使用Python将HTML转成PDF
主要使用的是wkhtmltopdf的Python封装——pdfkit
安装
1. Install python-pdfkit:
$ pip install pdfkit
2. Install wkhtmltopdf:
- Debian/Ubuntu:
$ sudo apt-get install wkhtmltopdf
- Redhat/CentOS
sudo yum intsall wkhtmltopdf
- MacOS
brew install Caskroom/cask/wkhtmltopdf
使用
一个简单的例子:
import pdfkit
pdfkit.from_url('http://google.com', 'out.pdf')
pdfkit.from_file('test.html', 'out.pdf')
pdfkit.from_string('Hello!', 'out.pdf')
你也可以传递一个url或者文件名列表:
pdfkit.from_url(['google.com', 'yandex.ru', 'engadget.com'], 'out.pdf')
pdfkit.from_file(['file1.html', 'file2.html'], 'out.pdf')
也可以传递一个打开的文件:
with open('file.html') as f:
pdfkit.from_file(f, 'out.pdf')
如果你想对生成的PDF作进一步处理, 你可以将其读取到一个变量中:
# 设置输出文件为False,将结果赋给一个变量
pdf = pdfkit.from_url('http://google.com', False)
你可以制定所有的 wkhtmltopdf 选项 <http://wkhtmltopdf.org/usage/wkhtmltopdf.txt>. 你可以移除选项名字前面的 '--' .如果选项没有值, 使用None, Falseor * 作为字典值:
options = {
'page-size': 'Letter',
'margin-top': '0.75in',
'margin-right': '0.75in',
'margin-bottom': '0.75in',
'margin-left': '0.75in',
'encoding': "UTF-8",
'no-outline': None
}
pdfkit.from_url('http://google.com', 'out.pdf', options=options)
默认情况下, PDFKit 将会显示所有的 wkhtmltopdf 输出. 如果你不想看到这些信息,你需要传递一个 quiet 选项:
options = {
'quiet': ''
}
pdfkit.from_url('google.com', 'out.pdf', options=options)
由于wkhtmltopdf的命令语法 , TOC 和 Cover 选项必须分开指定:
toc = {
'xsl-style-sheet': 'toc.xsl'
}
cover = 'cover.html'
pdfkit.from_file('file.html', options=options, toc=toc, cover=cover)
当你转换文件、或字符串的时候,你可以通过css选项指定扩展的 CSS 文件。
# 单个 CSS 文件
css = 'example.css'
pdfkit.from_file('file.html', options=options, css=css)
# Multiple CSS files
css = ['example.css', 'example2.css']
pdfkit.from_file('file.html', options=options, css=css)
你也可以通过你的HTML中的meta tags传递任意选项:
body = """
<html>
<head>
<meta name="pdfkit-page-size" content="Legal"/>
<meta name="pdfkit-orientation" content="Landscape"/>
</head>
Hello World!
</html>
"""
pdfkit.from_string(body, 'out.pdf') #with --page-size=Legal and --orientation=Landscape
配置
每个API调用都有一个可选的参数。这应该是pdfkit.configuration()API 调用的一个实例. 采用configuration 选项作为初始化参数。可用的选项有:
wkhtmltopdf——wkhtmltopdf二进制文件所在的位置。默认情况下pdfkit会尝试使用which(在类UNIX系统中) 或where(在Windows系统中)来判断.meta_tag_prefix--pdfkit的前缀指定 meta tags(元标签) - 默认情况是pdfkit-
示例 :针对wkhtmltopdf不在系统路径中(不在$PATH里面):
config = pdfkit.configuration(wkhtmltopdf='/opt/bin/wkhtmltopdf'))
pdfkit.from_string(html_string, output_file, configuration=config)
问题
IOError: 'No wkhtmltopdf executable found':
确保 wkhtmltopdf 在你的系统路径中($PATH), 会通过 configuration进行了配置 (详情看上文描述)。 在Windows系统中使用where wkhtmltopdf命令 或 在 linux系统中使用 which wkhtmltopdf 会返回 wkhtmltopdf二进制可执行文件所在的确切位置.
IOError: 'Command Failed'如果出现这个错误意味着 PDFKit不能处理一个输入。你可以尝试直接在错误信息后面直接运行一个命令来查看是什么导致了这个错误 (某些版本的 wkhtmltopdf会因为段错误导致处理失败)
正常生成,但是出现中文乱码
确保两项:
1)、你的系统中有中文字体
2)、在html中加入<meta charset="UTF-8">
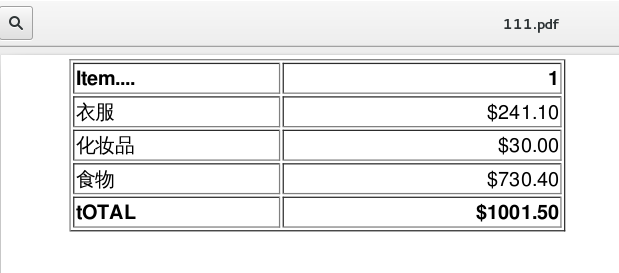
下面是我随便写的一个HTML表格:
<html>
<head><meta charset="UTF-8"></head>
<body>
<table width="400" border="1">
<tr>
<th align="left">Item....</th>
<th align="right">1</th>
</tr>
<tr>
<td align="left">衣服</td>
<td align="right">$241.10</td>
</tr>
<tr>
<td align="left">化妆品</td>
<td align="right">$30.00</td>
</tr>
<tr>
<td align="left">食物</td>
<td align="right">$730.40</td>
</tr>
<tr>
<th align="left">tOTAL</th>
<th align="right">$1001.50</th>
</tr>
</table>
</body>
</html>
下面是生成的PDF截图
另:https://pdfcrowd.com/#convert_by_input
使用Python将HTML转成PDF的更多相关文章
- 使用 Python 将 HTML 转成 PDF
背景 很多人应该经常遇到在网上看到好的学习教程和资料但却没有电子档的,心里顿时痒痒, 下述指导一下大家,如何将网站上的各类教程转换成 PDF 电子书. 关键核心 主要使用的是wkhtmltopdf的P ...
