MongoDB存储引擎、索引 原
wiredTiger
MongoDB从3.0开始引入可插拔存储引擎的概念。目前主要有MMAPV1、WiredTiger存储引擎可供选择。在3.2版本之前MMAPV1是默认的存储引擎,其采用linux操作系统内存映射技术,但一直饱受诟病;3.4以上版本默认的存储引擎是wiredTiger,相对于MMAPV1其有如下优势:
读写操作性能更好,WiredTiger能更好的发挥多核系统的处理能力;
MMAPV1引擎使用表级锁,当某个单表上有并发的操作,吞吐将受到限制。WiredTiger使用文档级锁,由此带来并发及吞吐的提高
相比MMAPV1存储索引时WiredTiger使用前缀压缩,更节省对内存空间的损耗;
提供压缩算法,可以大大降低对硬盘资源的消耗,节省约60%以上的硬盘资源;
mongodb数据会丢失?你需要了解WT写入的原理
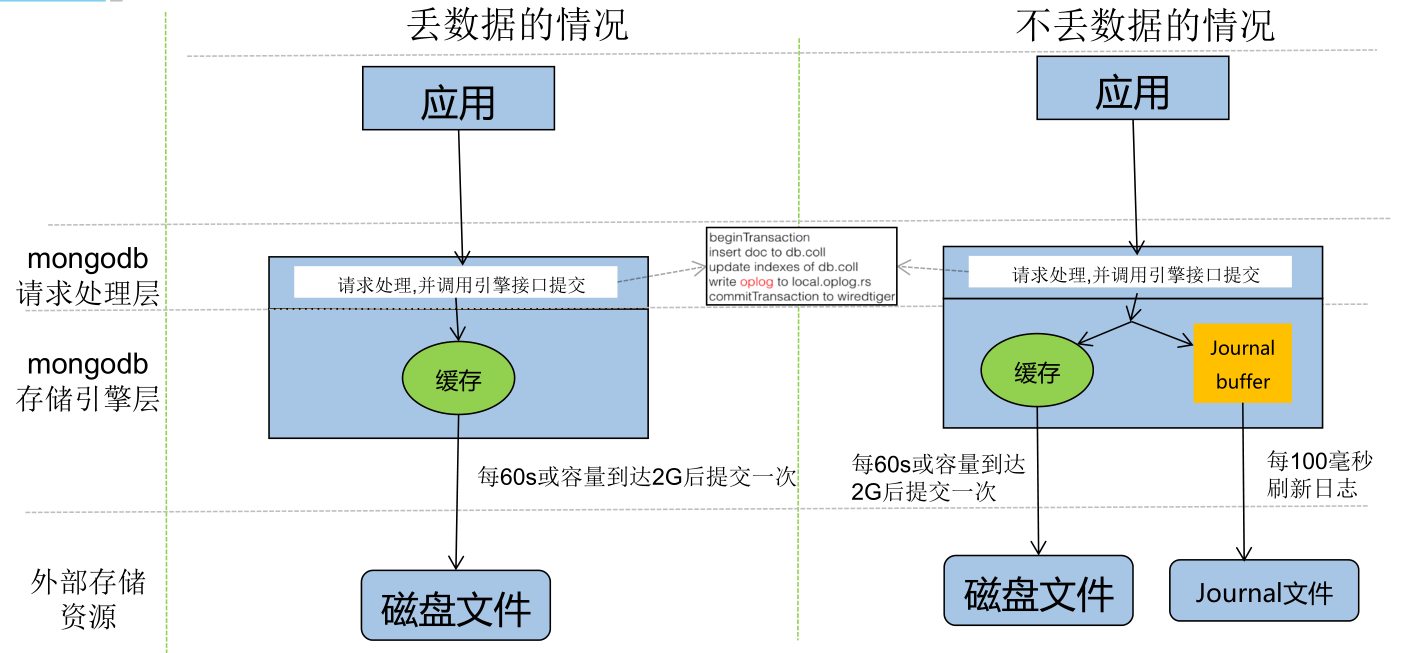
Journaling类似于关系数据库中的事务日志。Journaling能够使MongoDB数据库由于意外故障后快速恢复。MongoDB2.4版本后默认开启了Journaling日志功能,mongod实例每次启动时都会检查journal日志文件看是否需要恢复。由于提交journal日志会产生写入阻塞,所以它对写入的操作有性能影响,但对于读没有影响。在生产环境中开启Journaling是很有必要的。
写策略解析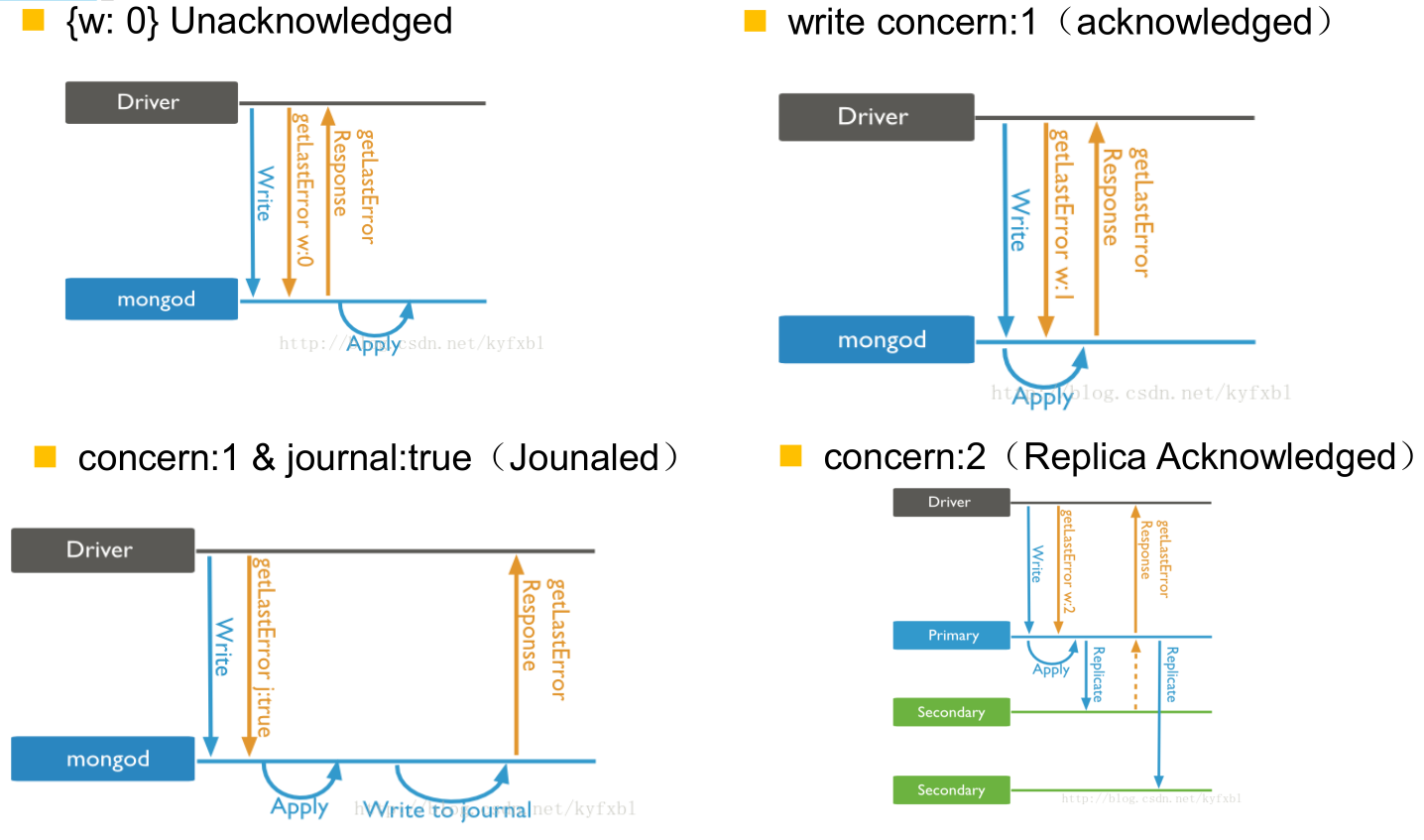
配置文件
storage:
journal:
enabled: true
dbPath: /data/zhou/mongo1/
##是否一个库一个文件夹
directoryPerDB: true
##数据引擎
engine: wiredTiger
##WT引擎配置
WiredTiger:
engineConfig:
##WT最大使用cache(根据服务器实际情况调节)
cacheSizeGB: 1
##是否将索引也按数据库名单独存储
directoryForIndexes: true
journalCompressor:none (默认snappy)
##表压缩配置
collectionConfig:
blockCompressor: zlib (默认snappy,还可选none、zlib)
##索引配置
indexConfig:
prefixCompression: true压缩 算法 Tips:
性能: none > snappy >zlib
压缩比:zlib > snappy > none
索引命令概要与类型
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。索引主要用于排序和检索
单键索引
在某一个特定的属性上建立索引,例如:db.users. createIndex({age:-1});
mongoDB在ID上建立了唯一的单键索引,所以经常会使用id来进行查询;
