CUDA程序优化-1.基础介绍
简介
本合集主要介绍我在开发分布式异构训练框架时的CUDA编程实践和性能优化的相关内容。主要包含以下几个部分:
- 介绍CUDA的基本概念和架构,帮助读者建立对CUDA的初步认识,包括硬件架构/CUDA基础等内容
- 介绍一些性能优化技巧和工具,帮助读者优化CUDA程序的执行效率
- 结合具体的代码示例来说明一个cuda程序的优化思路和结果, 帮助读者更好地理解和掌握CUDA编程和性能优化的实践方法
希望通过本文档,能够帮助大家写出更高效的CUDA程序。下面我们就开始吧~
1. 硬件架构
要说清楚为什么GPU比CPU更适合大规模并行计算, 要从硬件层面开始说起
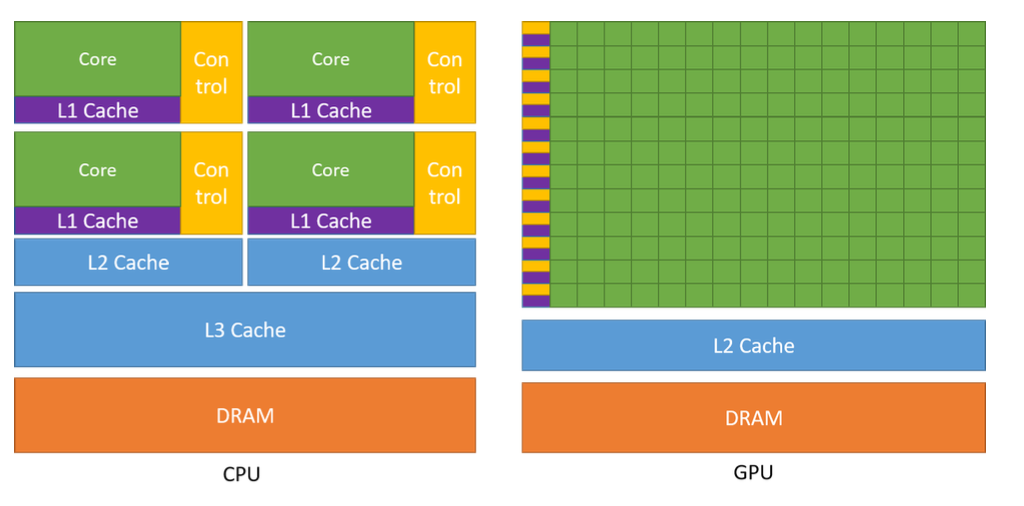
以当前较主流的硬件i9-14900k和A100为例:
i9-14900k: 24核心, 32线程(只能在16个能效核上进行超线程), L2: 32MB, L3: 36MB, 内存通信带宽 89.6GB/s
A100: 108 SM, 6912 CUDA core, 192KB L1, 60MB L2, 40GB DRAM.
我个人的理解, GPU的运算核心之所以远多于CPU, 是因为远少于CPU的控制逻辑. GPU每个core内不需要考虑线程调度的情况, 不需要保证严格一致的运算顺序, 另外每个sm都有自己独立的寄存器和L1, 对线程的切换重入非常友好, 所以更适合大规模数据的并行运算. 而这种设计方式也会对程序员提出更高的要求, 纯CPU程序可能写的最好的代码和最差的情况有个2/3倍的性能差距就很大了, 而CUDA kernel可能会相差几十倍甚至几百倍.
