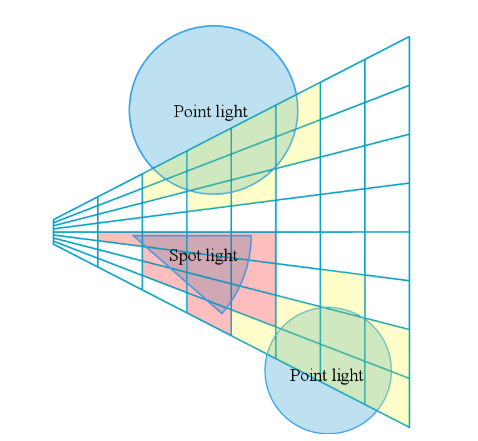
多光源渲染方案 - Light Culling
一般在计算 fragment 的 direct lighting 时,需要遍历所有光源并累加每个光源的贡献。然而当场景含有大量光源时,这种粗暴的遍历所有光源会导致巨大的性能开销(即便是擅长处理多光源的 deferred shading,每个像素都要遍历全局光源列表仍然是耗时的),这时候才需要 light culling 来剔除掉大量不会造成贡献的无关光源。
Tile-based Light Culling
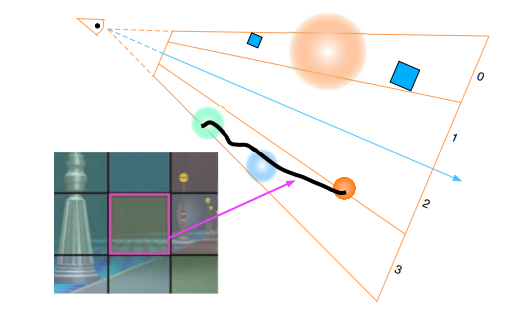
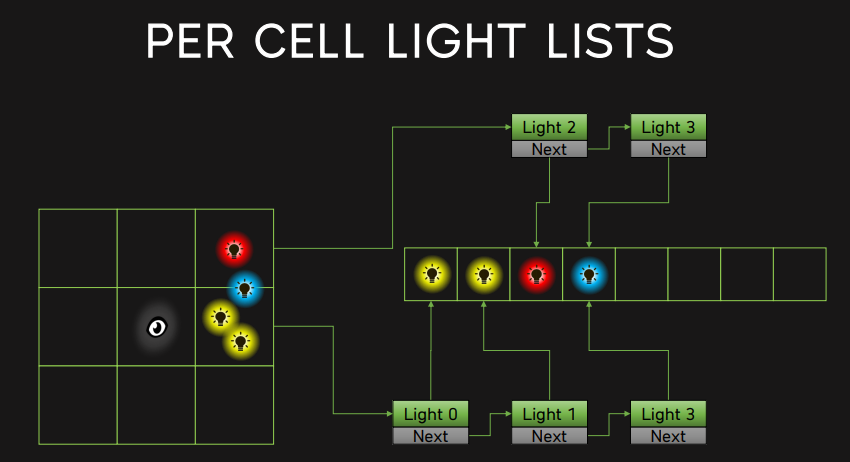
Tiled-based Light Culling 将屏幕区分划分为多个 tile ,且每个 tile 拥有⼀个光源列表(包含所有在该 tile 内有影响的光源)。这样就可以在对某个 fragment 着色时,算出该 fragment 所在的 tile,就能找到 tile 对应的光源列表,并对列表里的光源进行光照贡献计算,而不必对整个场景的所有光源进行光照贡献计算。
每个 tile 覆盖的区域为 32×32 pixels ,也可以是别的分辨率。
不过,当摄像机(或者光源)位置和方向发生改变,所有 tile 都需要重新计算其光源列表。
Tiled-based Light Culling 优缺点 :
[√] 减少了相当部分的无关光源的计算。
[×] 基于屏幕空间的 tile 划分仍然粗糙,没有考虑到深度值(离摄像机远近的距离)划分。
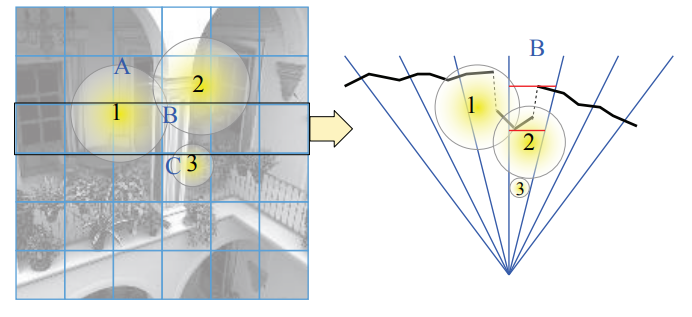
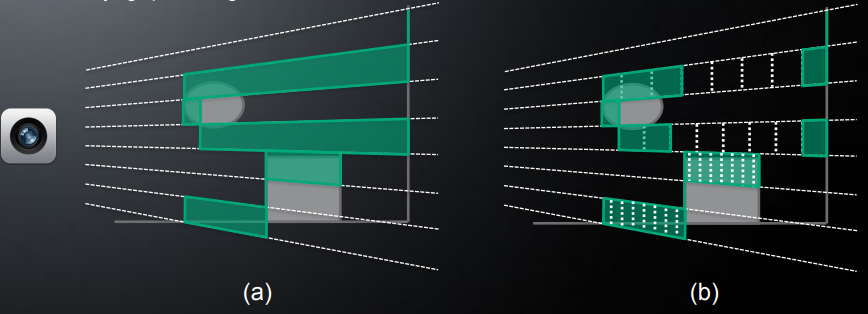
如下图黑色线段物体,每个 shading point 本应该最多同时受到一个光源的影响,由于 tile 划分没有考虑 z 值,从而使得实际每个 shading point 都有三个光源的着色计算:
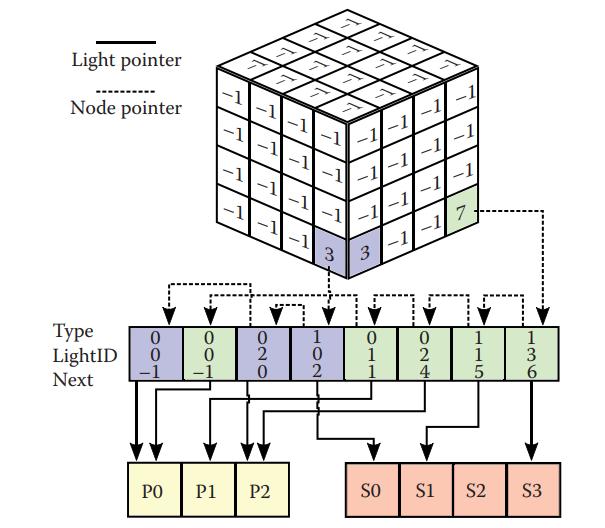
Tiled-based Light Culling 数据结构 :
- GlobalLightList:存储着各光源的属性(如 radiant intensty 等)
- TileLightIndexBuffer:存储着各 tile 对应的光源 ID 列表,以数组的形式拼接在一起
- TileBuffer:某个 tile 的光源 ID 列表位于 tile 光源索引列表的哪里到哪里(数组中下标多少到多少)
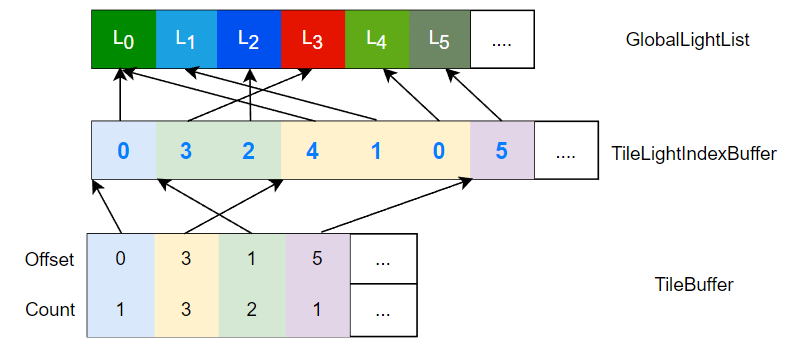
我们要做的,便是想办法建立并填充这个数据结构,以便在后续的着色流程使用(例如可以在 pixel shader 中判断自己在哪个 tile 然后访问 tile 对应的光源列表来 cull 掉大量光源)。
Culling 流程
一种最常见的实现方式便是基于 linked list,通常包含两个 compute shader pass:injection pass 和 compact pass。
Injection Pass
Injection Pass - compute shader(per Tile):
首先,构造出 tile 对应的包围盒,并且分别对所有光源包围盒进行相交测试,并将通过测试的光源添加进 tile 对应的 Tile Linked List。
// tile包围盒:根据 tile 的 depth range(所覆盖像素里的 min/max depth)构造出的 frustum 形状