在索引字段上进行精确匹配、排序以及范围查找都会使用此索引;
复合索引
在多个特定的属性上建立索引,例如:db.users. createIndex({username:1,age:-1,country:1});
复合索引键的排序顺序,可以确定该索引是否可以支持排序操作;
在索引字段上进行精确匹配、排序以及范围查找都会使用此索引,但与索引的顺序有关;
为了性能考虑,应删除存在与第一个键相同的单键索引
多键索引
在数组的属性上建立索引,例如:db.users. createIndex({favorites.city:1});针对这个数组的任意值
的查询都会定位到这个文档,既多个索引入口或者键值引用同一个文档
哈希索引
不同于传统的B-树索引,哈希索引使用hash函数来创建索引。
例如:db.users. createIndex({username : 'hashed'});
在索引字段上进行精确匹配,但不支持范围查询,不支持多键hash;
Hash索引上的入口是均匀分布的,在分片集合中非常有用;
索引语法
MongoDB使用 ensureIndex() 方法来创建索引,ensureIndex()方法基本语法格式如下所示:
db.collection.createIndex(keys, options)
语法中 Key 值为要创建的索引字段,1为指定按升序创建索引,如果你想按降序来创建索引指定为-1,也可以指定为hashed(哈希索引)。
语法中options为索引的属性,属性说明见下表;

创建索引
单键唯一索引:db.users. createIndex({username :1},{unique:true});
单键唯一稀疏索引:db.users. createIndex({username :1},{unique:true,sparse:true});
复合唯一稀疏索引:db.users. createIndex({username:1,age:-1},{unique:true,sparse:true});
创建哈希索引并后台运行:db.users. createIndex({username :'hashed'},{background:true});
删除索引
根据索引名字删除某一个指定索引:db.users.dropIndex("username_1");
删除某集合上所有索引:db.users.dropIndexs();
重建某集合上所有索引:db.users.reIndex();
查询集合上所有索引:db.users.getIndexes();
查询优化技巧 第一步
找出慢速查询
开启内置的查询分析器,记录读写操作效率:
db.setProfilingLevel(n,{m}),n的取值可选0,1,2;
0是默认值表示不记录;
1表示记录慢速操作,如果值为1,m必须赋值单位为ms,用于定义慢速查询时间的阈值;
2表示记录所有的读写操作;
例如:db.setProfilingLevel(1,300)
查询监控结果
