pytorch构建自己的数据集
现在需要在json文件里面读取图片的URL和label,这里面可能会出现某些URL地址无效的情况。
python读取json文件
此处只需要将json文件里面的内容读取出来就可以了
with open("json_path",'r') ad load_f:
load_dict = json.load(load_f)
json_path是json文件的地址,json文件里面的内容读取到load_dict变量中,变量类型为字典类型。
python通过URL打开图片
通过skimage获取URL图片是简单的方式。
from skimage import io
image = io.imread(img_src) # img_src是图片的URL
io.imshow(image)
io.show()
pytorch构建自己的数据集
pytorch中文网中有比较好的讲解: https://ptorch.com/news/215.html
加载图片预处理以及可视化见: https://oldpan.me/archives/pytorch-transforms-opencv-scikit-image
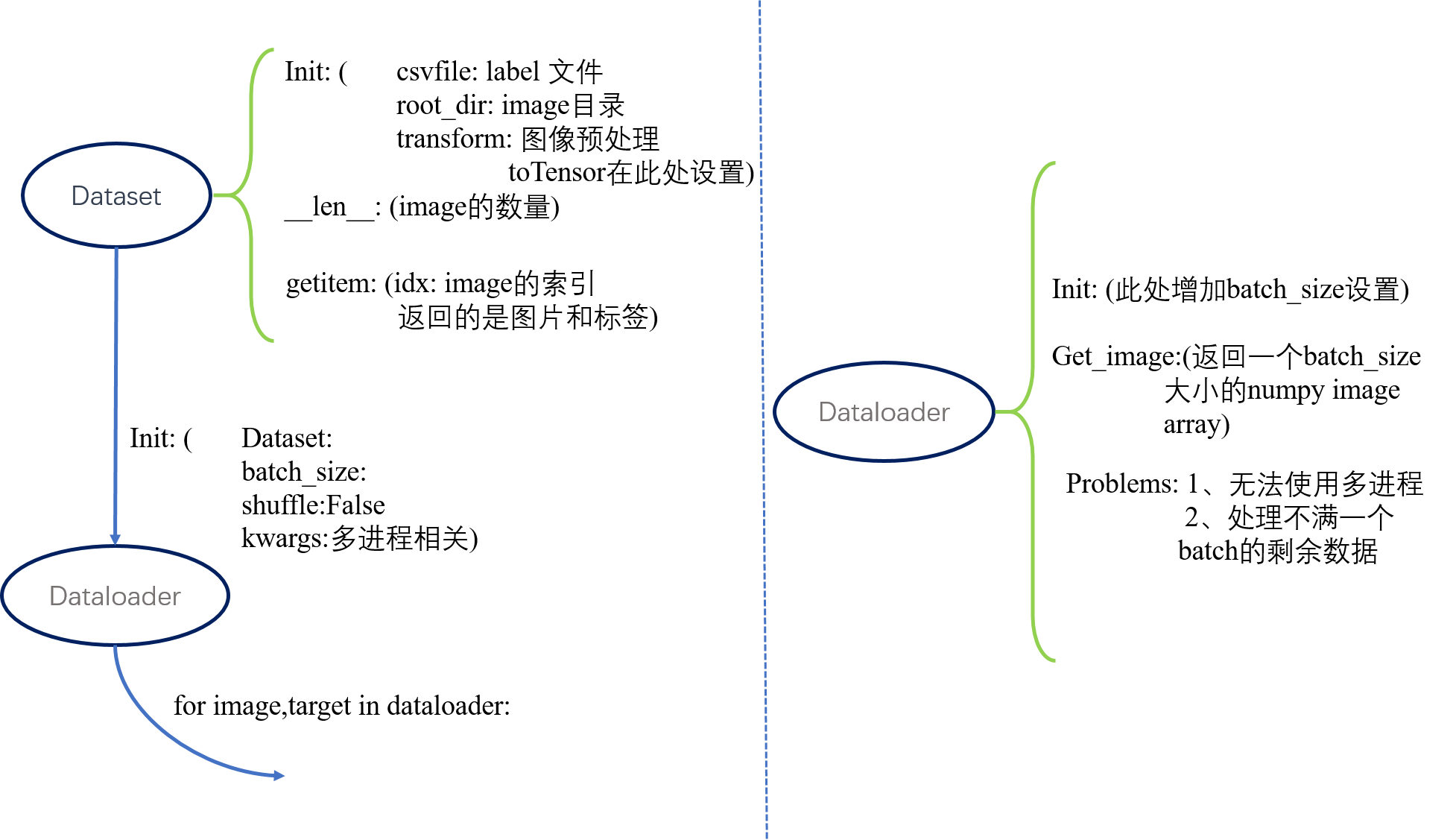
定义自己的数据集使用类 torch.utils.data.Dataset这个类,这个类中有三个关键的默认成员函数,__init__,__len__,__getitem__。
__init__类实例化应用,所以参数项里面最好有数据集的path,或者是数据以及标签保存的json、csv文件,在__init__函数里面对json、csv文件进行解析。
__len__需要返回images的数量。
__getitem__中要返回image和相对应的label,要注意的是此处参数有一个index,指的返回的是哪个image和label。
import torch
from torchvision import transforms
import json
import os
from PIL import Image class ProductDataset(torch.utils.data.Dataset):
def __init__(self,json_path,data_path,transform = None,train = True):
with open(json_path,'r') as load_f:
self.json_dict = json.load(load_f)
self.json_dict = self.json_dict["images"]
self.train = train
self.data_path = data_path
self.transform = transform def __len__(self):
return len(self.json_dict) def __getitem__(self,index):
image_id = os.path.join(self.data_path + '/',str(self.json_dict[index]["id"]))
image = Image.open(image_id)
image = image.convert('RGB')
label = int(self.json_dict[index]["class"])
if self.transform:
image = self.transform(image)
if self.train:
return image,label
else:
image_id = self.json_dict[index]["id"]
return image,label,image_id if __name__ == '__main__':