tileBoundingBox = ConstructBoundingBox(tile.pos, tile.minDepth, tile.maxDepth)
foreach light in lights
// 光源包围盒:可以采用光源影响范围本身的形状,例如 point light 是球形,spot light 是圆锥形
lightBoundBox = light.boundingBox
if lightBoundBox intersects tileBoundingBox
Add light.Index to TileLinkedList
而在 compute shader 实现 Linked List,需要一些技巧:
- 使用 Global Linked List(实际上是一个预分配好的 buffer)来实际存储所有 links,并通过
GlobalLinkedListLast来指向 buffer 里最后一个 link。 TileLinkedListLast指向对应 tile 的 linked list 的最后一个 link,link 的 prev 属性只会指向同一 tile 的前一个 link,这样就可以保证各个 tile 对应的 tile linked list 各自独立。
GlobalLinkedListLast和TileLinkedListLast这种需要跨线程乃至跨线程组来共享的全局变量,一般用RWByteAddressBuffer来存储,这样 compute shader 的各个线程都能访问这个 RWByteAddressBuffer ,从而来对这个共享的全局变量进行读写。
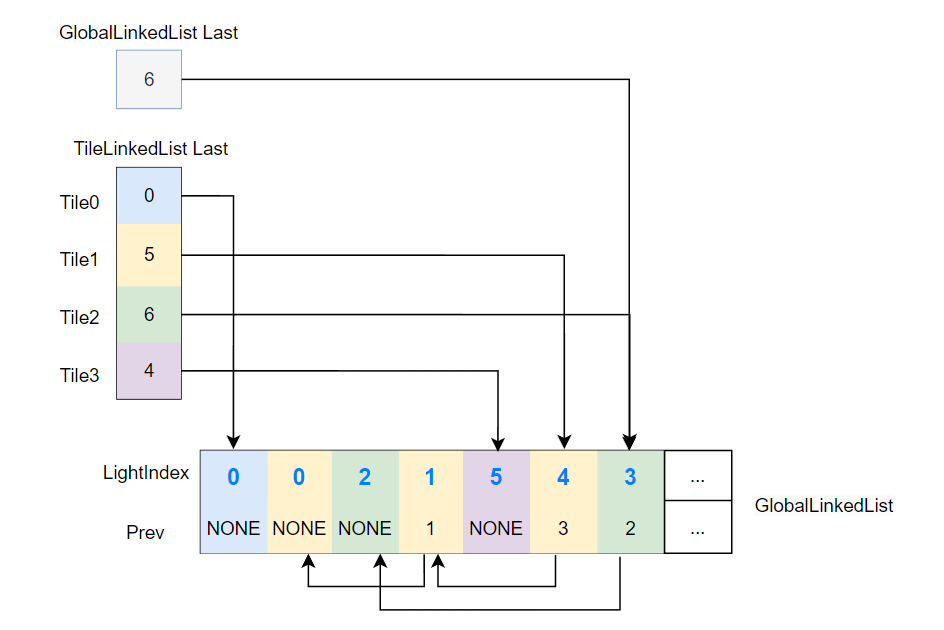
也就是说将 lightIndex 添加进 Tile Linked List 实际上在做的是:
// 从 Global Linked List 分配一个 link 的空间
nextLink = 0
InterlockedAdd(GlobalLinkedListLast, 1, nextLink)
// 拿到 Tile Linked List 的最后一个 link
previousLink = 0
InterlockedExchange(TileLinkedListLast[tile.pos], nextLink, previousLink)
// 写入 link
GlobalLinkedList[nextLink].lightIndex = light.Index
GlobalLinkedList[nextLink].prevLink = previousLink
经过 injection pass 后,虽然有了同样记录 light index 的 linked list 数据结构,但是在后续的 shading 流程中,要是直接遍历这些 linked list 会带来以下缺点:
- 占用空间多:一半的空间用于存放 prev
- 极度 cache 不友好:linked list 跳跃式的遍历 link 导致 cache 命中极低
因此,我们最好增加一个 compact pass 用于 compact(紧凑)一下 linked list 成章节开头的 TileLightIndexBuffer 和 TileBuffer 数据结构。
Compact Pass
Compact Pass - compute shader(per Tile):
首先,遍历 Tile Linked List,统计该 tile 的光源数量。
tileLightCount = 0