监控结果保存在一个特殊的盖子集合system.profile里,这个集合分配了128kb的空间,要确保监控分析数据不会消耗太多的系统性资源;盖子集合维护了自然的插入顺序,可以使用$natural操作符进行排序,如:db.system.profile.find().sort({'$natural':-1}).limit(5)

查询优化技巧 第二步
分析慢速查询
找出慢速查询的原因比较棘手,原因可能有多个:应用程序设计不合理、不正确的数据模型、硬件配置问题,缺少索引等;接下来对于缺少索引的情况进行分析:
使用explain分析慢速查询
例如:db.orders.find({'price':{'$lt':2000}}).explain('executionStats')
explain的入参可选值为:
"queryPlanner" 是默认值,表示仅仅展示执行计划信息;
"executionStats" 表示展示执行计划信息同时展示被选中的执行计划的执行情况信息;
"allPlansExecution" 表示展示执行计划信息,并展示被选中的执行计划的执行情况信息,还展示备选的执行计划的执行情况信息;
查询优化技巧 第三步
解读explain结果
queryPlanner(执行计划描述)
winningPlan(被选中的执行计划)
stage(可选项:COLLSCAN 没有走索引;IXSCAN使用了索引)
rejectedPlans(候选的执行计划)
executionStats(执行情况描述)
nReturned (返回的文档个数)
executionTimeMillis(执行时间ms)
totalKeysExamined (检查的索引键值个数)
totalDocsExamined (检查的文档个数)
优化目标 Tips:
1. 根据需求建立索引
2. 每个查询都要使用索引以提高查询效率, winningPlan. stage 必须为IXSCAN ;
3. 追求totalDocsExamined = nReturned
关于索引的建议
1. 索引很有用,但是它也是有成本的——它占内存,让写入变慢;
2. mongoDB通常在一次查询里使用一个索引,所以多个字段的查询或者排序需要复合索引才能更加高效;
3. 复合索引的顺序非常重要
4. 在生成环境构建索引往往开销很大,时间也不可以接受,在数据量庞大之前尽量进行查询优化和构建索引;
5. 避免昂贵的查询,使用查询分析器记录那些开销很大的查询便于问题排查;
6. 通过减少扫描文档数量来优化查询,使用explai对开销大的查询进行分析并优化;
7. 索引是用来查询小范围数据的,不适合使用索引的情况:
每次查询都需要返回大部分数据的文档,避免使用索引
写比读多
MongoDB存储引擎、索引 原的更多相关文章
- MongoDB学习笔记(五、MongoDB存储引擎与索引)
目录: mongoDB存储引擎 mongoDB索引 索引的属性 MongoDB查询优化 mongoDB存储引擎: 目前mongoDB的存储引擎分为三种: 1.WiredTiger存储引擎: a.Con ...
