使用python在k8s中创建一个pod
要在Kubernetes (k8s) 中使用Python创建一个Pod,你可以使用Kubernetes Python客户端库(通常称为kubernetes或kubernetes-client)。以下是一个简单的步骤和示例代码,说明如何使用Python在Kubernetes集群中创建一个Pod。
步骤
两种方式
在pycharm中创建pod
- 添加k8s模块
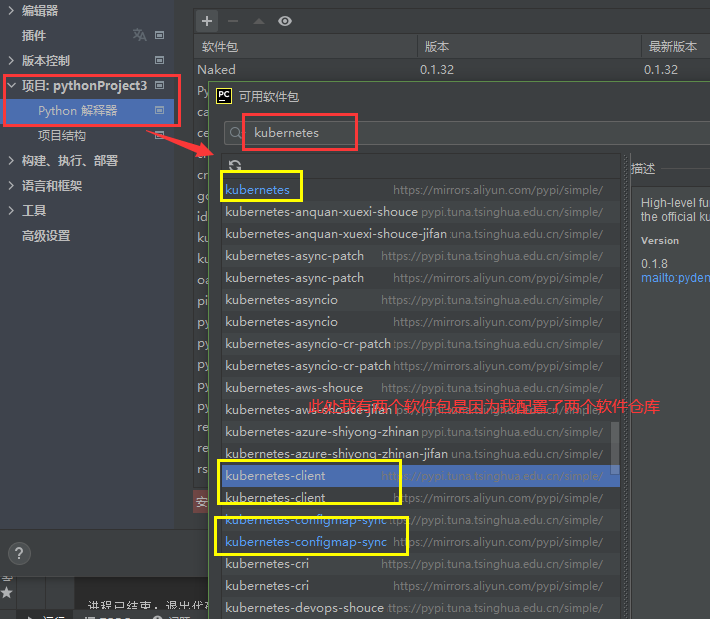
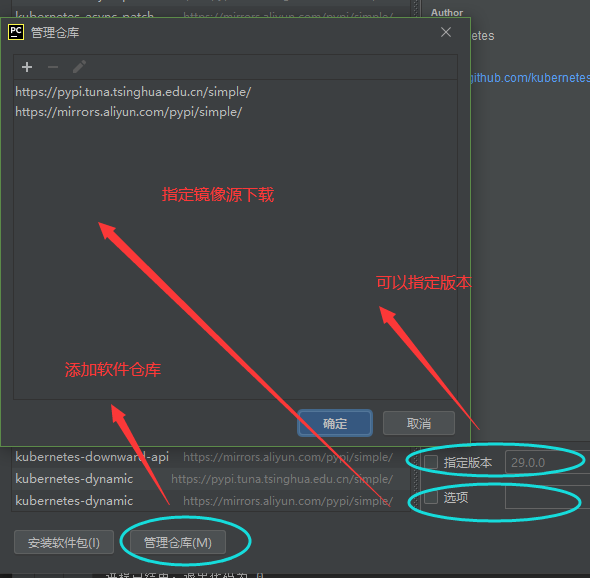
用国内的仓库源可以加快python下载包的速度,国内源如下:
阿里云 https://mirrors.aliyun.com/pypi/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
豆瓣(douban) https://pypi.douban.com/simple/
中国科学技术大学 https://pypi.mirrors.ustc.edu.cn/simple/
from kubernetes import client, config
from kubernetes.client.rest import ApiException
config.load_kube_config(r'C:\Users\4407\Desktop\config')
# 反斜杠\是一个转义字符。**在字符串前加上r**,这样Python就不会解释反斜杠为转义字符了
# **使用双反斜杠**,将每个单反斜杠替换为双反斜杠。
# 使用**正斜杠**:在Windows中也可以使用正斜杠(尽管它们通常用于Unix和Linux系统),Python会理解它们为路径分隔符。
pod_manifest = {
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"name": "my-pod",
"labels": {
"app": "my-app"
}
},
"spec": {
"containers": [
{
"name": "my-container",
"image": "nginx:1.19.1",
"ports": [
{"containerPort": 80}
]
}
]
}
}
# api_instance = client.CoreV1Api()
v1 = client.CoreV1Api()
resp = v1.create_namespaced_pod(body=pod_manifest, namespace='default')
print("Pod created. status='%s'" % str(resp.status))
在k8s集群中使用python创建pod
- 安装python3 pip3 并且加载 Kubernetes 模块
使用pip安装:
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple kubernetes
pip3 install --upgrade pip
- 获取Kubernetes集群的访问凭据
你可能需要配置Kubernetes集群的访问凭据。这通常是通过设置环境变量(如KUBECONFIG)或使用~/.kube/config文件来完成的。
3. 编写Python代码来创建Pod
使用Kubernetes Python客户端库来定义Pod并发送到Kubernetes API服务器。
示例代码
以下是一个简单的Python脚本,用于在Kubernetes集群中创建一个Pod:
[root@master python]# cat pod.py
#!/usr/bin/python3
from kubernetes import client, config, watch
from kubernetes.client.rest import ApiException
config.load_kube_config()
pod_manifest = {
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"name": "my-pod",
"labels": {
"app": "my-app"
}
},
"spec": {
"containers": [
{
"name": "my-container",
"image": "nginx:1.19.1",
"ports": [
{"containerPort": 80}
]
}
]
}
}
#api_instance = client.CoreV1Api()
v1 = client.CoreV1Api()
