03Hadoop的TopN的问题
TopN的问题分为两种:一种是建是唯一的,还有是建非唯一。我们这边做的就是建是唯一的。
这里的建指得是:下面数据的第一列。
有一堆数据,想根据第一列找出里面的Top10.
如下:
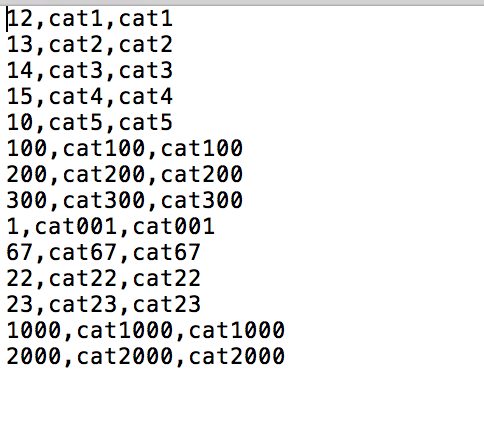
关键:在map和reduce阶段都使用了TreeMap这个数据结构,他有从小到大的排序功能,所以排第一的最小,依次增大。限定大小为10 ,只要超过十,就把排在第一个的值给删除。
代码如下:
package com.book.topn; import java.io.IOException;
import java.util.Iterator;
import java.util.Set;
import java.util.SortedMap;
import java.util.TreeMap; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TopN { static class Mapper1 extends Mapper<LongWritable, Text, NullWritable, Text> {
public SortedMap<Double, Text> top10cats = new TreeMap<Double, Text>();
public int N = 10; @Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, NullWritable, Text>.Context context)
throws IOException, InterruptedException { String[] lines = value.toString().split(",");
Double weight = Double.parseDouble(lines[0]);
// 一行读完,然后把数据
top10cats.put(weight, new Text(value)); // 如果Map
if (top10cats.size() > N) {
top10cats.remove(top10cats.firstKey());
}
} // 待执行完map的读取比较操作后,就把TreeMap里面的数据打印出来。
@Override
protected void cleanup(Mapper<LongWritable, Text, NullWritable, Text>.Context context)
throws IOException, InterruptedException { Set<Double> set = top10cats.keySet(); Iterator<Double> iterator = set.iterator(); while (iterator.hasNext()) { context.write(NullWritable.get(), top10cats.get(iterator.next()));
} } } static class reduce1 extends Reducer<NullWritable, Text, NullWritable, Text> { SortedMap<Double, Text> finalTop = new TreeMap<Double, Text>();