foreach link in TileLinkedList
tileLightCount++
而遍历 tile 对应的 Tile Linked List 的伪代码如下:
link = TileLinkedListLast[tile.pos]
while link != NONE
do something with link
link = GlobalLinkedList[link].prevLink
接着,对 GlobalTileLightIndexCount 进行加法原子操作来实现占位,并记录 tile 在 TileLightIndexBuffer 的 offset。
GlobalTileLightIndexCount也是跨线程共享的全局变量。
// 占位
tileLightOffset = 0;
InterlockedAdd(GlobalTileLightIndexCount, tileLightCount, tileLightOffset)
// 记录 count 和 offset
TileBuffer[tile.pos].count = tileLightCount
TileBuffer[tile.pos].offset = tileLightOffset
再次遍历 Tile Linked List,在占好的位写入通过测试的光源 ID 就完事了。
nodeCount = 0
foreach node in TileLinkedList
TileLightIndexBuffer[tileLightOffset + tileLightCount - nodeCount - 1] = node.lightIndex
nodeCount++
2.5D Culling
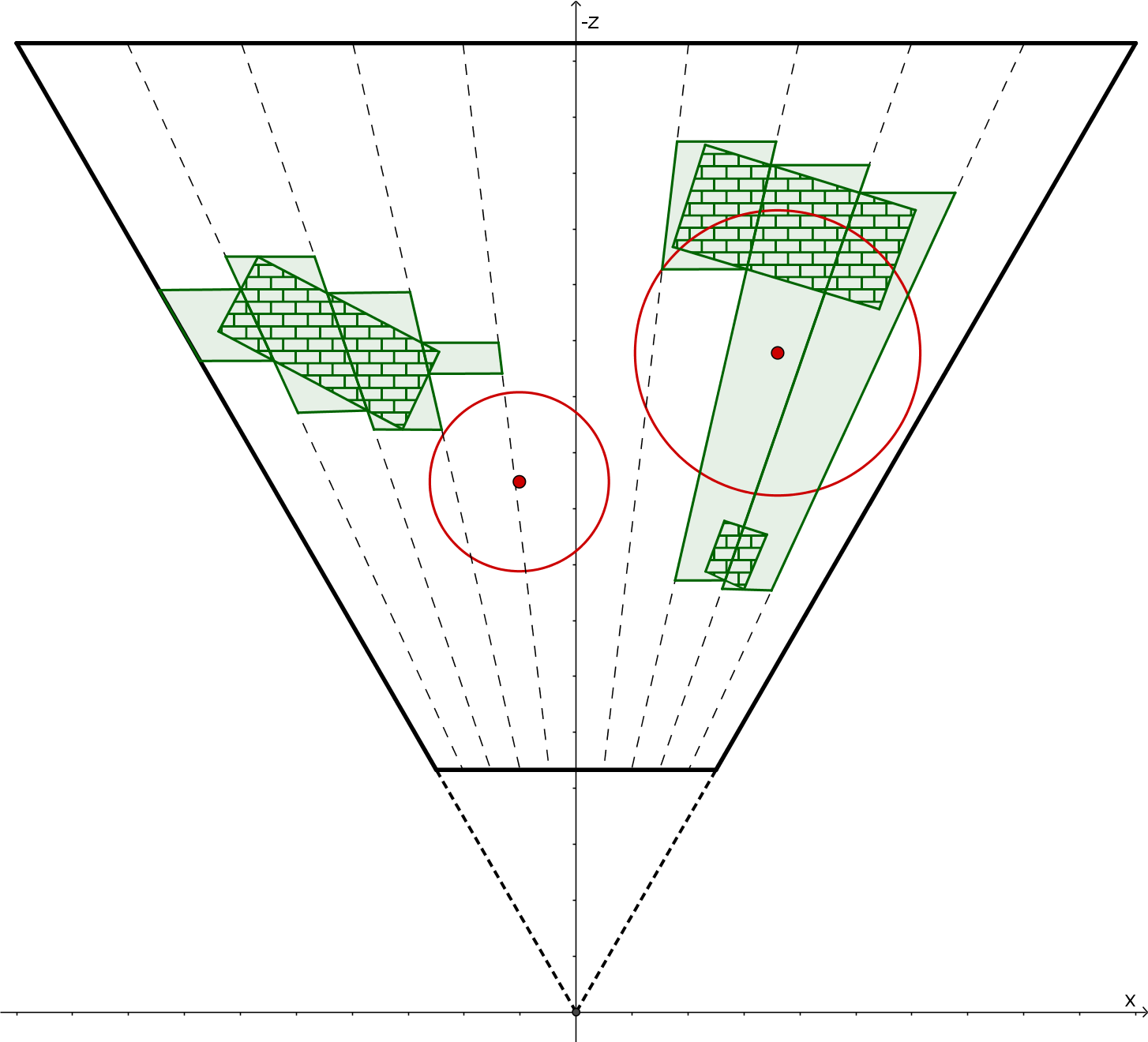
传统的 tile 包围盒只是简单通过 tile 的 min/max depth 来确定包围盒,这会导致包围盒包含了很多空腔区(即实际上没有表面 pixel 的地方),这样光源仅影响到空腔区的情况下,仍然会判定与该 tile 相交。
2.5D culling ≠ cluster-based culling,因为 2.5D 仍然是基于 tile 为单位的,只是剔除了一部分空腔区。
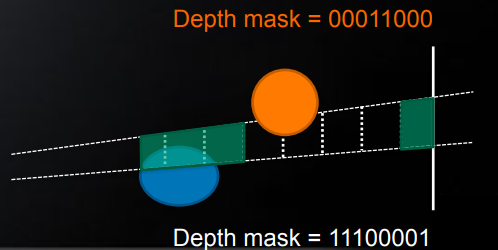
一个改进的做法就是,在 depth 上进行区域划分,然后根据 tile 内每个像素的 depth 来确定覆盖了哪些区域,并通过 depth mask 来编码。

在做光源与 tile 的相交检测时,光源也同样可以根据光源范围来编码成 depth mask,然后将测试的结果即为 \((\mathrm{depthmask_{tile}}\ \&\ \mathrm{depthmask_{light}})!=0\)
2.5D culling 效果图:
这种 tile-based culling 的改进思路虽然看着很直觉也很简单,然而带来的 culling 效率提升却是不小的,尤其是对于植被的渲染(往往空腔区特别多)。

Cluster-based Light Culling
为了进⼀步剔除光源数量,cluster-based 在 tile-based 的基础上,将像素分组的划分从 2D 的屏幕空间扩展到 3D 的观察空间。
每个 3D 的块称为⼀个 cluster,从而使每个光源真正做到仅影响其局部区域:
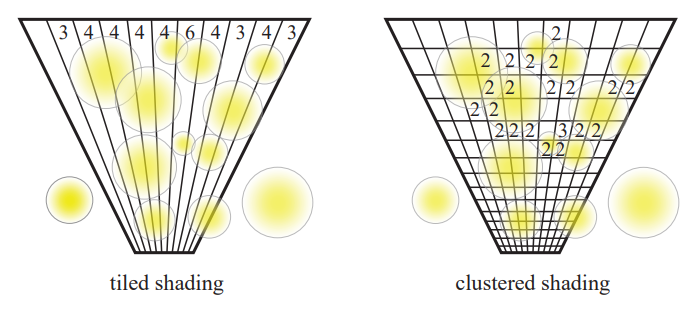