resp = v1.create_namespaced_pod(body=pod_manifest, namespace='default')
print("Pod created. status='%s'" % str(resp.status))
运行此脚本将在Kubernetes集群的默认命名空间中创建一个名为“my-pod”的Pod,该Pod运行“nginx:1.19.1”镜像。你可以根据需要修改Pod的规格和命名空间。
详细解释上面代码
当然可以,以下是对您提供的 pod.py Python 脚本的详细解释:
- Shebang:
#!/usr/bin/python3
这一行是 shebang(也称为 hashbang 或 hashbang line)。它告诉系统应该使用哪个解释器来执行这个脚本。在这里,它指定了使用 /usr/bin/python3 作为解释器,即 Python 3。
- 导入必要的库:
from kubernetes import client, config, watch
from kubernetes.client.rest import ApiException
这里从 kubernetes 包中导入了三个模块:client、config 和 watch。同时,还从 kubernetes.client.rest 中导入了 ApiException,这是 Kubernetes Python 客户端库中的一个异常类,用于处理与 Kubernetes API 交互时可能出现的错误。
- 加载 Kubernetes 配置:
config.load_kube_config()
这一行代码调用了 config.load_kube_config() 方法,它会加载 Kubernetes 的配置文件(通常是 ~/.kube/config),以便脚本能够与 Kubernetes 集群进行交互。
- 定义 Pod 清单:
pod_manifest = {
"apiVersion": "v1",
"kind": "Pod",
# ... 其他字段 ...
}
这里定义了一个 Python 字典 pod_manifest,它描述了要创建的 Pod 的属性和配置。这个字典遵循 Kubernetes 的 API 规范,用于定义 Pod 的各种属性,如名称、标签、容器配置等。
- 创建 Pod:
v1 = client.CoreV1Api()
resp = v1.create_namespaced_pod(body=pod_manifest, namespace='default')
首先,创建了一个 CoreV1Api 的实例 v1,它是 Kubernetes Python 客户端库中的一个类,用于与 Kubernetes API 的核心 v1 版本进行交互。
然后,调用了 v1.create_namespaced_pod() 方法来在指定的命名空间(在这个例子中是 'default')中创建一个新的 Pod。这个方法需要两个参数:body 和 namespace。body 参数是一个包含 Pod 定义的字典(在这里是 pod_manifest),而 namespace 参数指定了要在哪个命名空间中创建 Pod。
create_namespaced_pod() 方法返回一个响应对象 resp,该对象包含了关于创建的 Pod 的信息。
- 打印 Pod 创建状态:
print("Pod created. status='%s'" % str(resp.status))
最后,这一行代码打印出 Pod 创建的状态。然而,这里有一点需要注意:resp.status 可能不是直接包含 Pod 状态的字段。通常,Kubernetes API 的响应包含一个状态码(例如 HTTP 201 表示成功创建)和一个包含 Pod 详细信息的对象。如果想要打印 Pod 的实际状态(如 Running、Pending 等),可能需要从响应对象中提取更多信息。
使用
- 运行脚本
[root@master python]# python3 pod.py
//此处不可用python,会报错,因为脚本中指定了python3
- 查看Pod状态:
[root@master python]# kubectl get po
NAME READY STATUS RESTARTS AGE
my-pod 1/1 Running 0 29m
总结
为了独立写出上面的代码,需要掌握Python的一些基本概念和库的使用。
关键点和技能:
Python基础知识:
- 变量和数据类型(如字典、列表、字符串等)
- 控制流(条件语句、循环语句)
- 函数定义和调用
- 导入模块和库
Python字典:
- 字典的创建
- 字典的访问和修改
- 字典的嵌套
Python异常处理:
try-except语句的使用- 捕获和处理特定类型的异常(如上面的
ApiException)