- MongoDB存储引擎选择
MongoDB存储引擎选择 MongoDB存储引擎构架 插件式存储引擎, MongoDB 3.0引入了插件式存储引擎API,为第三方的存储引擎厂商加入MongoDB提供了方便,这一变化无疑参考了MyS ...
- MongoDB 存储引擎选择
MongoDB存储引擎选择 MongoDB存储引擎构架 插件式存储引擎, MongoDB 3.0引入了插件式存储引擎API,为第三方的存储引擎厂商加入MongoDB提供了方便,这一变化无疑参考了MyS ...
- 为什么选择b+树作为存储引擎索引结构
为什么选择b+树作为存储引擎索引结构 在数据库或者存储的世界里,存储引擎的角色一直处于核心位置.往简单了说,存储引擎主要负责数据如何读写.往复杂了说,怎么快速.高效的完成数据的读写,一直是存储引擎要解 ...
- MongoDB 存储引擎和数据模型设计
标签: MongoDB NoSQL MongoDB 存储引擎和数据模型设计 1. 存储引擎 1.1 存储引擎是什么 1.2 MongoDB中的默认存储引擎 2. 数据模型设计 2.1 内嵌和引用 2. ...
- MongoDB存储引擎(上)——MMAPv1
3.0版本以前,MongoDB只有一个存储引擎——MMAP,MongoDB3.0引进了一个新的存储引擎——WiredTiger,同时对原有的MMAP引擎进行改进,产生MMAPv1存储引擎,并将其设置为 ...
- MongoDB 存储引擎:WiredTiger和In-Memory
存储引擎(Storage Engine)是MongoDB的核心组件,负责管理数据如何存储在硬盘(Disk)和内存(Memory)上.从MongoDB 3.2 版本开始,MongoDB 支持多数据存储引 ...
- MongoDB 存储引擎Wiredtiger原理剖析
今天开始看MongoDB 3.2的文档,发现了这么两句话 Support for Multiple Storage Engines MongoDB supports multiple storage ...
- MongoDB存储引擎(下)——In-Memory
前两篇文章分别介绍了MMAPv1和WiredTiger,这两个存储引擎都是会将数据持久化存储到硬盘的,除此之外,MongoDB也有只将数据存储在内存的存储引擎,那就是In-Memory. In-Mem ...
随机推荐
- python — 线程
目录 1.线程基础知识 2 Thread 类 3 锁 4 队列 1.线程基础知识 1.1 进程与线程的区别 进程: 创建进程 时间开销大 销毁进程 时间开销大 进程之间切换 时间开销大 线程: 线程是 ...
- Scala 面向对象编程之对象
此对象非彼java bean对象 是scala object的对象 Object // object,相当于class的单个实例,通常在里面放一些静态的field或者method // 第一次调用ob ...
- sass快速使用
sass的使用 建议使用一种语法格式(scss) scss sass转换 sass-convert main.scss main.sass sass变量声明 example: $headline-ff ...
- 【Linux】Shell批量修改文件名
修改文件名,替换中间字符: 例如:ABC_define_EFG.jpg,要把中间的define替换成argument: 用如下脚本即可: for var in *; do mv "$var& ...
- v8 引擎的内存
一.nodejs查看内容使用情况: process.memoryUsage() 单位为 Btye 转化函数: var format = function(bytes) { return (bytes/ ...
- Thymeleaf模板引擎与springboot关联后,在html中无法使用el表达式获取model存的值
头部引入了thymeleaf <html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thy ...
- 定时任务cron表达式详解
参考自:https://blog.csdn.net/fanrenxiang/article/details/80361582 一 cron表达式 顺序 秒 分 时 日期 月份 星期 年(可选) 取值 ...
- vue的jsonp百度下拉菜单
通过vue的jsonp实现百度下拉菜单的请求,vue的版本是2.9.2 <!DOCTYPE html> <html lang="en"> <head& ...
- ES6中 对字符串增强
在曾经,我们只能用A.indexof(B)来判断A中是否含有B字符串: 现在在ES6中 有了: includes(), startswith(),endswith() reapt()重复次数: 输出 ...
- Android NDK 学习之接受Java传入的字符串
本博客主要是在Ubuntu 下开发,且默认你已经安装了Eclipse,Android SDK, Android NDK, CDT插件. 在Eclipse中添加配置NDK,路径如下Eclipse-> ...