强化学习复习笔记 - DEEP
Outline
使用逼近器的特点:
较少数量的参数表达复杂的函数 (计算复杂度)
对一个权重的调整可以影响到很多的点 (泛化能力)
多种特征表示和逼近器结构 (多样性)
激活函数
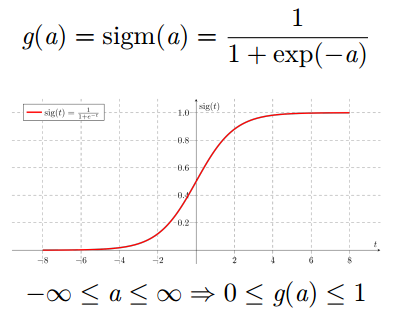
Sigmoid 激活函数
将神经元的输出压缩在 0 和 1 之间
永远都是正数
有界
严格递增
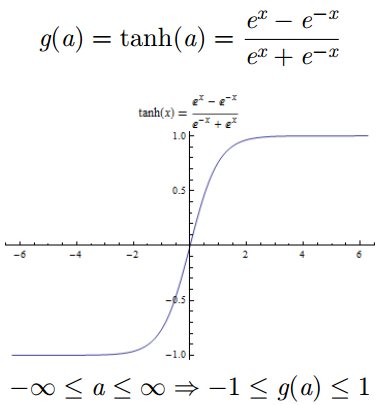
tanh 双曲正切函数
将神经元的输出压缩在
-1 和 1 之间
有正有负
有界
严格递增
线性整流 (Rectified Linear Unit, ReLU) 激活函数
以 0 作为下界 (永远都是非负的)
容易让神经元产生稀疏的激活行为
无上界
严格递增
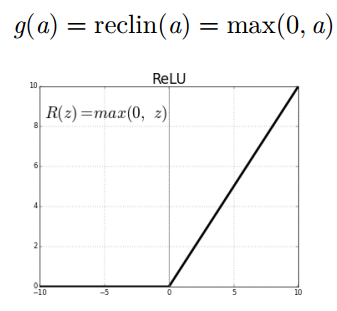
通用近似定理 (Hornik, 1991)
“如果一个前馈神经网络具有线性输出层和至少一层隐藏层, 只要给予网络足够数量的神经元,便可以实现以足够高精度来逼近任意一个在 Rn 的紧子集 (Compact subset) 上的连续函数。 ”
定理适用于 sigmoid, tanh, 和其它激活函数
但是定理并不代表一定存在某个学习算法, 能够找到具有满足近似性能的参数
置信风险: 分类器对 未知样本进行分类,得到的误差。
经验风险: 训练好的分类器,对训练样本重新分类得到的误差。即样本误差
结构风险:置信风险 + 经验风险
小批量 Mini-batch 梯度下降
更新是基于一组小批量的样本 {(x(i:i+b); y(i:i+b))}(不再是单 一样本)
梯度对应于正则化损失在小批量样本上的平均
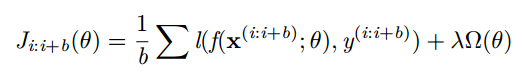
可以得到对梯度更加精确的估计
可以使用矩阵运算, 计算效率更高

在训练集 Dtrain上训练你的模型
在验证集 Dvalid上选择模型
-----包括选择超参; 隐含层尺寸; 学习率; 迭代/训练次数; 等等
在测试集 Dtext上评估泛化能力
泛化的含义是模型在未见过的样本上的表现
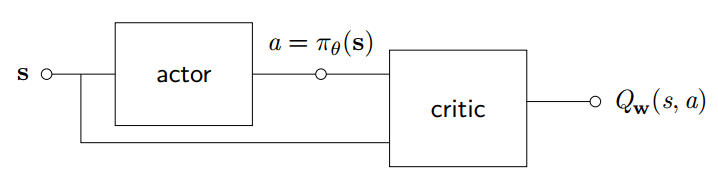
确定性 Actor-Critic
对于确定性策略, 可以使用神经网络逼近器构建 actor, 直接输出策略确定性的动作

