Hadoop hadoop(2.9.0)---uber模式(小作业“ubertask”优化)
前言:
在有些情况下,运行于Hadoop集群上的一些mapreduce作业本身的数据量并不是很大,如果此时的任务分片很多,那么为每个map任务或者reduce任务频繁创建Container,势必会增加Hadoop集群的资源消耗,并且因为创建分配Container本身的开销,还会增加这些任务的运行时延。如果能将这些小任务都放入少量的Container中执行,将会解决这些问题。好在Hadoop本身已经提供了这种功能,只需要我们理解其原理,并应用它。
Uber运行模式就是解决此类问题的现成解决方案。
uber运行模式:
Uber运行模式对小作业进行优化,不会给每个任务分别申请分配Container资源,这些小任务将统一在一个Container中按照先执行map任务后执行reduce任务的顺序串行执行。那么什么样的任务,mapreduce框架会认为它是小任务呢?
- map任务的数量不大于mapreduce.job.ubertask.maxmaps参数(默认值是9)的值;
- reduce任务的数量不大于mapreduce.job.ubertask.maxreduces参数(默认值是1)的值;
- 输入文件大小不大于mapreduce.job.ubertask.maxbytes参数(默认为1个Block的字节大小)的值;
- map任务和reduce任务需要的资源量不能大于MRAppMaster(mapreduce作业的ApplicationMaster)可用的资源总量;也就是说yarn.app.mapreduce.am.resource.mb必须大于mapreduce.map.memory.mb和mapreduce.reduce.memory.mb以及yarn.app .mapreduce.am.resource.cpu-vcores必须大于mapreduce.map.cpu.vcores和mapreduce.reduce.cpu.vcores以启用ubertask。
参数mapreduce.job.ubertask.enable用来控制是否开启Uber运行模式,默认为false。
优化:该优化在单个JVM中按顺序运行“足够小”的作业。
以WordCount例
(1)限制任务的划分数量:
hadoop自带的Wordcount程序里面,MapReduce数量已经通过Job.setNumReduceTasks(int)方法已经设置为1,因此满足mapreduce.job.ubertask.maxreduces参数的限制。所以我们首先控制下map任务的数量,我们通过设置mapreduce.input.fileinputformat.split.maxsize参数来限制。看看在满足小任务前提,但是不开启Uber运行模式时的执行情况。执行命令如下:
[hadoop@master hadoop-2.9.0]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize=6 /wc.input /wc.output_2
file wc.intput为25K 参数 mapreduce.input.fileinputformat.split.maxsize=6 是以k为单位,我这里在分片的时候指定的6K,所以,最终分的片为5个,从下图可以明显的看出来,处理的总文件为1,分片数量为5,uber模式为false;还可以看到一共6个map任务,一个reduce任务。
结果如下:

web界面查看:

(2)开启uber模式
[hadoop@master hadoop-2.9.0]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize=6 -D mapreduce.job.ubertask.enable=true /wc.input /wc.output_5
wc.input 35k
结果如下:

这里是是6个map任务和1个reduce任务,但是之前的数据本地map任务= 5一行信息已经变为当地的其他maptasks=6。此外还增加了TOTAL_LAUNCHED_UBERTASKS、NUM_UBER_SUBMAPS、NUM_UBER_SUBREDUCES等信息,如下图所示:
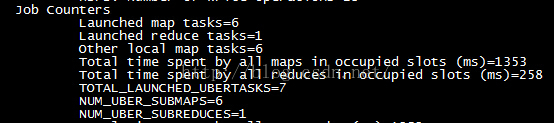
以下列出这几个信息的含义:
| 输出字段 | 描述 |
| TOTAL_LAUNCHED_UBERTASKS | 启动的Uber任务数 |
| NUM_UBER_SUBMAPS | Uber任务中的map任务数 |
| NUM_UBER_SUBREDUCES | Uber中reduce任务数 |
其他测试
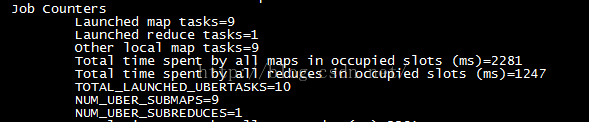
由于我主动控制了分片大小,导致分片数量是6,这小于mapreduce.job.ubertask.maxmaps参数的默认值9。按照之前的介绍,当map任务数量大于9时,那么这个作业就不会被认为小任务。所以我们先将分片大小调整为20字节,使得map任务的数量刚好等于9,然后执行以下命令:
[hadoop@master hadoop-2.9.0]hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize=20 -D mapreduce.job.ubertask.enable=true /wc.input /wc.output_6
file:wc.input 为172k

我们看到的确将输入数据划分为9份了其它信息如下
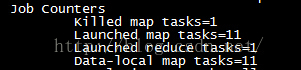
[hadoop@master hadoop-2.9.0]hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize=19 -D mapreduce.job.ubertask.enable=true /wc.input /wc.output_7