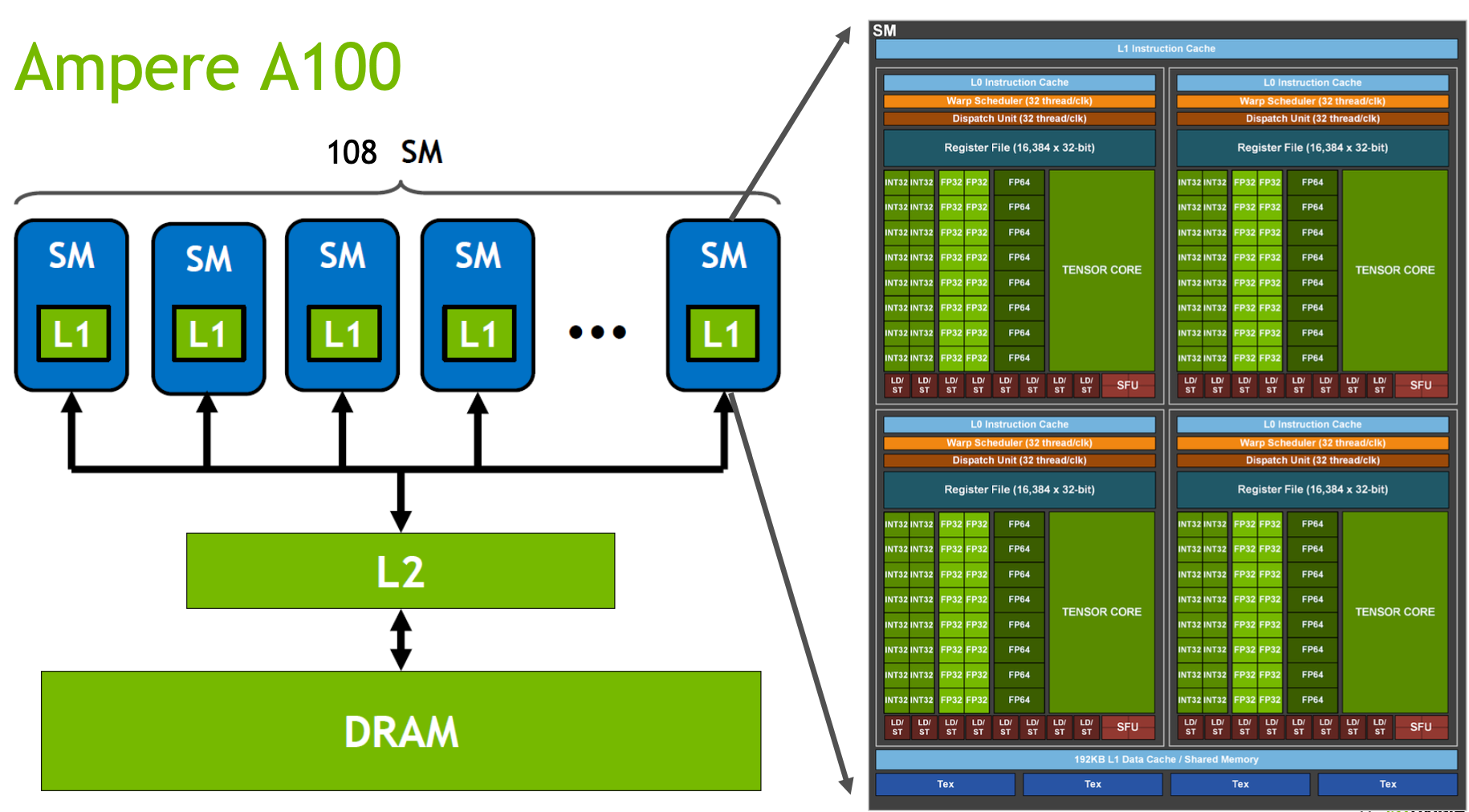
HBM(High-Bandwidth Memory) :HBM是高带宽内存,也就是常说的显存, 这张图里的DRAM。 带宽: 1.5TB/s
L2 Cache:L2 Cache是GPU中更大容量的高速缓存层,可以被多个SM访问。L2 Cache还可以用于协调SM之间的数据共享和通信。 带宽: 4TB/s
SM(Streaming Multiprocessor) :GPU的主要计算单元,负责执行并行计算任务。每个SM都包含多个CUDA core,也就是CUDA里Block执行的地方, 关于block_size如何设置可以参考block_size设置, 跟随硬件不同而改变, 通常为128/256
L1 Cache/SMEM:, 也叫shared_memory, 每个SM独享一个L1 Cache,CUDA里常用于单个Block内部的临时计算结果的存储, 比如cub里的Block系列方法就经常使用, 带宽: 19TB/s
SMP(SM partition): A100中有4个. 每个有自己的wrap调度器, 寄存器等.
