SIGAI机器学习第五集 贝叶斯分类器
讲授贝叶斯公式、朴素贝叶斯分类器、正态贝叶斯分类器的原理、实现以及实际应用
大纲:
贝叶斯公式(直接用贝叶斯公式完成分类,计算一个样本的特征向量X属于每个类c的概率,这个计算是通过贝叶斯公式来完成的。)
朴素贝叶斯分类器(预测算法、训练算法)
正态贝叶斯分类器(预测算法、训练算法)
实验环节
实际应用
贝叶斯公式:
澄明了两个相关的(有因果关系的)随机事件以及随机变量之间的概率关系的。
随机事件a、b,假设b是因a是果: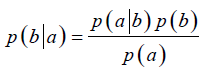
推广到随机变量的情况: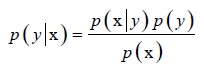
①根据这个公式就可以完成分类了,给定任意一个样本的特征向量X,就可以计算它属于每个类的概率值。
离散的变量p(x)也可推广到连续的情况概率密度函数f(x),p(x)或f(x)对于每个类yi的概率是相等的一样的,样本属于某个类的概率正比于分子,仅仅以分类为目的而非精确计算样本属于某个类的概率的话,只需计算分子,舍弃分母。
②每个类的条件概率(对连续型随机变量是条件密度函数),统计每个类y它的随机变量x的概率分布就可以了,可以用最大似然估计或其他算法(根据训练样本,把训练样本归类在一起,统计出某个样本的p(x|y)),判定为分子最大的类,即最大化后验概率p(y|x)。
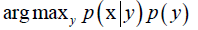
一般情况下,我们是知道每个类y它的样本x所服从的概率分布的p(x|y)(概率密度函数或概率分布表),这称为先验概率,而分类器要做的是反推另一个概率,已知x算它属于某个类的概率,即p(y|x),刚好和先验概率相反,要得到后验概率的概率。
朴素贝叶斯分类器:简称NB,naive bayes
核心问题是计算p(x|y)*p(y),p(y)可以简单的设置为每个类出现的概率相等,也可以根据训练样本每个类出现的概率来统计出概率值来。然后核心的问题就是计算所有样本x在每个类下的条件概率p(x|y)(对于连续型变量是条件密度函数,离散型随机变量是条件概率),p(x|y)怎么计算呢?肯定要假设x服从某种概率分布,关键是怎么根据样本估计概率分布(或概率密度函数)中的参数,例如x如果服从正态分布就要估计它的均值和方差(多维是协方差)。有个习惯,现实世界中很多样本就假设它服从正态分布,如人的身高、体重、考试分数等近似服从正态分布,而且中心极限定理也保证了很多随机变量它的极限分布就是一个正态分布。
这里有两种假设:
①第一种就是朴素贝叶斯分类器:假设特征向量x,它的每一个分量相互独立。
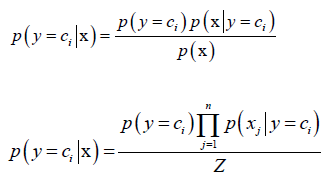
Z是p(x),归一化因子,对每个类都相等。分子最大化,所属的类ci就是分类的结果。
对于离散型特征:
样本x的分量xi是有限种取值
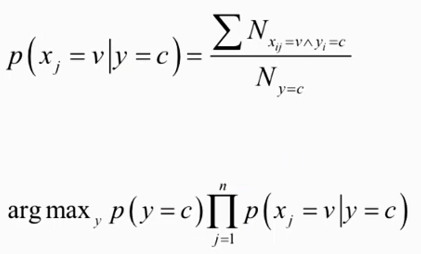