我们看到的确将输入数据划分为10份了其它信息如下:
- 设置当map任务全部运行结束后才开始reduce任务(参数mapreduce.job.reduce.slowstart.completedmaps设置为1.0,默认0.05)。
- 将当前Job的最大map任务尝试执行次数(参数mapreduce.map.maxattempts)和最大reduce任务尝试次数(参数mapreduce.reduce.maxattempts)都设置为1,默认为4。
- 取消当前Job的map任务的推断执行(参数mapreduce.map.speculative设置为false)和reduce任务的推断执行(参数mapreduce.reduce.speculative设置为false),默认为。
Hadoop hadoop(2.9.0)---uber模式(小作业“ubertask”优化)的更多相关文章
- Hadoop上路-01_Hadoop2.3.0的分布式集群搭建
一.配置虚拟机软件 下载地址:https://www.virtualbox.org/wiki/downloads 1.虚拟机软件设定 1)进入全集设定 2)常规设定 2.Linux安装配置 1)名称类 ...
- 从Hadoop骨架MapReduce在海量数据处理模式(包括淘宝技术架构)
从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到,以致后来初次接触Hadoop与MapReduce这两个东西,我便稍显兴奋,认为它们非常是神奇.而神奇的东西常能勾 ...
- hadoop环境搭建之关于NAT模式静态IP的设置 ---VMware12+CentOs7
很久没有更新了,主要是没有时间,今天挤出时间验证了一下,果然还是有些问题的,不过已经解决了,就发上来吧. PS:小豆腐看仔细了哦~ 关于hadoop环境搭建,从单机模式,到伪分布式,再到完全分布式,我 ...
- Hadoop之搭建完全分布式运行模式
一.过程分析 1.准备3台客户机(关闭防火墙.修改静态ip.主机名称) 2.安装JDK 3.配置环境变量 4.安装Hadoop 5.配置集群 6.单点启动 7.配置ssh免密登录 8.群起并测试集群 ...
- Hadoop 2.x 版本的单机模式安装
Hadoop 2.x 版本比起之前的版本在Hadoop和MapReduce上做了许多变化,主要的变化之一,是JobTracker被ResourceManager和ApplicationManager所 ...
- 【hadoop】hadoop3.2.0的安装并测试
前言:前段时间将hadoop01的虚拟机弄的崩溃掉了,也没有备份,重新从hadoop02虚拟上克隆过来的,结果hadoop-eclipse插件一样的编译,居然用不起了,找了3天的原因,最后还是没有解决 ...
- 简单说明hadoop集群运行三种模式和配置文件
Hadoop的运行模式分为3种:本地运行模式,伪分布运行模式,集群运行模式,相应概念如下: 1.独立模式即本地运行模式(standalone或local mode)无需运行任何守护进程(daemon) ...
- [hadoop] hadoop 运行 wordcount
讲准备好的文本文件放到hdfs中 执行 hadoop 安装包中的例子 [root@hadoop01 mapreduce]# hadoop jar hadoop-mapreduce-examples-2 ...
- hadoop hadoop install (1)
vmuser@vmuser-VirtualBox:~$ sudo useradd -m hadoop -s /bin/bash[sudo] vmuser 的密码: vmuser@vmuser-Virt ...
随机推荐
- robot framework 关键字Switch Browser和Select Window的区别
Switch Browser针对的是2个Open Browser以上的切换:Select Window针对的是1个Open Browser里面某个点击事件打开了另外一个新窗口 1.例子 Switch ...
- navicate的使用及用Python操作数据额库
Navicat使用 下载地址:<https://pan.baidu.com/s/1bpo5mqj> Navicat是基于mysql操作的,所以能否自主完成一些练习,就能够运用Navicat ...
- 树莓派手动设置静态IP和DNS方法
在使用树莓派的过程中,往往需要手动设置一个静态的IP地址,一来可以防止DHCP自动分配的IP变动,二来可提高树莓派的网络连接速度.查看官方文档 man dhcpcd.conf可知,需要配置静态IP的话 ...
- Java反射机制、注解及JPA实现
1.java反射概述 JAVA反射机制是在运行状态中,对于任意一个实体类,都能够知道这个类的所有属性和方法:对于任意一个对象,都能够调用它的任意方法和属性:这种动态获取信息以及动态调用对象方法的功能称 ...
- 多核cpu关闭、开启核心
列表 # ls /sys/devices/system/cpu/ 关闭 # echo '0' > /sys/devices/system/cpu/cpu1/online 开启 # echo '1 ...
- dubbo和mq的使用场景
MQ:消息队列.生产者消费者模式,可用于对消息实时性要求不高的场景.多进程之间间接调用关系 Dubbo:RPC实现.多进程之间直接调用关系 dubbo 1,rpc的分布式集群支持:负载均衡是对外提供一 ...
- 七年开发小结MyBatis 在 Spring 环境下的事务管理
MyBatis的设计思想很简单,可以看做是对JDBC的一次封装,并提供强大的动态SQL映射功能.但是由于它本身也有一些缓存.事务管理等功能,所以实际使用中还是会碰到一些问题——另外,最近接触了JFin ...
- 前台.cshtml得到cookie值方法
function Cookie_() { $.ajax({ url: "/Login_/do_cookie",//请求地址 dataType: "json",/ ...
- 异常-Maxwell无法全量同步触发
因为之前插入错误的表导致同步失败的问题 重新启动Maxwell,重新插入初始化表 重新触发
- IOTA私有链简单搭建
IOTA 参考:https://github.com/iotaledger/wallet 参考:https://github.com/iotaledger/iota.js 参考:https://git ...