- python实现excel转换成pdf
1.安装 需要安装pywin32包,以实现对Office文件的操作,可以批量转换为pdf文件.支持 doc, docx, ppt, pptx, xls, xlsx 等格式. pip install p ...
- 用python DIY一个图片转pdf工具并打包成exe
最近因为想要看漫画,无奈下载的漫画是jpg的格式,网上的转换器还没一个好用的,于是乎就打算用python自己DIY一下: 这里主要用了reportlab.开始打算随便写几行,结果为若干坑纠结了挺久,于 ...
- Python 爬虫:把廖雪峰教程转换成 PDF 电子书
写爬虫似乎没有比用 Python 更合适了,Python 社区提供的爬虫工具多得让你眼花缭乱,各种拿来就可以直接用的 library 分分钟就可以写出一个爬虫出来,今天尝试写一个爬虫,将廖雪峰老师的 ...
- 将python代码打印成pdf
将python代码打印成pdf,打印出来很丑,完全不能看. mac下:pycharm 编辑器有print的功能,但是会提示: Error: No print service found. 所以需要一个 ...
- 使用python把html网页转成pdf文件
我们看到一些比较写的比较好文章或者博客的时候,想保存下来到本地当一个pdf文件,当做自己的知识储备,以后即使这个博客或者文章的连接不存在了,或者被删掉,咱们自己也还有. 当然咱们作为一个coder,这 ...
- 爬虫:把廖雪峰的教程转换成 PDF 电子书
写爬虫似乎没有比用 Python 更合适了,Python 社区提供的爬虫工具多得让你眼花缭乱,各种拿来就可以直接用的 library 分分钟就可以写出一个爬虫出来,今天就琢磨着写一个爬虫,将廖雪峰的 ...
- Python将html转化为pdf
前言 前面我们对博客园的文章进行了爬取,结果比较令人满意,可以一下子下载某个博主的所有文章了.但是,我们获取的只有文章中的文本内容,并且是没有排版的,看起来也比较费劲... 咋么办的?一个比较好的方法 ...
- 我是如何将博客转成PDF的
前言 只有光头才能变强 之前有读者问过我:"3y你的博客有没有电子版的呀?我想要份电子版的".我说:"没有啊,我没有弄过电子版的,我这边有个文章导航页面,你可以去文章导航 ...
随机推荐
- Javascript定时器学习笔记
掌握定时器工作原理必知:JavaScript引擎是单线程运行的,浏览器无论在什么时候都只且只有一个线程在运行JavaScript程序. 常言道:setTimeout和setInterval是伪线程. ...
- Android setTag方法的key问题
android在设计View类时,为了能储存一些辅助信息,设计一个一个setTag/getTag的方法.这让我想起在Winform设计中每个Control同样存在一个Tag. 今天要说的是我最近学习a ...
- XP之后Windows的一些变化
看到很多Windows开发人员,尤其是C++程序员思维还是停留在XP操作系统,当然根据工作是否需要新知识 ,这本身没有错.但是实际上Vista之后的Win7, 再之后的Win8 ,Windows已经发 ...
- [异常解决] 安卓6.0权限问题导致老蓝牙程序出现异常解决办法:Need ACCESS_COARSE_LOCATION or ACCESS_FINE_LOCATION permission...
一.问题: 之前写的一款安卓4.4的应用程序,用来连接蓝牙BLE,而现在拿出来用新的AS编译(此时SDK为6.0,手机也是6.0)应用程序并不能搜索到蓝牙,查看log总是报权限错误: Need ACC ...
- IOS 公共类-MyMBProgressUtil Progress显示
IOS 公共类-MyMBProgressUtil Progress显示 此公共类用于显示提示框,对MBProgress的进一步封装.可以看下面的代码 接口: @interface MyMBProgre ...
- DDD~基础设施层~续
回到目录 在之前写的DDD~基础设施层文章中,提到了UnitOfWork,它里面有一些方法,但经过项目证明,不应该有Save和IsExplicitSubmit,而这个工作单元只起到了数据上下文统一的作 ...
- EF架构~CodeFirst生产环境的Migrations
回到目录 Migrations即迁移,它是EF的code first模式出现的产物,它意思是说,将代码的变化反映到数据库上,这种反映有两种环境,一是本地开发环境,别一种是服务器的生产环境,本地开发环境 ...
- Time33算法
Time33是字符串哈希函数,现在几乎所有流行的HashMap都采用了DJB Hash Function,俗称"Times33"算法.Times33的算法很简单,就是不断的乘33. ...
- fir.im Weekly - 如何愉悦地进行持续集成
持续集成是一项"一次配置长期受益"的投入,让开发.测试.生产环境的统一变得更加自动高效. 本期 fir.im Weekly 收录了关于 Android.iOS 持续集成的最新实践分 ...
- iOS-数据持久化-对象归档
一.简单说明 对象归档是将对象归档以文件的形式保存到磁盘中(也称为序列化,持久化),使用的时候读取该文件的保存路径读取文件的内容(也称为接档,反序列化), (对象归档的文件是保密的,在磁盘上无法查看文 ...