CUDA Core: 图里绿色的FP32/FP64/INT32等就是, 是thread执行的基本单位
Tensor Core: Volta架构之后新增的单元, 主要用于矩阵运算的加速
WARP(Wavefront Parallelism) :WARP指的是一组同时执行的Thread,固定32个, 不够32时也会按32分配. wrap一个线程对内存操作后, 其他wrap内的线程是可见的.
Dispatch Unit: 从指令队列中获取和解码指令,协调指令的执行和调度
Register File: 寄存器用于存储临时数据、计算中间结果和变量。GPU的寄存器比CPU要多很多
2. cuda基础
cuda基础语法上和c/c++是一致的. 引入了host/device定义, host指的是cpu端, device指的是gpu端
个人感觉最难的部分在于并行的编程思想和cpu编程的思想差异比较大. 我们以一个向量相加的demo程序举例:
__global__ void add_kernel(int *a, int *b, int *c, int n) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
if (index < n) {
c[index] = a[index] + b[index];
}
}
int main() {
int *a, *b, *c;
int *d_a, *d_b, *d_c;
int n = 10000;
int size = n * sizeof(int);
cudaMalloc((void**)&d_a, size);
cudaMalloc((void**)&d_b, size);
cudaMalloc((void**)&d_c, size);
a = (int*)malloc(size);
random_ints(a, n);
b = (int*)malloc(size);
random_ints(b, n);
c = (int*)malloc(size);
cudaMemcpy(d_a, a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, size, cudaMemcpyHostToDevice);
//cuda kernel
add_kernel<<<(n + threads_per_block - 1)/threads_per_block, threads_per_block>>>(d_a, d_b, d_c, n);
cudaMemcpy(c, d_c, size, cudaMemcpyDeviceToHost);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}
描述符
cuda新增了三个描述符:
__global__: 在device上运行, 可以从host/device上调用, 返回值必须是void, 异步执行.
__device__: 在device上运行和调用
__host__: 只能在host上执行和调用
CUDA Kernel
cuda_kernel是由<<<>>>围起来的, 里面主要有4个参数用来配置这个kernel <<<grid_size, block_size, shared_mem_size, stream>>>
grid_size: 以一维block为例, grid_size计算以 (thread_num + block_size - 1) / block_size 计算大小
block_size: 见上面SM部分介绍