Python第三方库的安装和使用:
- 使用
pip命令安装库(如kubernetes) - 导入和使用第三方库中的类和函数
- 使用
Kubernetes基本概念:
- 了解Kubernetes集群的组成(如Master节点、Worker节点)
- 理解Pod、容器、命名空间等Kubernetes资源
- 了解Kubernetes API的基本操作和用途
Kubernetes Python客户端库的使用:
- 加载Kubernetes集群配置(如使用
load_kube_config()) - 创建和配置Kubernetes资源对象(如
V1Pod) - 调用Kubernetes API进行资源的创建、读取、更新和删除操作
- 加载Kubernetes集群配置(如使用
JSON或YAML到Python对象的转换:
- 虽然上面的示例中直接使用了Python字典来定义Pod规格,但通常Kubernetes资源配置文件是以YAML或JSON格式编写的。因此,了解如何将YAML或JSON文件解析为Python对象(如使用
PyYAML或json库)也是很重要的。
- 虽然上面的示例中直接使用了Python字典来定义Pod规格,但通常Kubernetes资源配置文件是以YAML或JSON格式编写的。因此,了解如何将YAML或JSON文件解析为Python对象(如使用
错误处理和日志记录:
- 在实际代码中,您可能需要添加更详细的错误处理和日志记录功能,以便在出现问题时能够更快地定位和解决问题。
文档和社区支持:
- 阅读Kubernetes和Kubernetes Python客户端库的官方文档
- 搜索和参与相关的社区讨论和问答,以获取帮助和解决方案
版本管理:
- 了解如何使用版本控制工具(如Git)来管理您的代码和配置文件
通过学习和实践上述技能和知识点,您将能够独立地编写出类似上面的Python脚本来与Kubernetes集群进行交互。
参数详解
config.load_kube_config() 是 Kubernetes Python 客户端库中的一个函数,用于加载 Kubernetes 的配置信息,以便 Python 脚本能够与 Kubernetes 集群进行交互。这个函数在大多数情况下不需要任何参数,因为它会默认从用户的家目录下的 .kube/config 文件中加载配置。
不过,为了更全面地解释 config.load_kube_config(),我们可以考虑一些可能的参数(尽管在标准的 Kubernetes Python 客户端库中这个函数通常不接受任何参数):
默认的参数和行为
无参数:当你不给
load_kube_config()提供任何参数时,它会尝试从默认的 kubeconfig 路径(通常是~/.kube/config)加载配置。加载上下文:kubeconfig 文件可能包含多个集群、用户和上下文(contexts)。默认情况下,它会加载当前上下文(current-context),这个上下文定义了应该使用哪个集群和用户凭据。
可能的参数(取决于具体实现)
虽然标准的 Kubernetes Python 客户端库中的 load_kube_config() 函数通常不接受参数,但某些扩展或修改版可能允许你传递额外的参数。这些参数可能包括:
- kubeconfig 文件的路径:允许你指定一个非默认的 kubeconfig 文件路径。
- 上下文名称:允许你指定一个特定的上下文来加载,而不是默认的当前上下文。
- 用户代理:允许你设置用于 HTTP 请求的用户代理字符串。
- 其他认证选项:在某些情况下,可能允许你通过参数直接提供认证凭据(如令牌、证书等),而不是从 kubeconfig 文件中加载。
实际使用中的注意事项
- 权限:加载 kubeconfig 文件需要适当的文件系统权限。如果脚本没有足够的权限来读取该文件,
load_kube_config()将会失败。 - 上下文:确保 kubeconfig 文件中的当前上下文是你想要与之交互的 Kubernetes 集群的正确上下文。如果需要,你可以使用
kubectl config命令来修改或设置当前上下文。 - 环境变量:在某些情况下,环境变量(如
KUBECONFIG)可能会影响 kubeconfig 文件的加载行为。确保这些环境变量被正确设置,以符合你的需求。 - 错误处理:在调用
load_kube_config()时,最好包含适当的错误处理逻辑,以便在加载配置失败时能够优雅地处理错误。
总结:
config.load_kube_config() 是 Kubernetes Python 客户端库中用于加载 Kubernetes 配置的关键函数。通过加载 kubeconfig 文件,Python 脚本可以获得与 Kubernetes 集群进行交互所需的认证信息和集群信息。
原理
