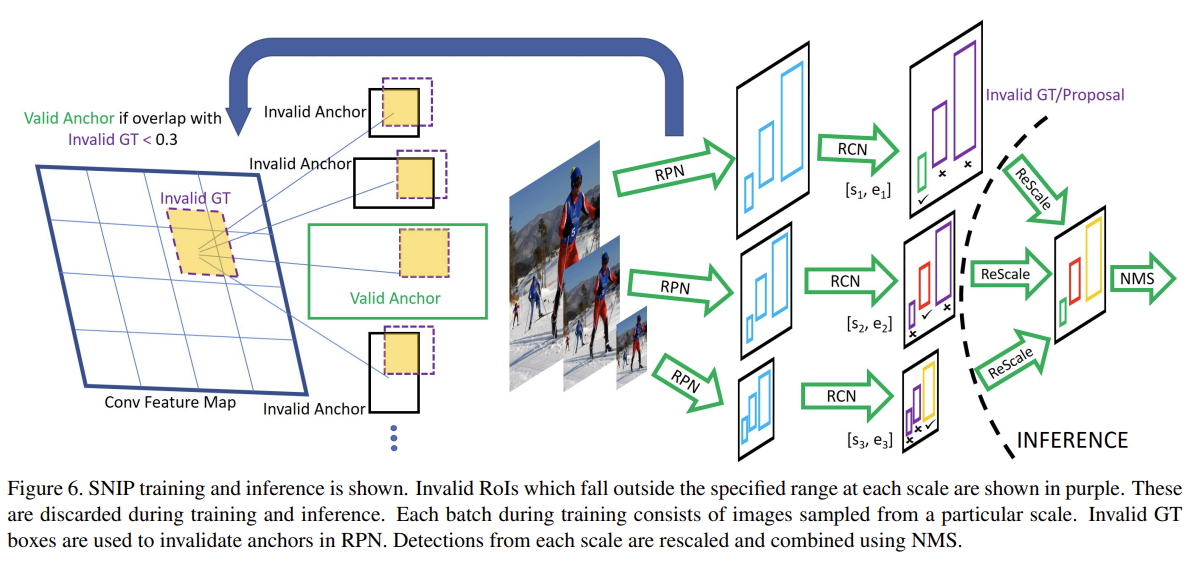
第一阶段训练好之后就可以得到很多尺度的proposal,对于这些proposal拿去训练分类。
[论文理解] An Analysis of Scale Invariance in Object Detection – SNIP的更多相关文章
- 【尺度不变性】An Analysis of Scale Invariance in Object Detection – SNIP 论文解读
前言 本来想按照惯例来一个overview的,结果看到1篇十分不错而且详细的介绍,因此copy过来,自己在前面大体总结一下论文,细节不做赘述,引用文章讲得很详细,另外这篇paper引用十分详细,如果做 ...
- [论文理解] Acquisition of Localization Confidence for Accurate Object Detection
Acquisition of Localization Confidence for Accurate Object Detection Intro 目标检测领域的问题有很多,本文的作者捕捉到了这样一 ...
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
在上计算机视觉这门课的时候,老师曾经留过一个作业:识别一张 A4 纸上的手写数字.按照传统的做法,这种手写体或者验证码识别的项目,都是按照定位+分割+识别的套路.但凡上网搜一下,就能找到一堆识别的教程 ...
- 论文阅读笔记三十五:R-FCN:Object Detection via Region-based Fully Convolutional Networks(CVPR2016)
论文源址:https://arxiv.org/abs/1605.06409 开源代码:https://github.com/PureDiors/pytorch_RFCN 摘要 提出了基于区域的全卷积网 ...
- 【论文解读】【半监督学习】【Google教你水论文】A Simple Semi-Supervised Learning Framework for Object Detection
题记:最近在做LLL(Life Long Learning),接触到了SSL(Semi-Supervised Learning)正好读到了谷歌今年的论文,也是比较有点开创性的,浅显易懂,对比实验丰富, ...
- 论文阅读 | FPN:Feature Pyramid Networks for Object Detection
论文地址:https://arxiv.org/pdf/1612.03144v2.pdf 代码地址:https://github.com/unsky/FPN 概述 FPN是FAIR发表在CVPR 201 ...
- 论文阅读笔记七:Structure Inference Network:Object Detection Using Scene-Level Context and Instance-Level Relationships(CVPR2018)
结构推理网络:基于场景级与实例级目标检测 原文链接:https://arxiv.org/abs/1807.00119 代码链接:https://github.com/choasup/SIN Yong ...
- 目标检测论文解读1——Rich feature hierarchies for accurate object detection and semantic segmentation
背景 在2012 Imagenet LSVRC比赛中,Alexnet以15.3%的top-5 错误率轻松拔得头筹(第二名top-5错误率为26.2%).由此,ConvNet的潜力受到广泛认可,一炮而红 ...
- 深度学习论文翻译解析(八):Rich feature hierarchies for accurate object detection and semantic segmentation
论文标题:Rich feature hierarchies for accurate object detection and semantic segmentation 标题翻译:丰富的特征层次结构 ...
随机推荐
- 巧用Map缓存提升"翻译"速度
在业务编码中,很多情况都需要用到code2Name或者id2Name之间的"翻译",在我的过往经历中发现不少开发人员都是直接双重循环实现这种"翻译".如果一次& ...
- centos 7 源代码搭建部署 zabbix-4.0.13 LTS
Zabbix 官网 >:https://www.zabbix.com/download 源代码地址>:https://www.zabbix.com/cn/download_sources# ...
- -bash: ls: No such file or directory 错误的原因及解决办法
ubuntu出现如下错误: { Welcome to Ubuntu 16.04.5 LTS (GNU/Linux 4.15.0-42-generic x86_64) * Documentation: ...
- Python爬虫解析htm时lxml的HtmlElement对象获取和设置inner html方法
Python的lxml是一个相当强悍的解析html.XML的模块,最新版本支持的python版本从2.6到3.6,是写爬虫的必备利器.它基于C语言库libxml2 和 libxslt,进行了Pytho ...
- ubuntu下mysql的用户添加、授权、取消授权
一.添加用户 新增用户会有两种方式的,一种是使用create命令,另一种是直接回使用grant 命令 create user 名字@登陆地址 identified by "密码"; ...
- C# class 浅拷贝 与 深拷贝
MemberwiseClone 方法创建一个浅表副本,具体来说就是创建一个新对象,然后将当前对象的非静态字段复制到该新对象.如果字段是值类型的,则对该字段执行逐位复制.如果字段是引用类型,则复制引用但 ...
- BZOJ1821 部落划分[最小生成树]
方法一:套路性的,二分距离,然后把距离点对距离小于答案的边都联通起来,然后看集合数量超过k说明答案小,增大,否则减小. 方法二:贪心,类kruskal.n个点,k个连通块,则需要有效连接(同一个块内的 ...
- springboot整合mongodb问题1-Decimal128和BigDecimal的转换之mongodb转换器使用(转)
转自:https://blog.csdn.net/weixin_41792559/article/details/79575524 1.Decimal128的了解由于mongodb4.3以上新加了De ...
- Spark配置详解
Spark提供三个位置用来配置系统: Spark属性:控制大部分的应用程序参数,可以用SparkConf对象或者Java系统属性设置 环境变量:可以通过每个节点的 conf/spark-env.sh脚 ...
- lnmp环境搭建(Ubuntu)
dpkg -l | grep gcc ubuntu系统查看已安装的包 dpkg -S nginx 查看安装的nginx apt-get update 首先更新 ...