shared_mem_size: 如果按 __shared__ int a[] 方法声明共享内存, 需要在这里填需要分配的共享内存大小. 注意不能超过硬件限制, 比如A100 192KB
stream: 异步多流执行时的cuda操作队列, 在这个流上的所有kernel是串行执行的, 多个流之间是异步执行的. 后续会在异步章节里详细介绍
整个过程如下图, 先通过cudaMemcpy 把输入数据copy到显存->cpu提交kernel->gpu kernel_launch->结果写回线程->DeviceToHost copy回内存.
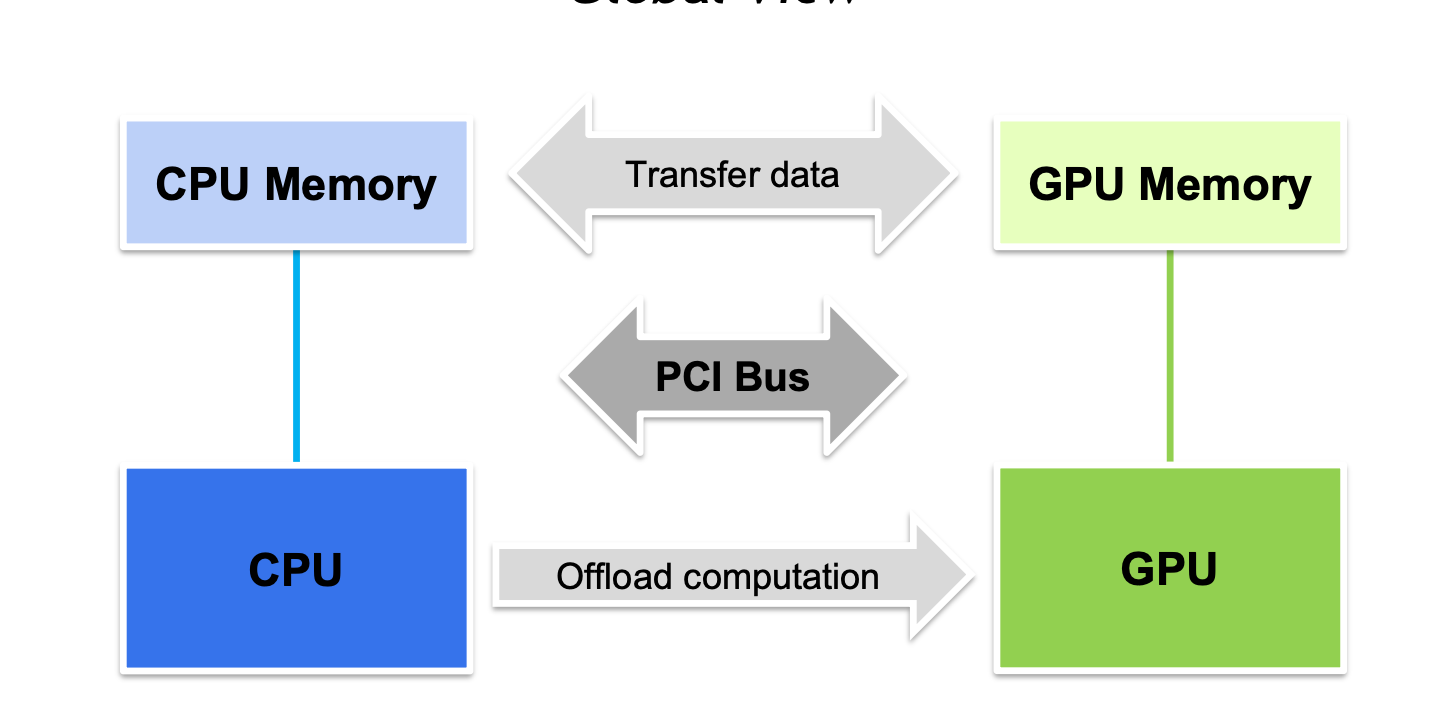
add_kernel 相当于我们将for循环拆分为了每个线程只处理一个元素的相加的并行执行. 通过nvcc编译后就完成了第一个kernel的编写. 下一篇会以一个具体的例子来讲如何进行kernel的性能分析和调优.
常用库
thrust: cuda中类似于c++ STL的定位, 一些类似于STL的常见算法可以在这里找到现成的实现, 比如sort/reduce/unique/random 等. 文档: https://nvidia.github.io/cccl/thrust/api/namespace_thrust.html
cudnn: 神经网络加速的常用库. 包含卷积/pooling/softmax/normalization 等常见op的优化实现.
cuBlas: 线性代数相关的库. 进行矩阵运算时可以考虑使用, 比如非常经典的矩阵乘法实现cublasSgemm
Cub: wrap/block/device级的编程组件, 非常常用. 文档: https://nvidia.github.io/cccl/cub/
nccl: 集合通信库. 用于卡间通信/多机通信
相关资料
cuda编程指导手册: https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#programming-model
性能分析工具Nsight-System & Nsight-Compute: https://docs.nvidia.com/nsight-systems/index.html
CUDA程序优化-1.基础介绍的更多相关文章
- 可分离滤波器设计高斯滤波 CUDA程序优化, 实验记录
环境:RTX2060 ,1920X1080p ,循环10次, kernal_size=8 一 .测试前128个线程拷贝到dst数据的性能 ,只测试行卷积, block=(128+2r)X1 1. 使 ...
- CUDA基础介绍
一.GPU简介 1985年8月20日ATi公司成立,同年10月ATi使用ASIC技术开发出了第一款图形芯片和图形卡,1992年4月ATi发布了Mach32图形卡集成了图形加速功能,1998年4月ATi ...
- php数据结构课程---1、数据结构基础介绍(程序是什么)
php数据结构课程---1.数据结构基础介绍(程序是什么) 一.总结 一句话总结: 程序=数据结构+算法 设计好数据结构,程序就等于成功了一半. 数据结构是程序设计的基石. 1.数据的逻辑结构和物理结 ...
- 【ABAP系列】SAP ABAP基础-程序优化及响应速度之LOOP
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[ABAP系列]SAP ABAP基础-程序优化及 ...
- Java 程序优化 (读书笔记)
--From : JAVA程序性能优化 (葛一鸣,清华大学出版社,2012/10第一版) 1. java性能调优概述 1.1 性能概述 程序性能: 执行速度,内存分配,启动时间, 负载承受能力. 性能 ...