使用Python创建Kubernetes Pod的原理主要涉及以下几个步骤和概念:
Kubernetes API:
Kubernetes提供了一个RESTful API,允许用户通过HTTP请求与集群进行交互。这个API支持对集群中的资源(如Pod、Service、Deployment等)进行增删改查等操作。Kubernetes Python客户端库:
为了简化与Kubernetes API的交互,开发者们创建了多种语言的客户端库,包括Python。这些库封装了底层的HTTP请求,使得开发者可以使用更高级别的API来操作Kubernetes资源。在Python中,kubernetes客户端库就是这样一个工具。认证和授权:
在与Kubernetes API交互之前,你需要提供适当的认证凭据,以证明你有权限执行所请求的操作。这通常通过Kubernetes的配置文件(通常是~/.kube/config)或环境变量来完成。这些凭据可以是API令牌、客户端证书等。定义Pod规格:
在创建Pod之前,你需要定义Pod的规格(Specification)。这通常是一个包含Pod元数据和配置信息的字典或对象。规格中指定了Pod的名称、命名空间、容器列表(每个容器有名称、镜像、端口等配置)、存储需求等。使用Python客户端库发送请求:
一旦你有了Pod的规格和适当的认证凭据,你就可以使用Kubernetes Python客户端库来发送HTTP请求到Kubernetes API服务器。这个请求告诉Kubernetes API服务器你想要创建一个新的Pod,并提供了Pod的规格作为请求体。Kubernetes API服务器处理请求:
当Kubernetes API服务器接收到你的请求时,它会验证你的认证凭据和请求的有效性。如果一切正常,API服务器就会根据你提供的Pod规格在集群中创建一个新的Pod。这通常涉及调度Pod到合适的节点上,并在该节点上启动Pod中的容器。监视Pod的状态:
一旦Pod被创建,你可以继续使用Kubernetes API(和Python客户端库)来监视Pod的状态。例如,你可以检查Pod是否已经被调度到某个节点上,或者容器是否已经启动并正在运行。
总的来说,使用Python创建Kubernetes Pod的原理就是通过Kubernetes API与集群进行交互,并使用Python客户端库来发送包含Pod规格的请求到API服务器。API服务器处理这些请求,并在集群中创建和管理Pod。
帮助文档
考试要求 创建pod,deployment,job(开发)
1.安装Openstack框架
模糊查询软件包名称
[root@controller ~]# yum list *-openstack-train
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
- base: mirrors.aliyun.com
- extras: mirrors.aliyun.com
- updates: mirrors.aliyun.com
Available Packages
centos-release-openstack-train.noarch 1-1.el7.centos extras
安装
[root@controller ~]# yum -y install centos-release-openstack-train
2.升级所有的软件包
自动检查所有可升级的软件包并升级
[root@controller ~]# yum upgrade -y
3.安装openstack客户端
[root@controller ~]# yum install -y python-openstackclient
4.查看openstack的版本号
[root@controller ~]# openstack --version
openstack 4.0.2
1.上传openStack-train.iso文件到/opt目录下
[root@controller opt]# du -sh *
0 mydriver
16G openStack-train.iso
2.将镜像文件挂载到文件夹中,即可访问镜像文件内容
[root@controller opt]# mkdir openstack
[root@controller opt]# ls
mydriver openstack openStack-train.iso
挂载命令:将镜像文件挂载到/opt/openstack
[root@controller opt]# mount openStack-train.iso openstack/
mount: /dev/loop0 is write-protected, mounting read-only
[root@controller opt]# df -H
...略