由于摄像机的透视投影,对于同样大小的物体,较远物体在屏幕上所占的空间更小;因此每个 cluster 不应该是均匀划分的,而是在深度方向上以指数形式划分(即更远处的 cluster 体积更大)
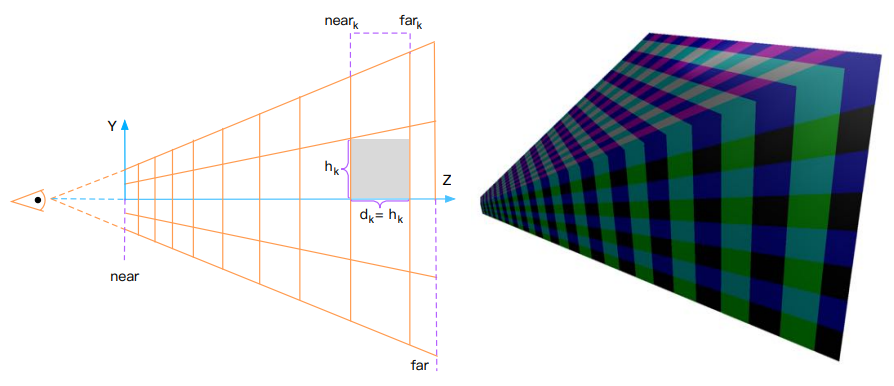
为了索引到一个 cluster,就必须有一个三维坐标来表示 \((i,j,k)\) ;\(i,j\) 其实和 tile-based 的索引映射没有区别,而需要解决的问题是:给定一个深度值 \(z\),其在深度方向的索引值(即 \(k\) )该如何计算?
结论:
\]
其中,near 是近平面的深度,视锥体的 \(Y\) 方向上的张角为 \(2\theta\), \(S_y\) 为屏幕空间 \(Y\) 方向划分的数量
以下是推导过程:
\(near_k\) 为 \(Z\) 方向上第 \(k\) 层 cluster 的近平面在 \(Z\) 方向上的值:
\[near_{k}= near_{k-1}+h_{k-1}
\]\(h_k\) 为在 \(Z\) 方向上第 \(k\) 层其中一个 cluster 的近平面长度。
其中第 0 层 cluster(即朝摄像机的那面位于近平面的 cluster)有:
\[near_0 = near
\]\[h_{0}=\frac{2 \text { near } \tan \theta}{S_{y}}
\]\[h_k = \frac{h_{k-1}*2*tan\theta}{S_y}+d_{k-1}
\]又
\[d_{k-1}=h_{k-1}
\]则
\[\operatorname{near}_{k}=\operatorname{near}\left(1+\frac{2 \tan \theta}{S_{y}}\right)^{k}
\]此时,索引值 \(k\) 可被解出来:
\[k=\left\lfloor\frac{\log \left(-z\ / \text { near }\right)}{\log \left(1+\frac{2 \tan \theta}{S_{y}}\right)}\right\rfloor
\]
Cluster-based Light Culling 优缺点:
[√] culling 效率更高:进一步剔除了更多无关光源(相比 tile-based 多考虑了深度的划分)
[x] culling 流程更加耗性能和占用显存更大:clusters 的数量远远多过 tiles,而每个 cluster 都要做光源相交检测,带来的性能开销大大增加。
Cluster-based Light Culling 数据结构 :
基本和 tile-based light culling 的数据结构大同小异,只不过 clusters 的数量比 tiles 要多得多,buffer 的 size 也自然大得多。
Culling 流程
总体上 cluster-based culling 流程和 tile-based culling 流程差不多,只不过由于 clusters 数量远比 tiles 数量要多得多,性能开销较大(每个 cluster 都要和所有光源进行相交检测),我们可以选择增加 Cluster Visibility Pass 来剔除掉部分无关的 clusters。
当然,不走 visibility,直接对所有 cluster 进行相交检测也是可以的;是否增加该 pass 的核心在于这个 cluster visibility pass 带来的收益是否能抵消掉其带来的额外开销,而这往往需要实机测试。
Cluster Visibility Pass & Cluster Visibility Compact Pass[可选]
