强化学习复习笔记 - DEEP
Outline
使用逼近器的特点:
较少数量的参数表达复杂的函数 (计算复杂度)
对一个权重的调整可以影响到很多的点 (泛化能力)
多种特征表示和逼近器结构 (多样性)
激活函数
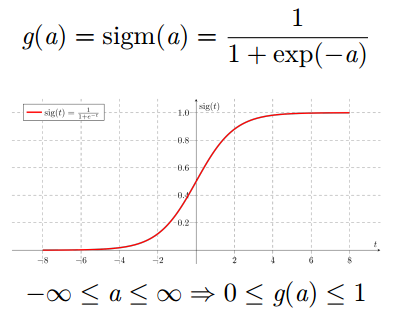
Sigmoid 激活函数
将神经元的输出压缩在 0 和 1 之间
永远都是正数
有界
严格递增
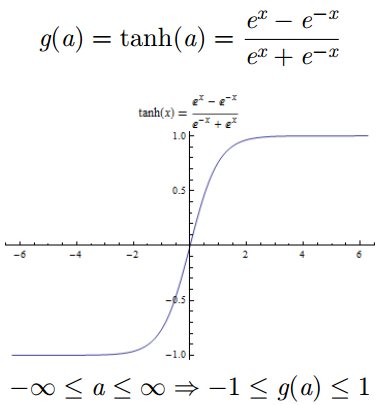
tanh 双曲正切函数
将神经元的输出压缩在
-1 和 1 之间
有正有负
有界
严格递增
线性整流 (Rectified Linear Unit, ReLU) 激活函数
以 0 作为下界 (永远都是非负的)
容易让神经元产生稀疏的激活行为
无上界
严格递增
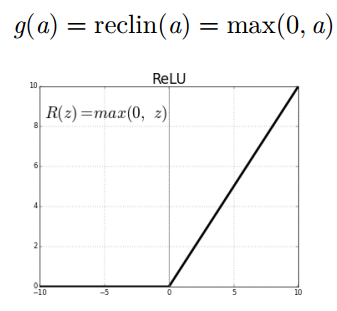
通用近似定理 (Hornik, 1991)
“如果一个前馈神经网络具有线性输出层和至少一层隐藏层, 只要给予网络足够数量的神经元,便可以实现以足够高精度来逼近任意一个在 Rn 的紧子集 (Compact subset) 上的连续函数。 ”
定理适用于 sigmoid, tanh, 和其它激活函数
但是定理并不代表一定存在某个学习算法, 能够找到具有满足近似性能的参数
置信风险: 分类器对 未知样本进行分类,得到的误差。
经验风险: 训练好的分类器,对训练样本重新分类得到的误差。即样本误差
结构风险:置信风险 + 经验风险
小批量 Mini-batch 梯度下降
更新是基于一组小批量的样本 {(x(i:i+b); y(i:i+b))}(不再是单 一样本)
梯度对应于正则化损失在小批量样本上的平均
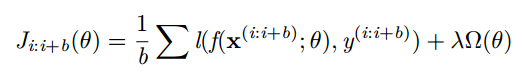
可以得到对梯度更加精确的估计
可以使用矩阵运算, 计算效率更高

在训练集 Dtrain上训练你的模型
在验证集 Dvalid上选择模型
-----包括选择超参; 隐含层尺寸; 学习率; 迭代/训练次数; 等等
在测试集 Dtext上评估泛化能力
泛化的含义是模型在未见过的样本上的表现
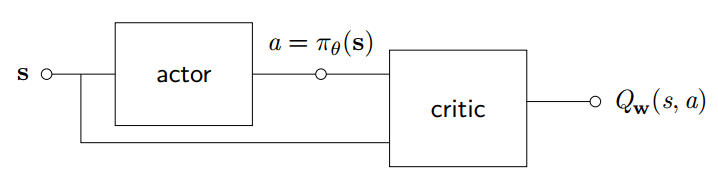
确定性 Actor-Critic
对于确定性策略, 可以使用神经网络逼近器构建 actor, 直接输出策略确定性的动作