可能所有的样本的某个分量xi都不取某个类c,那么此时p(xj|y=c)的分母就取值为0了,这时对分母都加k(一共k类),分子加1平滑一下,保证概率值加起来等于1。
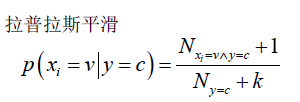
对于连续型特征:
假设x服从一维正态分布。
最大似然固然估计,用样本均值、样本方差来估计正态分布的均值和方差,是有偏估计。
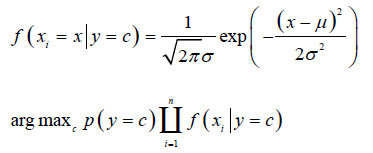
对每个类都要估计,都要算它的均值和方差。
朴素贝叶斯的精髓就是特征向量所有分量之间相互独立,这样就极大地简化问题的求解难度,因为要算一个高维的概率分布是非常麻烦的,但是能把他转化为n个一维的话,情况会简单很多。
正态贝叶斯分类器:简称也是NB,normal bayes
多维
假设样本的特征向量x,对于每个类来说,它的样本特征向量x,服从多维正态分布:
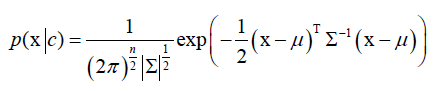 ,指数里是一个二次型,∑是协方差矩阵,∑-1是它的逆矩阵,|∑|是∑的行列式,和一维正态分布形式上是统一的。
,指数里是一个二次型,∑是协方差矩阵,∑-1是它的逆矩阵,|∑|是∑的行列式,和一维正态分布形式上是统一的。
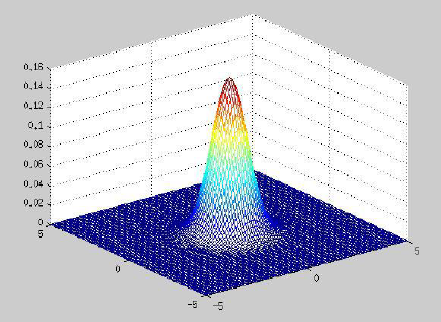
三维以上看不到,均值的地方概率值最大,协方差矩阵决定帽子的宽度、朝向(扁的或圆的)。
假设有一批样本,把样本分成多个类,每个类有一批样本,根据这一批样本用最大似然估计把每个类的均值向量μ和协方差矩阵∑给估计出来,估计出来之后带入贝叶斯判定公式中判定一下就OK了。
训练的时候主要是求解均值向量μ和协方差矩阵∑,在求出μ和∑后,预测的时候稍微麻烦一点:
根据估算出来的协方差矩阵∑求它的逆矩阵∑-1,从而求出p(x|c)。
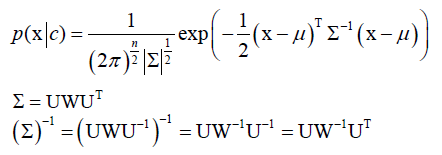
协方差矩阵∑是一个n阶对称方阵,这里求逆矩阵,借助了奇异值分解SVD,对于实对称阵来说,它的奇异值分解就退化为特征值分解了。
对角阵W,正交阵U(UT=U-1)。
|∑|=|U||W||UT|=|W|=∏wii(wii为W对角线元素,因为U是正交阵|U||UT|=1)。
然后将p(x|c)带到贝叶斯分类中,这里假设p(c)是一样的:
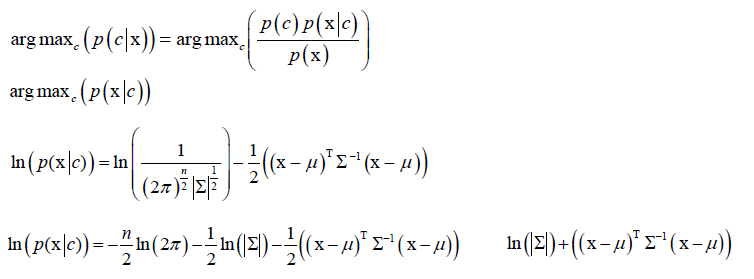
训练的时候每个类都要最大似人估计计算均值向量μ和协方差矩阵∑,在预测的时候只需算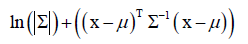 ,求它的极小值对应的类即是结果。
,求它的极小值对应的类即是结果。
实验环节:
贝叶斯分类器是非线性模型,可以解决异或分类问题。
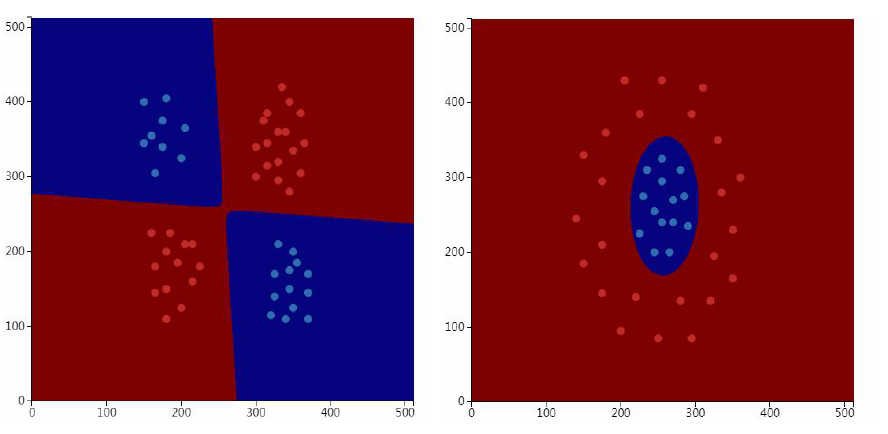
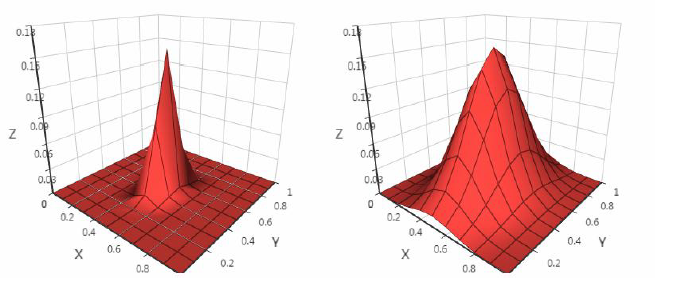
每个类的分布的函数图像的形状不同:
实际应用:
有病没病