- Linux基础介绍【第一篇】
Linux简介 什么是操作系统? 操作系统,英文名称Operating System,简称OS,是计算机系统中必不可少的基础系统软件,它是应用程序运行以及用户操作必备的基础环境支撑,是计算机系统的核心 ...
- 关于C#程序优化的五十种方法
关于C#程序优化的五十种方法 这篇文章主要介绍了C#程序优化的五十个需要注意的地方,使用c#开发的朋友可以看下 一.用属性代替可访问的字段 1..NET数据绑定只支持数据绑定,使用属性可以获 ...
- GPU 编程入门到精通(四)之 GPU 程序优化
博主因为工作其中的须要,開始学习 GPU 上面的编程,主要涉及到的是基于 GPU 的深度学习方面的知识,鉴于之前没有接触过 GPU 编程.因此在这里特地学习一下 GPU 上面的编程.有志同道合的小伙伴 ...
- 一步步做程序优化-讲一个用于OpenACC优化的程序(转载)
一步步做程序优化[1]讲一个用于OpenACC优化的程序 分析下A,B,C为三个矩阵,A为m*n维,B为n*k维,C为m*k维,用A和B来计算C,计算方法是:C = alpha*A*B + beta* ...
- professional cuda c programming--CUDA库简单介绍
CUDA Libraries简单介绍 上图是CUDA 库的位置.本文简要介绍cuSPARSE.cuBLAS.cuFFT和cuRAND.之后会介绍OpenACC. cuSPARSE线性代数库,主要针 ...
随机推荐
- [FAQ] jQuery prop 与 attr 的区别
.prop() 获取匹配的元素集中第一个元素的属性(property)值 或 设置每一个匹配元素的一个或多个属性. 当设置 selectedIndex, tagName, nodeName, node ...
- [FE] 被动检测 iframe 加载 src 成功失败的一种思路和方式 (Vue)
思路:设置定时器一个,n 秒后设置 404 或其它,此时给 iframe 的 onload 事件设置回调函数,加载完成则取消定时器. 示例: data () { return { handler: n ...
- MyBatis源码之MyBatis中SQL语句执行过程
MyBatis源码之MyBatis中SQL语句执行过程 SQL执行入口 我们在使用MyBatis编程时有两种方式: 方式一代码如下: SqlSession sqlSession = sqlSessio ...
- .NET CORE 完美支持AOT 的 ORM SqlSugar 教程
1.AOT适合产场 Aot适合工具类型的项目使用,优点禁止反编 ,第一次启动快,业务型项目或者反射多的项目不适合用AOT AOT更新记录: 实实在在经过实践的AOT ORM 5.1.4.117 +支持 ...
- Deepin安装Python3
https://www.jianshu.com/p/0c61bdfb9589 也可以看这篇,本文是这篇的简捷版,均原创 首先,把系统更到最新,并复制下面的代码 sudo apt update 更新软件 ...
- SATA与PCI-E速度对比
SATA SATA接口已经发展到了第三代,理论上的最大速度达到600MB/s.平时大家见到的SATA SSD使用的都是SATA三代,实际测试速度在550MB/s左右,这比普通的机械硬盘的速度100MB ...
- Teamviewer 再次涨价,太贵了,有没有平替软件?
今天打开 Teamviewer 网站,吓一跳,商业版基础款价格直接翻倍. 作为行业龙头,又是德国产品,Teamviewer 一直保持着高价格的特色.这两年 Teamviewer 的价格还逐年上涨,从每 ...
- Java面试题:线程池内“闹情绪”的线程,怎么办?
在Java中,线程池中工作线程出现异常的时候,默认会把异常往外抛,同时这个工作线程会因为异常而销毁,我们需要自己去处理对应的异常,异常处理的方法有几种: 在传递的任务中去处理异常,对于每个提交到线程池 ...
- Java学习之数据类型转换
package com.zhang.LectCode; public class 各种数据间的相互转换 { public static void main(String[] args) { //将St ...
- zabbix第二篇
常用命令 查看版本 [root@zabbix001 xx]# zabbix_server -V zabbix_server (Zabbix) 4.2.8 Revision cb5d5b10f4 28 ...