[solr] - IKAnalyzer 分词加入
1、下载IK Analyzer中文分词器:http://ik-analyzer.googlecode.com/files/IK%20Analyzer%202012FF_hf1.zip
2、解压出zip文件,将IKAnalyzer2012FF_u1.jar复制到tomcat中的solr\WEB-INF\lib目录中
3、在tomcat的solr\WEB-INF目录中,新建一个classes文件夹,将解压出的zip文件中的IKAnalyzer.cfg.xml和stopword.dic复制到classes中
4、用记事本打开E:\solrhome\mycore\conf\schema.xml文件,加入这句话到<schema/>节点内:
<fieldType name="text_general" class="solr.TextField">
<analyzer type="index" class="org.wltea.analyzer.lucene.IKAnalyzer" />
<analyzer type="query" class="org.wltea.analyzer.lucene.IKAnalyzer" />
</fieldType>
schema.xml是solr core位置,具体参见第一篇文章:http://www.cnblogs.com/HD/p/3977799.html
5、启动或重启tomcat
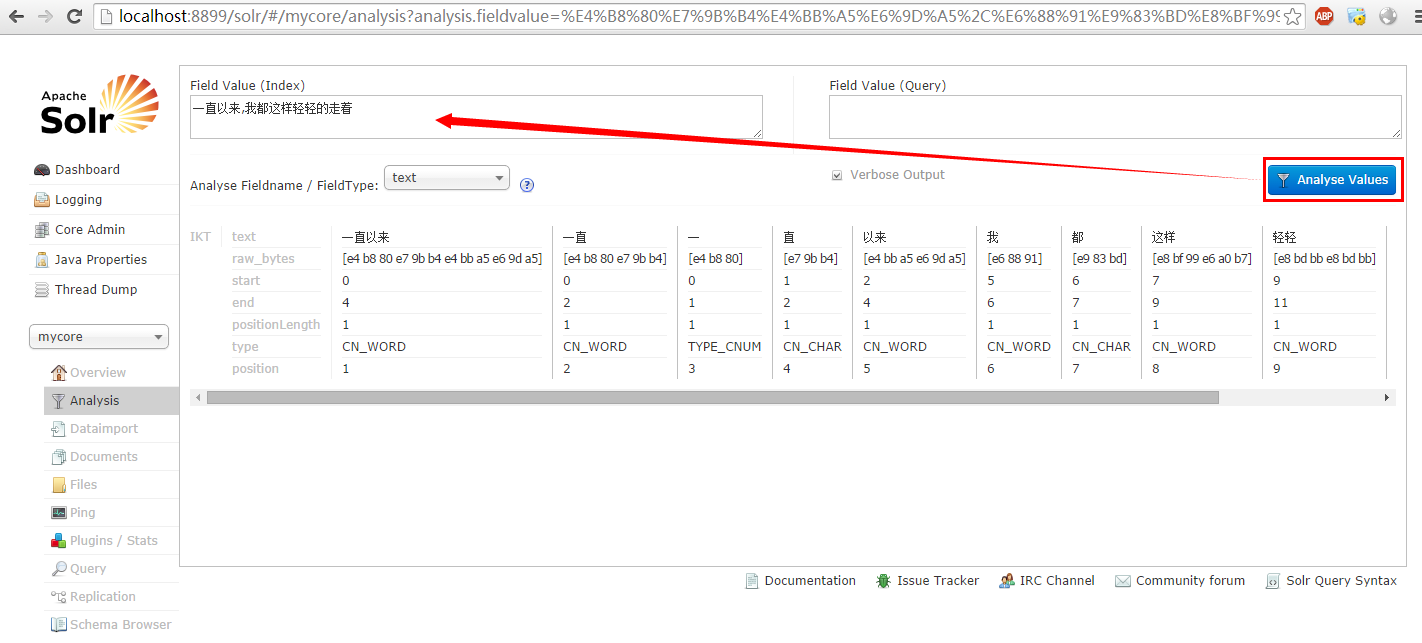
6、进入solr web: http://localhost:8899/solr
输入:一直以来,我都这样轻轻的走着
结果:
7、使用post.jar测试:
<add>
<doc>
<field name="id">88SS-CSS2</field>
<field name="name">我是Robin</field>