垃圾邮件分类问题:根据邮件里边的关键词,来用贝叶斯公式分类,一般用的是朴素贝叶斯,给定指定长度的特征向量,带入到贝叶斯公式中计算。
Mehran Sahami, Susan T Dumais, David Heckerman, Eric Horvitz. A Bayesian Approach to Filtering Junk E-Mail.1998.
文本分类问题:对于文本我们会提一个特征向量出来,一般用tf-idf,它考虑了词频和文档频率的分布。特征向量维度通常非常高,如果要拟合一个高维分布是非常麻烦的,这时可以用朴素贝叶斯。
Yiming Yang, Xin Liu. A re-examination of text categorization methods.international acm sigir conference on research and development in information retrieval, 1999.
智能视频监控中的背景建模算法:摄像机固定不动的时候,人或车在其中走来走去,我们要把这些动的目标抠出来。
Liyuan Li, Weimin Huang, Irene Y H Gu, Qi Tian. Foreground object detection from videos containing complex background. acm multimedia, 2003.

摄像机固定不动,假如1秒学习到40帧图像,学习到背景图像,再来一帧当前最新的图像,来判断每个像素点是前景还是背景,就是二分类问题。选用的特征向量是一点的RGB亮度值和前一帧的差值,把这样一个特征向量带入到贝叶斯公式里去算,算属于前景还是背景的概率,如果前景概率大判断为前景否则为背景,前两个公式带入到第三个全概率公式(每个样本不是属于前景就是属于背景),满足第四个公式则为背景,否则就是前景。关键是怎么得到贝叶斯分类器中的概率分布,通过前面图像的像素点样本的学习得到的。贝叶斯分类器核心是构造特征向量x,训练估计概率分布,预测带入到公式中计算最大值。
人脸识别中的联合贝叶斯模型:把两张照片判定为是否是同一个人,根据姿态、光照因素利用贝叶斯建模。
Dong Chen, Xudong Cao, Liwei Wang, Fang Wen, Jian Sun. Bayesian face revisited: a joint formulation. european conference on computer vision, 2012.
总结:
贝叶斯分类器核心是①构造特征向量x,②训练估计概率分布,③预测带入到公式中计算最大值。
SIGAI机器学习第五集 贝叶斯分类器的更多相关文章
- 【原创】.NET平台机器学习组件-Infer.NET连载(二)贝叶斯分类器
本博客所有文章分类的总目录:http://www.cnblogs.com/asxinyu/p/4288836.html 微软Infer.NET机器学习组件文章目录:http:/ ...