private int N = 10; @Override
protected void reduce(NullWritable arg0, Iterable<Text> values,
Reducer<NullWritable, Text, NullWritable, Text>.Context context)
throws IOException, InterruptedException { for (Text value : values) { String[] finalresult = value.toString().split(","); finalTop.put(Double.parseDouble(finalresult[0]), new Text(value));
if (finalTop.size() > N) {
finalTop.remove(finalTop.firstKey());
}
; } Set<Double> set = finalTop.keySet(); Iterator<Double> iterator = set.iterator(); // 依次写入到文件中
while (iterator.hasNext()) { context.write(NullWritable.get(), finalTop.get(iterator.next()));
} } } public static void main(String[] args) throws Exception, IOException { Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(TopN.class); job.setMapperClass(Mapper1.class);
job.setReducerClass(reduce1.class); job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class); job.setOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class); // 指定输入的数据的目录
FileInputFormat.setInputPaths(job, new Path("/Users/mac/Desktop/TopN.txt")); FileOutputFormat.setOutputPath(job, new Path("/Users/mac/Desktop/flowresort")); boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1); } }
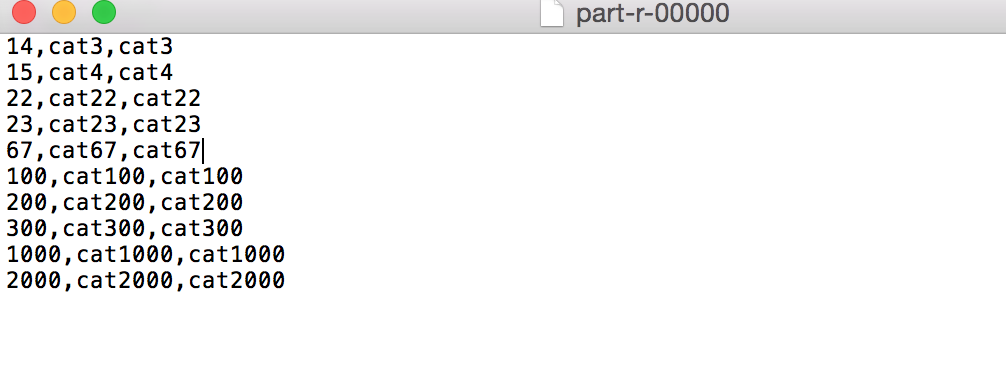
结果:
注意点:
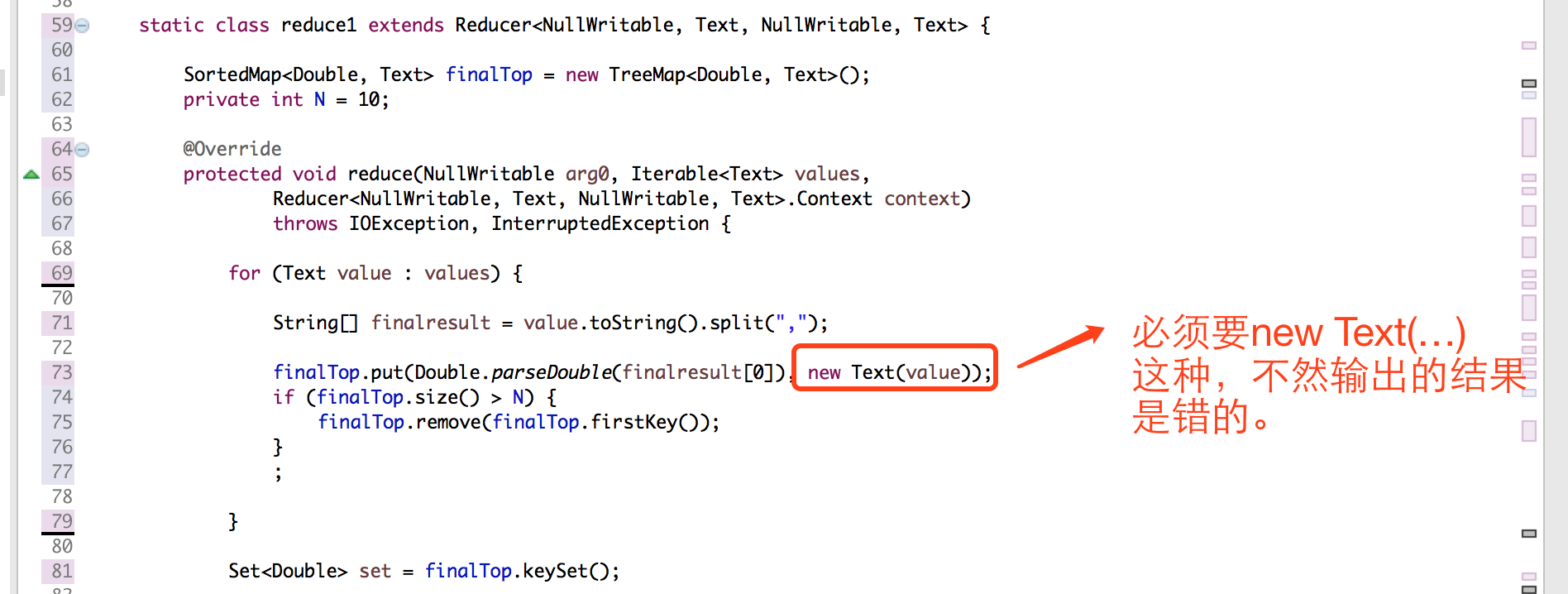
上面的注意点一定要切记。
03Hadoop的TopN的问题的更多相关文章
- storm入门(二):关于storm中某一段时间内topN的计算入门
刚刚接触storm 对于滑动窗口的topN复杂模型有一些不理解,通过阅读其他的博客发现有两篇关于topN的非滑动窗口的介绍.然后转载过来. 下面是第一种: Storm的另一种常见模式是对流式数据进行所 ...