设计另一个神经网络构造 Critic 用于逼近 Q 函数
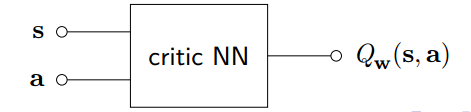
对 Critic NN 可以使用例如 TD 学习算法训练网络权重
对 Actor NN 希望能够输出最优动作使得 Q 函数最大化
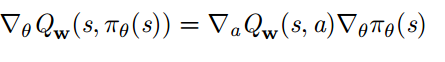

强化学习复习笔记 - DEEP的更多相关文章
- 强化学习读书笔记 - 02 - 多臂老O虎O机问题
# 强化学习读书笔记 - 02 - 多臂老O虎O机问题 学习笔记: [Reinforcement Learning: An Introduction, Richard S. Sutton and An ...
- 强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods)
强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods) 学习笔记: Reinforcement Learning: An Introduction, Richard S ...
- 强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning)
强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning) 学习笔记: Reinforcement Learning: An Introductio ...
- 强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods)
强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods) 学习笔记: Reinforcement Learning: An Introduction, Richa ...
- 强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces)
强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces) 学习笔记: Reinforcement Learning: An Introduction, Richard S. S ...
- 强化学习读书笔记 - 11 - off-policy的近似方法
强化学习读书笔记 - 11 - off-policy的近似方法 学习笔记: Reinforcement Learning: An Introduction, Richard S. Sutton and ...
- 强化学习读书笔记 - 10 - on-policy控制的近似方法
强化学习读书笔记 - 10 - on-policy控制的近似方法 学习笔记: Reinforcement Learning: An Introduction, Richard S. Sutton an ...
- 强化学习读书笔记 - 09 - on-policy预测的近似方法
强化学习读书笔记 - 09 - on-policy预测的近似方法 参照 Reinforcement Learning: An Introduction, Richard S. Sutton and A ...
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
随机推荐
- mongodb多条件分页查询的三种方法(转)
一.使用limit和skip进行分页查询 public List<User> pageList(int pageNum ,int pageSize){ List<User> u ...
- C#双缓冲解释
C#双缓冲解释 简单说就是当我们在进行画图操作时,系统并不是直接把内容呈现到屏幕 C#双缓冲 上,而是先在内存中保存,然后一次性把结果输出来,如果没用双缓冲的话,你会发现在画图过程中屏幕会闪的很厉害, ...
- gtid 同步1050异常处理
gtid 同步1050异常处理 .sql CREATE TABLE `fudao_student_lable` ( `id` ) NOT NULL AUTO_INCREMENT, `uid` ) un ...
- keras默认配置
使用keras后,会在用户目录下生成.keras/keras.json文件,Windows下为:C:\Users\user\.keras\keras.json,Linux下为:~/.keras/ker ...
- attr(name|properties|key,value|fn)
attr(name|properties|key,value|fn) 概述 设置或返回被选元素的属性值.大理石平台厂家 参数 nameStringV1.0 属性名称 propertiesMapV1 ...
- Python三引号(triple quotes)
python中三引号可以将复杂的字符串进行复制: python三引号允许一个字符串跨多行,字符串中可以包含换行符.制表符以及其他特殊字符. 三引号的语法是一对连续的单引号或者双引号(通常都是成对的用) ...
- react-native-swiper的Github地址
https://github.com/liyinglihuannan/react-native-swiper https://www.jianshu.com/p/4dba338ef37a(中文版
- NOIP 模拟赛 那些年,我们学过的文化课 --致已退役的fqk神犇.
/* 这大概是我第一次整理模拟赛吧. 唉. T2打了很长时间. 一开始读错题了中间都能缩合了. 真心对不起生物老师hhh. 这种状态判重的题目还是做的太少! */ 背单词 [题目描述] fqk 退役后 ...
- java中jsp的EL的定义以及使用
1.定义: EL(Expression Language) 是为了使JSP写起来更加简单.表达式语言的灵感来自于 ECMAScript 和 XPath 表达式语言,它提供了在 JSP 中简化表达式的方 ...
- Error:java: 错误: 不支持发行版本 5
本文链接:https://blog.csdn.net/wo541075754/article/details/70154604 在Intellij idea中新建了一个Maven项目,运行时报错如下: ...