<field name="name1">my name 1</field>
<field name="publisher_id">12</field>
<field name="core0">welcome</field>
<field name="text">一直以来,我都是这样轻轻的走着...</field>
</doc>
<doc>
<field name="id">OMC-9923</field>
<field name="name">My test core, ha ha solr, I am come in.ss</field>
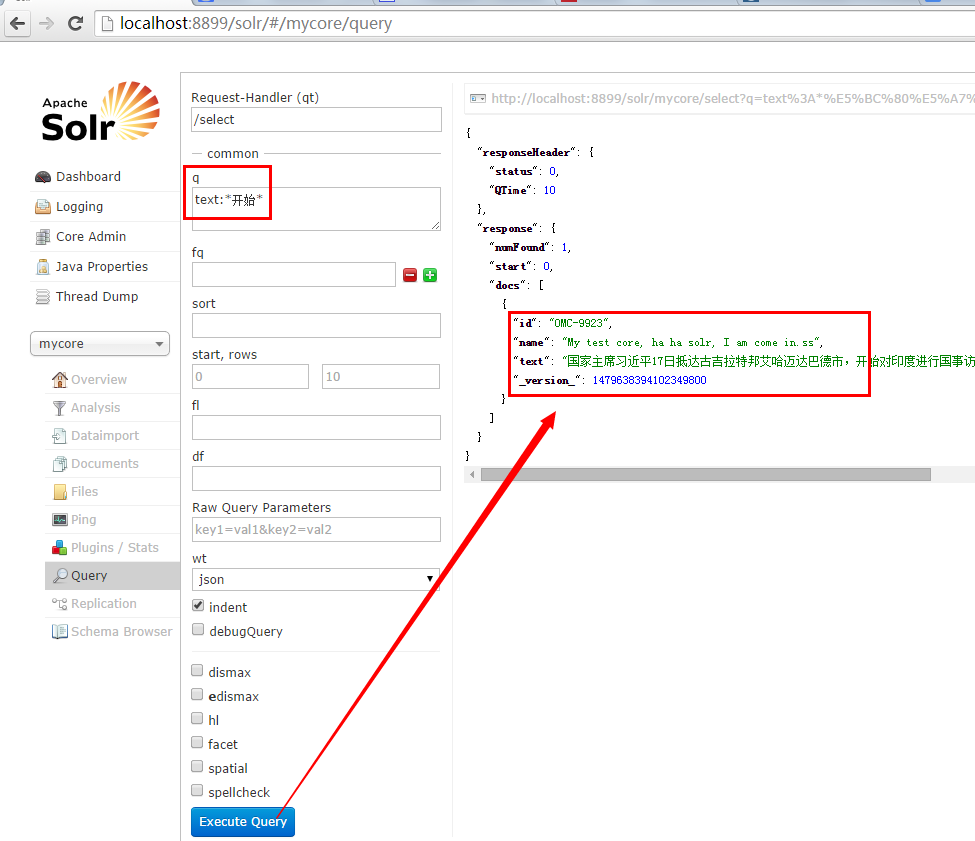
<field name="text">国家主席习xx17日抵达古吉拉特邦艾哈迈达巴德市,开始对印度进行国事访问。 当地时间下午2时50分许,习xx乘坐的专机抵达艾哈迈达巴德的机场。习xx和夫人彭xx受到印度古吉拉特邦邦长克利、首席部长帕特尔、印度驻华大使康特等热情迎接。图为习xx和夫人彭xx在印度总理莫迪陪同下一起荡秋千。</field>
</doc>
</add>
如何使用post.jar测试,参见第一篇文章:http://www.cnblogs.com/HD/p/3977799.html
结果:
[solr] - IKAnalyzer 分词加入的更多相关文章
- solr 中文分词 IKAnalyzer
solr中文分词器ik, 推荐资料:http://iamyida.iteye.com/blog/2220474?utm_source=tuicool&utm_medium=referral 使 ...
- Solr配置Ikanalyzer分词器
上一篇文章讲解在win系统中如何安装solr并创建一个名为test_core的Core,接下为text_core配置Ikanalyzer 分词器 1.打开text_core的instanceDir目录 ...