- 【mysql】一维数据TopN的趋势图
创建数据表语句 数据表数据 对上述数据进行TopN排名 select severity,sum(count) as sum from widgt_23 where insertTstamp>=' ...
- 【转载】使用LFM(Latent factor model)隐语义模型进行Top-N推荐
最近在拜读项亮博士的<推荐系统实践>,系统的学习一下推荐系统的相关知识.今天学习了其中的隐语义模型在Top-N推荐中的应用,在此做一个总结. 隐语义模型LFM和LSI,LDA,Topic ...
- QL查询案例:取得分组 TOP-N
[转]SQL查询案例:取得分组 TOP-N CREATE TABLE TopnTest ( name VARCHAR(10), --姓名 procDate DATETIME, ...
- 使用LFM(Latent factor model)隐语义模型进行Top-N推荐
最近在拜读项亮博士的<推荐系统实践>,系统的学习一下推荐系统的相关知识.今天学习了其中的隐语义模型在Top-N推荐中的应用,在此做一个总结. 隐语义模型LFM和LSI,LDA,Topic ...
- 大数据算法设计模式(1) - topN spark实现
topN算法,spark实现 package com.kangaroo.studio.algorithms.topn; import org.apache.spark.api.java.JavaPai ...
- topN 算法 以及 逆算法(随笔)
topN 算法 以及 逆算法(随笔) 注解:所谓的 topN 算法指的是 在 海量的数据中进行排序从而活动 前 N 的数据. 这就是所谓的 topN 算法.当然你可以说我就 sort 一下 排序完了直 ...
- pyspark进行词频统计并返回topN
Part I:词频统计并返回topN 统计的文本数据: what do you do how do you do how do you do how are you from operator imp ...
- TOP-N类查询
Top-N查询 --Practices_29:Write a query to display the top three earners in the EMPLOYEES table. Displa ...
随机推荐
- 潭州课堂25班:Ph201805201 django 项目 第二十五课 文章多级评论前后台实现 (课堂笔记)
添加新闻评论功能 1.分析 业务处理流程: 判断前端传的新闻id是否为空,是否为整数.是否不存在 判断评论的内容是否为空 判断是否有父评论,父评论的id是否与新闻id匹配 判断用户是否登录 保存新闻评 ...
- python 有参装饰器与迭代器
1.有参装饰器 模板: def auth(x): def deco(func): def timmer(*args,**kwargs ): res = func(*args,**kwargs ) re ...
- BZOJ4963 : String
用SAM支持往末尾在线添加字符的功能. 设$f[i][j]$表示右端点为i的每个左端点的答案,那么当$i$变为$i+1$时,在SAM的parent链形成的树中会新增一个叶子$p$. 对于每个节点,维护 ...
- linux上安装mysql,亲试成功
安装mysql参考 网址https://blog.csdn.net/a774630093/article/details/79270080 本文更加详细. 1.先检查系统是否装有mysql rpm - ...
- Java 基础 集合框架
Java中的集合从类的继承和接口的实现结构来说,可以分为两大类: 1 继承自Collection接口,包含List.Set和Queue等接口和实现类. 2 继承自Map接口,主要包含哈希表相关的集合类 ...
- Python内置GUI模块Tkinter的几点笔记
组件属性,用法 组件位置 更多
- function前加运算符实现立即执行函数
我们知道函数的调用方式通常是FunctionName() 但如果我们尝试为一个"定义函数"末尾加上(),解析器是无法理解的. function msg(){ alert('mess ...
- 在latex或者mathtype中如何输入花体,如拉式量L
这个问题困扰我很久,知道我找到这个答案: 把 \mathcal{L} 直接黏贴到mathtype的编辑框中就可以产生花体L了
- db2 load报文件系统满
使用db2 load导入数据 数据量比较大时常常会报文件系统已满错误. 原因分析:导入表建有索引,在load的“索引复制”阶段会从系统临时表空间拷贝到目标表空间,导致系统临时表空间所在的文件系统满,l ...
- MySQL优化的一些基础
在Apache, PHP, mysql的体系架构中,MySQL对于性能的影响最大,也是关键的核心部分.对于Discuz!论坛程序也是如此,MySQL的设置是否合理优化,直接 影响到论坛的速度和承载量! ...