Cluster Visibility Pass - compute shader(per Pixel):
首先,我们需要找出所有参与计算的 cluster ,因为屏幕上的所有像素所涉及到的 clusters 数量一般远远小于空间中所有 cluster 的总数量(换句话说实际上能用上场的 clusters 是少部分的),我们只需要对会参与 shading 计算的 clusters 进行光源分配。
每个屏幕 pixel 计算出 cluster index 将索引到对应的 cluster 并标记为 visible:
Cluster Visibility Compact Pass - compute shader(per Cluster):
有了上述记录 cluster visiblity 的数组后,就可以 compact 成一个只记录 visible cluster index 的数组,方便后续的流程进行 indirect dispatch。
这里还可以使用 LDS(local data share)优化。
Injection Pass
Injection Pass - compute shader(per Visible Cluster):基本与 tile-based 类似(遍历光源,相交测试通过后添加进 linked list)。
Compact Pass
Compact Pass - compute shader(per Visible Cluster):与 tile-based 类似(把 linked list compact 成 cluster light index buffer 和 cluster buffer)。
Culling 流程 [基于保守光栅化]
之前填充 culling 数据结构的思路基本是基于相交检测的 compute shader,这里提供另一种来自于 GPU Pro 7 某篇文章的思路:通过对光源几何体进行光栅化来填充 culling 数据结构。
Shell Pass
Shell Pass - rasterization:
对每种光源类型(如 point light 和 spot light 就是两种类型),通过 instancing 来批量绘制属于该类型的所有光源几何体。其中,每个光源几何体利用保守光栅化(conservative rasterization)技术绘制到 tile 分辨率的 RT 上,并记录该光源在每个 tile 上的最大深度值和最小深度值。
RT 的 texture 格式应为
R8G8_UNORM,通过 r,g 分别记录最大和最小深度值。
所谓保守光栅化(conservative rasterization),就是光栅化时只要 fragment 存在图元面积,哪怕只有一点点面积,也视为有效 fragment:
DirectX12 中通过创建一个管线状态对象时设置 ConservativeRaster 的标识
D3D12_CONSERVATIVE_RASTERIZATION_MODE_ON来开启保守光栅化。

在具体实现时,应当是每种光源类型都有一套自己的 vertex shader,然后共用同一套 geometry shader 和 pixel shader。值得注意的是,一个光源对应一个 RT(RenderTarget),为了避免绘制光源的时候重复绑定不同的 RT,可以使用 Texture2DArray 来对应若干个 RT。
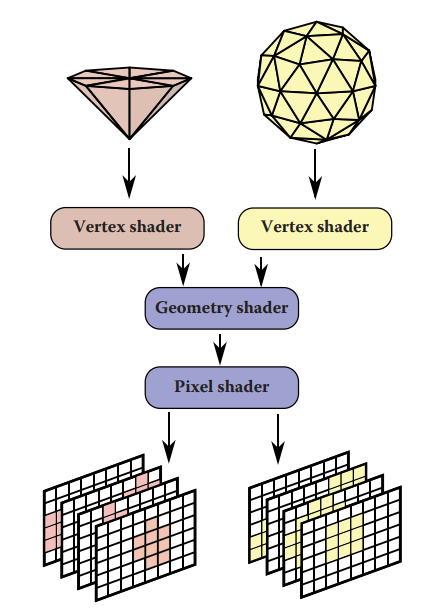
- vertex shader:执行 Model & View 变换,传递 view-space position 和