- 吴裕雄 python 机器学习——高斯贝叶斯分类器GaussianNB
import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes from sklearn.model_selectio ...
- 吴裕雄 python 机器学习——多项式贝叶斯分类器MultinomialNB模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes from skl ...
- SIGAI机器学习第四集 基本概念
大纲: 算法分类有监督学习与无监督学习分类问题与回归问题生成模型与判别模型强化学习评价指标准确率与回归误差ROC曲线交叉验证模型选择过拟合与欠拟合偏差与方差正则化 半监督学习归类到有监督学习中去. 有 ...
- SIGAI机器学习第十七集 线性模型1
讲授logistic回归的基本思想,预测算法,训练算法,softmax回归,线性支持向量机,实际应用 大纲: 再论线性模型logistic回归的基本思想预测函数训练目标函数梯度下降法求解另一种版本的对 ...
- Naive Bayes Classifier 朴素贝叶斯分类器
贝叶斯分类器的分类 根据实际处理的数据类型, 可以分为离散型贝叶斯分类器和连续型贝叶斯分类器, 这两种类型的分类器, 使用的计算方式是不一样的. 贝叶斯公式 首先看一下贝叶斯公式 $ P\left ( ...
- Python机器学习笔记:朴素贝叶斯算法
朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法.对于大多数的分类算法,在所有的机器学习分类算法中,朴素贝叶斯和其他绝大多数的分类算法都不同.比如决策树,KNN,逻辑回归,支持向 ...
- machine learning for hacker记录(3) 贝叶斯分类器
本章主要介绍了分类算法里面的一种最基本的分类器:朴素贝叶斯算法(NB),算法性能正如英文缩写的一样,很NB,尤其在垃圾邮件检测领域,关于贝叶斯的网上资料也很多,这里推荐那篇刘未鹏写的http://mi ...
- Python实现机器学习算法:朴素贝叶斯算法
''' 数据集:Mnist 训练集数量:60000 测试集数量:10000 ''' import numpy as np import time def loadData(fileName): ''' ...
随机推荐
- Java中的静态导入
Java从1.5开始,增加了静态导入的语法,静态导入使用import static语句,分为两种: 导入指定类的某个静态成员变量.方法. 导入指定类的全部的静态成员变量.方法. 下面是代码演示: /* ...
- Erlang:[笔记二,构建工具rebar之发布应用]
概述 通过rebar可以发布rebar构建的erlang项目,生成可执行的二进制脚本文件,大大降低了执行应用的复杂度.该笔记Erlang环境为Erlang/OTP 19 ,以下适用于Eralng/OT ...
- 3种PHP实现数据采集的方法
https://www.php.cn/php-weizijiaocheng-387992.html
- pandas数据结构之基础运算笔记
import pandas as pd import numpy as np s = pd.Series([1,3,5,6,8],index=list('acefh')) s.index # 读取行索 ...
- Centos 安装 graylog
安装文档 安装nginx做反向代理 (如果生产环境通过端口管理则用不到) 通过yum安装方便以后升级 yum install nginx chkconfig nginx on service ngin ...
- ORA-16401: archivelog rejected by RFS
ORA-16401: archivelog rejected by RFS 无线出单系统邮件告警10.111.20.1 1. 报错 SYS > ! oerr ora 16041 1604 ...
- R语言错误的提示(中英文翻译)
# Chinese translations for R package # Copyright (C) 2005 The R Foundation # This file is distribute ...
- IE6/7下Select控件Display属性无效解决办法
HTML的Select控件,C#的DropDownList服务器控件 设置父类型Display属性之后,在IE6/7上无效 直接将下段javascript脚本添加到页面中即可 <script t ...
- Flutter-现有iOS工程引入Flutter
前言 Flutter 是一个很有潜力的框架,但是目前使用Flutter的APP并不算很多,相关资料并不丰富,介绍现有工程引入Flutter的相关文章也比较少.项目从零开始,引入Flutter操作比较简 ...
- 抓包分析工具web版——capanalysis
1.下载安装 官网上,安装在Ubuntu上 2.使用教程 https://blog.51cto.com/chenguang/1325742