- docker-compose 安装solr+ikanalyzer
docker-compose.yml version: '3.1' services: solr: image: solr restart: always container_name: solr p ...
- Solr6+IKAnalyzer分词环境搭建
环境要求 Zookeeper版本:zookeeper-3.4.8 JDK版本: jdk1.8. Solr版本:solr-6.4.1 Tomcat版本:tomcat8 ZK地址:127.0.0.1:21 ...
- solr配置分词器
一.solr4.10 + mmseg4j-2.2.0分词器 1.solr的安装部署:http://www.cnblogs.com/honger/p/5876289.html,注意不同的版本安装方式可能 ...
- solr 中文分词相关(转载)
smartcn和ik的对比,来自http://www.cnblogs.com/hadoopdev/p/3465556.html 一.引言: 年的时候,就曾经有项目涉及到相关的应用(Lunce构建全文搜 ...
- Solr7.3.0入门教程,部署Solr到Tomcat,配置Solr中文分词器
solr 基本介绍 Apache Solr (读音: SOLer) 是一个开源的搜索服务器.Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现.Apache ...
- Lucene使用IKAnalyzer分词实例 及 IKAnalyzer扩展词库
文章转载自:http://www.cnblogs.com/dennisit/archive/2013/04/07/3005847.html 方案一: 基于配置的词典扩充 项目结构图如下: IK分词器还 ...
- lucene全文搜索之二:创建索引器(创建IKAnalyzer分词器和索引目录管理)基于lucene5.5.3
前言: lucene全文搜索之一中讲解了lucene开发搜索服务的基本结构,本章将会讲解如何创建索引器.管理索引目录和中文分词器的使用. 包括标准分词器,IKAnalyzer分词器以及两种索引目录的创 ...
随机推荐
- PHP 时间 date,strtotime ,time计算1970开始的第几天
首先,需要看你的php时区配置参数 方式1:更改php配置文件,然后从其fast-cgi或者php调用的地方: 方式2:date_default_timezone_set('PRC'); date函数 ...
- iOS开发多线程篇—NSOperation简单介绍
iOS开发多线程篇—NSOperation简单介绍 一.NSOperation简介 1.简单说明 NSOperation的作⽤:配合使用NSOperation和NSOperationQueue也能实现 ...
- MySQL 主从热备份(读写分离)
MySQL的主从备份,听个名词很高大上,其实都是MySQL原本就实现的了,你只需要简单配置一下就可以实现. 第一步:保持主从两个数据库是同步的,最好事先手动同步一下: 第二步:停止两个数据库,分别更改 ...
- bzoj 3131: [Sdoi2013]淘金
#include<cstdio> #include<iostream> #include<queue> #include<algorithm> #def ...
- 获取数据库里面最新的ID
你如果新插入的一段资料,你想获取它的ID,就用 “mysql_insert_id()”; 并且要重新定义一个名称
- Node.js 创建HTTP服务器
Node.js 创建HTTP服务器 如果我们使用PHP来编写后端的代码时,需要Apache 或者 Nginx 的HTTP 服务器,并配上 mod_php5 模块和php-cgi. 从这个角度看,整个& ...
- hdu 1050 (preinitilization or postcleansing, std::fill) 分类: hdoj 2015-06-18 11:33 34人阅读 评论(0) 收藏
errors, clauses in place, logical ones, should be avoided. #include <cstdio> #include <cstr ...
- 绑定hosts
测试过程中需绑定hosts.将测试环境IP绑定域名,输入域名即可连接到测试环境. 1 hosts文件地址:C:\WINDOWS\system32\drivers\etc 2 用记事本打开hosts ...
- Ubuntu中安装eclipse ,双击eclipse出现invalid configuration location问题
ubuntu invalid configuration location 标签: myeclipse for ubuntu ubuntu myeclipse ubuntu安装myecli ...
- Struts2之过滤器和拦截器的区别
刚学习Struts2这个框架不久,心中依然有一个疑惑未解那就是过滤器和拦截器的区别,相信也有不少人跟我一样对于这个问题没有太多的深入了解 那么下面我们就一起来探讨探讨 过滤器,是在java web中, ...