SV_InstanceID给 geometry shader。
这个 instanceID 就相当于 RT index,也相当于表示 light index。
- geometry shader:接受
SV_InstanceID并输出为SV_RenderTargetArrayIndex,这样就可以指定好 TextureArray 里对应的 RT。接受 triangle 的 3个 view-space positions 并传递 3 个标记为nointerpolation的 view-space positions 给 pixel shader。
为了让 pixel shader 可以拿到 triangle 的三个顶点,因此才需要不插值。
- pixel shader:通过 3 个 view-space positons,计算并输出 triangle 在这块 tile 的最小 & 最大深度,并根据
SV_IsFrontFace来判断该深度应该输出到 r(最小深度)还是 g(最大深度)。
注:首先,需要关闭背面剔除,因为背面的光源用于提供最大深度;其次,需要启用
MIN混合模式,并且为了让 g 通道适配这种混合模式,写入 g 通道时应该写 1-maxDepth。
计算并输出 triangle 在这块 tile 的最小 & 最大深度的方法:
需要依次评估 Edges(相交)、Corners(三角形内含 tile)、Vertices(tile 内含三角形) 三种 case,并取这几种 case 得到的深度中的最大值和最小值:
- Edges case:12 次 linesegment-plane test(triangle 的 3 个边 * tile 的 4 个侧面),有交点则记录交点深度。
- Corners case:4 次 ray-triangle test(tile 的四个顶点分别往深度轴方向打出射线),有交点则记录交点深度。
- Vertices case:检测 3 个 triangle 顶点分别是否在 tile frustum 范围内,若在则记录该顶点的深度。
具体计算见 GPU Pro 7。

Fill Pass
Fill Pass - compute shader(per LightTile):
利用 shell pass 产生的最大最小深度值来填充 tile 范围内 clusters 的光源列表(tile和最大最小深度值组成了一段空间,这段空间范围里包含的所有 clusters 都会被该光源填充)。
TextureArray 中每个 texture 对应一个 light,然后每个 texture 都包含 TILESX*TILESY 个 tiles,那么 cs 的 dispatch 应该开启 TILESX * TILESY * NumLight 个 threads 来实现填充,具体每个 thread 行为以下:
- 通过 threadID.z 来访问 TextureArray 得到对应的 RT,并通过 threadID.xy 来找到对应的 tile ,读出最大深度和最小深度并映射成 在 z 轴上的 cluster index:far 和 near。
- 从 near 循环累加到 far,每次循环都添加一个新的 link 进
ClusterLinkedList,具体行为和 tile-based 的 injection pass 差不多,不多讲述。
Fill Pass 代码:
// This array has NUM_LIGHTS slices and contains the near and far
// Z−clusters for each tile.