val_dataset = ProductDataset('data/FullImageTrain.json','data/train',train=False,
transform=transforms.Compose([
transforms.Pad(4),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
]))
kwargs = {'num_workers': 4, 'pin_memory': True}
test_loader = torch.utils.data.DataLoader(dataset=val_dataset,
batch_size=32,
shuffle=False,
**kwargs) print(val_dataset.__len__())
count = 0
for image,label,image_id in test_loader:
print(image.shape,count)
count += 1
关于transform,图像预处理的各个函数功能介绍如下:
torch.transforms是常见的图像变换,可以用Compose连接起来。
下面是Transforms on PIL Image:
transforms.CenterCrop(size):
size可以是一个像(h,w)的sequence,这样输出的是一个中心裁剪的(h,w)图像。
transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0):
随机更改图像的亮度,对比度和饱和度。
传递的参数是float型变量或者是tuple(元素是float型)型变量,如果是tuple型变量,第一个元素是min值,第二个元素是max值。
transforms.Grayscale(num_output_channels=1)
将Image转换为灰度值
transforms.Pad(padding, fill=0, padding_mode='constant')
padding这个参数,如果给定的是单个的值,那么会pad所有的边。
transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant')
随机裁剪图片到给定尺寸
size如果是(h,w)这样的sequence,那么将剪出一个(h,w)大小的图片
transforms.RandomHorizontalFlip(p=0.5):
以给定的概率随机水平翻转给定的PIL图像。
transforms.RandomResizedCrop(size,scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=2)
将给定的图像随机裁剪为不同的大小和高宽比,然后缩放所裁剪的图像到指定大小。
该操作的含义:即使只是该物体的一部分,我们也认为这是该类物体。
scale为0.08到1的意思为裁剪的面积比例为0.08到1,注意是面积不是边,ratio是高宽比。
transforms.Resize(size, interpolation=2):
Resize给定的Image图像到指定大小。
size:给定图像大小
interpolation:差值方法,默认是PIL.Image.BILINEAR
下面是Transforms on torch.*Tensor:
transforms.Normalize(mean,var,inplace=False):
标准化图像,mean和var给定三个值的情况下,是分别对于RGB三个channel进行标准化。
pytorch构建自己的数据集的更多相关文章
- 使用pytorch构建神经网络的流程以及一些问题
使用PyTorch构建神经网络十分的简单,下面是我总结的PyTorch构建神经网络的一般过程以及我在学习当中遇到的一些问题,期望对你有所帮助. PyTorch构建神经网络的一般过程 下面的程序是PyT ...