/dev/loop0 17G 17G 0 100% /opt/openstack
3.备份原有的yum的配置文件
[root@controller openstack]# cd /etc/yum.repos.d/
[root@controller yum.repos.d]# ls
CentOS-Base.repo CentOS-OpenStack-train.repo repo.bak
将阿里源改名,避免覆盖官方源备份
[root@controller yum.repos.d]# mv CentOS-Base.repo CentOS-ALIBABA-Base.repo
移动repo文件到备份目录
[root@controller yum.repos.d]# mv *.repo repo.bak/
4.编写本地YUM源文件,指向本地文件
[root@controller yum.repos.d]# vi OpenStack.repo
[base]
name=base
baseurl=file:///opt/openstack/base/
enable=1
gpgcheck=0
[extras]
name=extras
baseurl=file:///opt/openstack/extras/
enable=1
gpgcheck=0
[updates]
name=updates
baseurl=file:///opt/openstack/updates/
enable=1
gpgcheck=0
[train]
name=train
baseurl=file:///opt/openstack/train/
enable=1
gpgcheck=0
[virt]
name=virt
baseurl=file:///opt/openstack/virt/
enable=1
gpgcheck=0
5.清除原有的YUM源缓存并重建缓存
[root@controller ~]# yum clean all
重建缓存
[root@controller ~]# yum makecache
检查yum源
[root@controller ~]# yum repolist
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
repo id repo name status
base base 10,039
extras extras 500
train train 3,168
updates updates 3,182
virt virt 63
repolist: 16,952
长期挂载,避免重启丢失
[root@controller ~]# vi /etc/fstab
在最后添加如下内容
/opt/openStack-train.iso /opt/openstack/ iso9660 defaults,loop 0 0
使用python在k8s中创建一个pod的更多相关文章
- 【Kubernetes】在K8s中创建StatefulSet
在K8s中创建StatefulSet 遇到的问题: 使用Deployment创建的Pod是无状态的,当挂在Volume之后,如果该Pod挂了,Replication Controller会再run一个 ...
- 在K8s中创建StatefulSet
在K8s中创建StatefulSet 遇到的问题: 使用Deployment创建的Pod是无状态的,当挂在Volume之后,如果该Pod挂了,Replication Controller会再run一个 ...
- kubenetes创建一个pod应用
Pod是可以创建和管理Kubernetes计算的最小可部署单元.一个Pod代表着集群中运行的一个进程.每个pod都有一个唯一的ip. 一个pod类似一个豌豆荚,包含一个或多个容器(通常是docker) ...
- 创建一个目录info,并在目录中创建一个文件test.txt,把该文件的信息读取出来,并显示出来
/*4.创建一个目录info,并在目录中创建一个文件test.txt,把该文件的信息读取出来,并显示出来*/ #import <Foundation/Foundation.h>#defin ...
- Ionic 2 中创建一个照片倾斜浏览组件
内容简介 今天介绍一个新的UI元素,就是当我们改变设备的方向时,我们可以看到照片的不同部分,有一种身临其境的感觉,类似于360全景视图在移动设备上的应用. 倾斜照片浏览 Ionic 2 实例开发 新增 ...
- iOS9中如何在日历App中创建一个任意时间之前开始的提醒(三)
大熊猫猪·侯佩原创或翻译作品.欢迎转载,转载请注明出处. 如果觉得写的不好请多提意见,如果觉得不错请多多支持点赞.谢谢! hopy ;) 四.创建任意时间之前开始的提醒 现在我们找到了指定源中的指定日 ...