Texture2DArray<float2> conservativeRTs : register(t0);
// Linked list of light IDs.
RWByteAddressBuffer StartOffsetBuffer : register(u0);
RWStructuredBuffer<LinkedLightID> LinkedLightList : register(u1);
[numthreads (TILESX , TILESY , 1)]
void main ( uint3 thread_ID : SV_DispatchThreadID ){
// Load near and far values (x is near and y is far).
float2 near_and_far = conservativeRTs.Load (int4(thread_ID , 0));
if ( near_and_far.x == 1.0 f && near_and_far.y == 1.0f )
return;
// Unpack to Z−cluster space ([0,1] to [0,255]). Also handle cases where no near or far clusters were written.
uint near = (near_and_far.x == 1.0f) ? 0 : uint ( near_and_far.x ∗ 255.0 f + 0.5f );
uint far = (near_and_far.y == 1.0f) ? (CLUSTERSZ − 1) : uint(((CLUSTERSZ − 1.0f) / 255.0f − near_and_far.y) ∗ 255.0f + 0.5f);
// Loop through near to far and fill the light linked list .
uint offset_index_base = 4 ∗ (thread_ID.x + CLUSTERSX ∗ thread_ID.y);
uint offset_index_step = 4 ∗ CLUSTERSX ∗ CLUSTERSY;
uint type = light_type ;
for( int i = near; i <= far; ++i){
uint index_count = LinkedLightList.IncrementCounter();
uint start_offset_address = offset_index_base + offset_index_step ∗ i;
uint prev_offset;
StartOffsetBuffer.InterlockedExchange(start_offset_address, index_count, prev_offset);
LinkedLightID linked_node;
linked_node.lightID = (type << 24) | (thread_ID.z & 0xFFFFFF);// Light type is encoded in the last 8 bit of the node.light ID and light ID in the first 24 bits .
linked_node.link = prev_offset;
LinkedLightList[index_count] = linked_node;
}
}
原文在之后并没有对 linked list 进行 compact,而是直接在 shading 时遍历 linked list。如果我们尝试改进它,就可以在这之后增加一个 compact pass,并最好实机对比一下有无 compact 的性能开销和空间开销。
Normal-based Light Culling
除了 tile 和 cluster 这种基于空间分布(二维空间和三维空间)来 culling 光源的,我们还可以额外再扩展出基于法线的分布,用于剔除背向的光源。
例如,可以用一堆均匀排布且半角相同的 cone 来表示不同的法线范围。此外,为了包住所有球面方向,相邻的 cone 之间必定有范围重叠。