- 使用PyTorch构建神经网络模型进行手写识别
使用PyTorch构建神经网络模型进行手写识别 PyTorch是一种基于Torch库的开源机器学习库,应用于计算机视觉和自然语言处理等应用,本章内容将从安装以及通过Torch构建基础的神经网络,计算梯 ...
- pytorch 加载mnist数据集报错not gzip file
利用pytorch加载mnist数据集的代码如下 import torchvision import torchvision.transforms as transforms from torch.u ...
- 使用PyTorch构建神经网络以及反向传播计算
使用PyTorch构建神经网络以及反向传播计算 前一段时间南京出现了疫情,大概原因是因为境外飞机清洁处理不恰当,导致清理人员感染.话说国外一天不消停,国内就得一直严防死守.沈阳出现了一例感染人员,我在 ...
- pytorch构建自己设计的层
下面是如何自己构建一个层,分为包含自动反向求导和手动反向求导两种方式,后面会分别构建网络,对比一下结果对不对. -------------------------------------------- ...
- Pytorch文本分类(imdb数据集),含DataLoader数据加载,最优模型保存
用pytorch进行文本分类,数据集为keras内置的imdb影评数据(二分类),代码包含六个部分(详见代码) 使用环境: pytorch:1.1.0 cuda:10.0 gpu:RTX2070 (1 ...
- 【猫狗数据集】pytorch训练猫狗数据集之创建数据集
猫狗数据集的分为训练集25000张,在训练集中猫和狗的图像是混在一起的,pytorch读取数据集有两种方式,第一种方式是将不同类别的图片放于其对应的类文件夹中,另一种是实现读取数据集类,该类继承tor ...
- PyTorch迁移学习-私人数据集上的蚂蚁蜜蜂分类
迁移学习的两个主要场景 微调CNN:使用预训练的网络来初始化自己的网络,而不是随机初始化,然后训练即可 将CNN看成固定的特征提取器:固定前面的层,重写最后的全连接层,只有这个新的层会被训练 下面修改 ...
- pytorch构建优化器
这是莫凡python学习笔记. 1.构造数据,可以可视化看看数据样子 import torch import torch.utils.data as Data import torch.nn.func ...
随机推荐
- Vue2.0 v-for 中 :key 到底有什么用?
要解释 key 的作用,不得不先介绍一下虚拟 DOM 的 Diff 算法了. vue 和 react 的虚拟 DOM 的Diff算法大致相同,其核心是基于两个简单的假设: 1.两个相同的组件产生类似的 ...
- WebMagic
一.WebMagic的四个组件 1.Downloader Downloader负责从互联网上下载页面,默认使用apache HttpClient作为下载工具 2.PageProcessor 负责解析页 ...
- linux 防火墙 iptables 目录
linux iptables 防火墙简介 Linux 防火墙:Netfilter iptables 自动化部署iptables防火墙脚本
- vue中router使用keep-alive缓存页面的注意事项
<keep-alive exclude="QRCode"> <router-view></router-view> </keep-aliv ...
- css设置input获得焦点的样式
input:focus{ 样式; } 这样就ok
- 有没有无痛无害的人体成像方法?OCT(光学相干断层扫描)了解一下
关于之前推送的胸片和CT有很多的小伙伴关心射线对人体的伤害的问题,在医学检查射线的强度和剂量已经有严格的标准,偶尔进行一次CT扫描是没有问题的,那么有没有一种完全无害的扫描检查呢?今天小编就给大家介绍 ...
- How do you explain Machine Learning and Data Mining to non Computer Science people?
How do you explain Machine Learning and Data Mining to non Computer Science people? Pararth Shah, ...
- sitecore 数字化营销-path funnel
路径分析器是一个应用程序,允许您查看联系人在浏览网站时所采用的各种路径.您可以查看联系人在转换目标并与广告系列互动时所采用的路径,让您深入了解哪些路径为每次转化提供最佳参与价值,以及哪些路径效率较低且 ...
- [antd-design-pro] mock 数据(post,request不一致)Sorry, we need js to run correctly!
Sorry, we need js to run correctly! 可能问题: mock数据 api 和 request api 不一致 'POST /api/banners/left' ...
- 异步async、await和Future的使用技巧
由于前面的HTTP请求用到了异步操作,不少小伙伴都被这个问题折了下腰,今天总结分享下实战成果.Dart是一个单线程的语言,遇到有延迟的运算(比如IO操作.延时执行)时,线程中按顺序执行的运算就会阻塞, ...