- 在C#/.NET应用程序开发中创建一个基于Topshelf的应用程序守护进程(服务)
本文首发于:码友网--一个专注.NET/.NET Core开发的编程爱好者社区. 文章目录 C#/.NET基于Topshelf创建Windows服务的系列文章目录: C#/.NET基于Topshelf ...
- Eclipse中创建一个新的SpringBoot项目
在Eclipse中创建一个新的spring Boot项目: 1. 首先在Eclipse中安装STS插件:在Eclipse主窗口中点击 Help -> Eclipse Marketplace... ...
- 在存放源程序的文件夹中建立一个子文件夹 myPackage。例如,在“D:\java”文件夹之中创建一个与包同名的子文件夹 myPackage(D:\java\myPackage)。在 myPackage 包中创建一个YMD类,该类具有计算今年的年份、可以输出一个带有年月日的字符串的功能。设计程序SY31.java,给定某人姓名和出生日期,计算该人年龄,并输出该人姓名、年龄、出生日期。程序使用YM
题目补充: 在存放源程序的文件夹中建立一个子文件夹 myPackage.例如,在“D:\java”文件夹之中创建一个与包同名的子文件夹 myPackage(D:\java\myPackage).在 m ...
- 父类是在子类创建对象时候 在子类中创建一个super内存空间
父类是在子类创建对象时候 在子类中创建一个super内存空间
随机推荐
- GaussDB(DWS)基于Flink的实时数仓构建
本文分享自华为云社区<GaussDB(DWS)基于Flink的实时数仓构建>,作者:胡辣汤. 大数据时代,厂商对实时数据分析的诉求越来越强烈,数据分析时效从T+1时效趋向于T+0时效,为了 ...
- 力扣620(MySQL)-有趣的电影(简单)
题目: 某城市开了一家新的电影院,吸引了很多人过来看电影.该电影院特别注意用户体验,专门有个 LED显示板做电影推荐,上面公布着影评和相关电影描述. 作为该电影院的信息部主管,您需要编写一个 SQL查 ...
- 力扣511(MySQL)-游戏玩法分析Ⅰ(简单)
题目: 活动表 Activity: 写一条 SQL 查询语句获取每位玩家 第一次登陆平台的日期. 查询结果的格式如下所示: 解题思路: 方法一:使用dense_rank() over(partiti ...
- OpenSergo 流量路由:从场景到标准化的探索
简介: 本文我们将从流量路由这个场景入手,从常见的微服务治理场景出发.先是根据流量路由的实践设计流量路由的 Spec,同时在 Spring Cloud Alibaba 中实践遵循 OpenSergo ...
- 科普达人丨一图看懂块存储&云盘
简介: 建议收藏 原文链接:https://click.aliyun.com/m/1000363155/ 本文为阿里云原创内容,未经允许不得转载.
- 如何定位并修复 HttpCore5 中的 HTTP2 流量控制问题
简介:开篇吹一波阿里云性能测试服务 PTS,PTS 在 2021 年 5 月份已经上线了对 HTTP2 协议的支持(底层依赖 httpclient5),在压测时会通过与服务端协商的结果来决定使用 H ...
- Vite + React 组件开发实践
简介: 毫不夸张的说,Vite 给前端带来的绝对是一次革命性的变化.或者也可以说是 Vite 背后整合的 esbuild . Browser es modules.HMR.Pre-Bundling 等 ...
- [FAQ] pdf 无法导入 adobe AI, 分辨率 or 颜色缺失 or 字体缺失
属于Adoge软件不支持问题, 可能是分辨率.字体等多种原因. https://www.codebye.com/adobe-reader-or-acrobat-opens-pdf-file-drawi ...
- netcore依赖注入通过反射简化
aspnetcore里面用到许多的service,好多业务代码都要通过Service.AddScoped.Singleton.Transient等注入进去,类太多了写起来和管理起来都很麻烦,所以借鉴了 ...
- Flink Forward #Asia2020 流批一体及数仓资料整理
阿里云实时计算负责人 - 王峰(莫问)/ FFA_2020-Flink as a Unified Engine - Now and Next-V4 2020年Flink 基于Flink 的流批一体数仓 ...