设计另一个神经网络构造 Critic 用于逼近 Q 函数
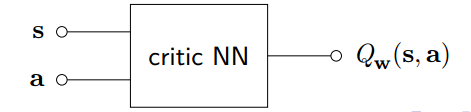
对 Critic NN 可以使用例如 TD 学习算法训练网络权重
对 Actor NN 希望能够输出最优动作使得 Q 函数最大化
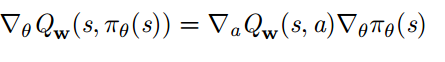

强化学习复习笔记 - DEEP的更多相关文章
- 强化学习读书笔记 - 02 - 多臂老O虎O机问题
# 强化学习读书笔记 - 02 - 多臂老O虎O机问题 学习笔记: [Reinforcement Learning: An Introduction, Richard S. Sutton and An ...
- 强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods)
强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods) 学习笔记: Reinforcement Learning: An Introduction, Richard S ...
- 强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning)
强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning) 学习笔记: Reinforcement Learning: An Introductio ...
- 强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods)
强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods) 学习笔记: Reinforcement Learning: An Introduction, Richa ...
- 强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces)
强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces) 学习笔记: Reinforcement Learning: An Introduction, Richard S. S ...
- 强化学习读书笔记 - 11 - off-policy的近似方法
强化学习读书笔记 - 11 - off-policy的近似方法 学习笔记: Reinforcement Learning: An Introduction, Richard S. Sutton and ...
- 强化学习读书笔记 - 10 - on-policy控制的近似方法
强化学习读书笔记 - 10 - on-policy控制的近似方法 学习笔记: Reinforcement Learning: An Introduction, Richard S. Sutton an ...
- 强化学习读书笔记 - 09 - on-policy预测的近似方法
强化学习读书笔记 - 09 - on-policy预测的近似方法 参照 Reinforcement Learning: An Introduction, Richard S. Sutton and A ...
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
随机推荐
- PHP回顾(面向对象)
类中的成员属性不能够用函数为其赋值.public age = rand(1,100);//这是错误的: __get() __set() __isset() __unset() final 用来修 ...
- java常见问题 ——编辑报错1
报错1 The method add(CatNode) in the type List<CatNode> is not applicable for the arguments (Str ...
- codevs 2291 糖果堆 x
题目描述 Description [Shadow 1]第一题 WJMZBMR买了很多糖果,分成了N堆,排成一列.WJMZBMR说,如果Shadow能迅速求出第 ...
- 2019牛客暑期多校训练营(第二场)J
题意 给一个长度为1e9的只包含1和-1的数列,1的个数不超过1e7,计算有多少对\((l,r)\)满足\(\sum_{i=l}^r a[i]>0\) 分析 dp求出每段连续的1最右端为右端点的 ...
- Ubuntu安装之pycharm安装
什么??公司要用Ubuntu(乌班图)?不会用??怎么进行python开发??? 乌班图操作系统下载地址:http://releases.ubuntu.com/18.04/ubuntu-18.04.1 ...
- White Sheet
C - White Sheet 思路:先看代码,分成了四个条件.第一个和第二个表示的都是当白矩形存在某个黑矩形内部的情况. 另外就是:白矩形位于两个黑矩形的并集区域. 即可分为两种情况,一种是白矩形位 ...
- Oracle-sql*plus
连接命令 (1)conn[ect] 用法: conn 用户名/密码@网络服务名 [as sysdba/sysoper] 当用特权用户身份连接时,必须带上 as sysdba 或是 as sysoper ...
- Vue2实践computed监听Vuex中state对象中的对象属性时发生的一些有趣经历
今天想实现一个功能,在全局中随时改变用户的部分信息.这时候就想到了用Vuex状态控制器来存储用户信息,在页面中使用computed来监听用户这个对象.看似一个很简单的逻辑,就体现了我基本功的不扎实呀. ...
- 10.矩形覆盖 Java
题目描述 我们可以用2**1的小矩形横着或者竖着去覆盖更大的矩形.请问用n个21的小矩形无重叠地覆盖一个2n的大矩形,总共有多少种方法? 思路 其实,倒数第一列要么就是1个2**1的矩形竖着放,要么就 ...
- group_concat() 函数 拼接字符串长度有限制
最近,在做一个行转列的存储过程,遇到一个问题,问题如下: 我用group_concat()函数 来整合一个月每天的操作量,并将每天的操作量用CONCAT()函数拼接成 “MAX(IF(t.a = '2 ...