下图不太准确,因为只是大概提供了包住半球方向的一些 cone,并且 cone 之间有空隙,仅用于直观理解 cone 如何均匀排布。
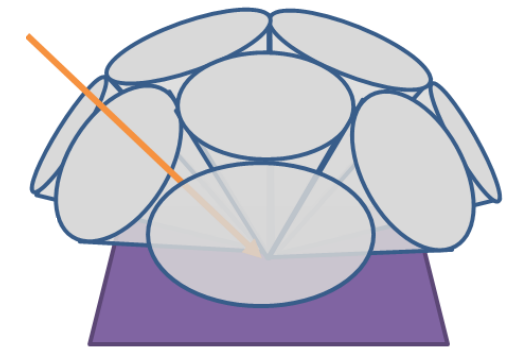
这样,我们就可以先根据每个光源的朝向,填充光源到对应 cone 的光源列表中,在 shading 时通过计算 shading point 的法线归属于第几个 cone 来快速找到对应的光源列表。
实际上,normal-based light culling 往往是结合 tile 或 cluster 一起使用,其实就是额外扩展多一个维度用于索引光源列表。原本仅通过位置得到的 3D 索引(x, y, z) 现在可以变成 4D 索引(x, y, z, normal)。
Culling 流程
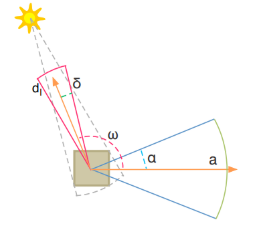
\(\alpha\) 是一个法线分布的 cone 半角,\(\delta\) 则是光源的半角(directional light 为 0,point light 为 \(\frac{\pi}{4}\),spot light 为指定半角);cone 的中心方向记为 \(\mathrm{a}\) ,光源的反向向量记为 \(\mathrm{d_l}\) 。
- culling 数据结构的构建,对每个 cone:遍历光源,如果光源反向向量 \(\mathrm{d_l}\) 与 cone 的中心方向 \(\mathrm{a}\) 的夹角 \(\omega < \frac{\pi}{2}+\alpha+\delta\) ,那么光源添加进该 cone 的光源列表。
- 最终 shading:直接通过 shading point 的法线计算出 cone 索引,并获取该 cone 的光源列表。
相交检测优化
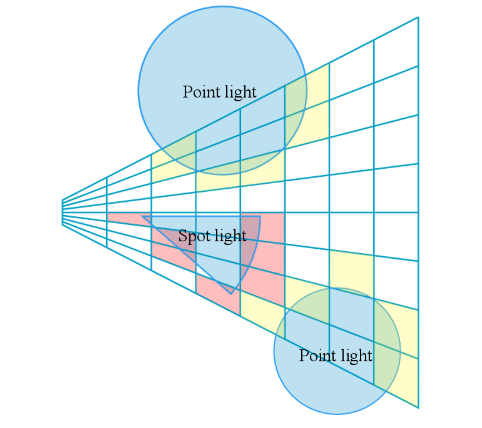
大多数的光源都属于 point light/spot light,因此 tile-based lighting culling 会存在大量的 sphere-frustum 相交检测,下面就大概列举下优化的点。
这部分内容主要参考这个博客 Improve Tile-based Light Culling with Spherical-sliced Cone
Sphere-Frustum Test
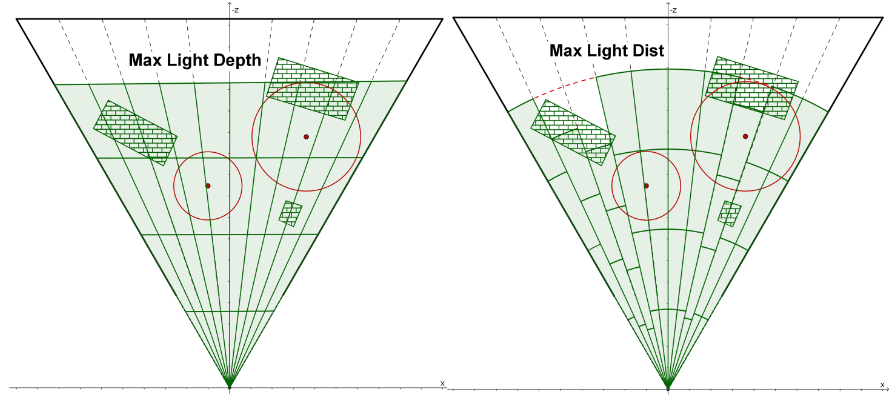
如下图,绿色区域为是 tile fustum 在侧面(xoz 平面)上真正可以被 light 影响的区域,称之为 true positive。
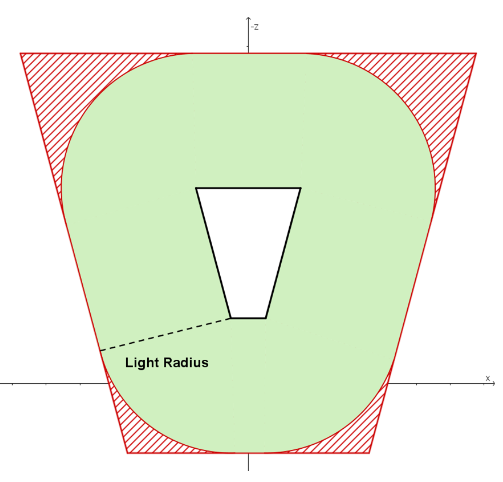
sphere-frustum test 是计算球与 frustum 的六个平面的有向距离,若有向距离均小于球半径则视为测试通过。但是,sphere-frustum 测试通过的区域会比实际区域多,多出来的部分称之为 false positive(如上图,红色区域为 false positive 区域),也是造成剔除不精细的原因。
由于 frustum 的 near&far plane 和 view 的 near&far plane 是平行的,所以在实践中往往把光源深度与 tile max depth/min depth 进行比较,这样就可以减少两个平面的有向距离计算。
// test near plane & far plane
if (lightDepth - lightRadius <= tileMaxDepth &&
lightDepth + lightRadius >= tileMinDepth)
{
for (int i = 0; i < 4; ++i)
{
// test 4 side planes
}
}
我们的目标就是让测试产生尽可能少的 false positive,接下来我们将用 cone test 去减少 frustum 四个侧面的 test,用 spherical-slice cone test 去改进 near&far plane 的 test。
Cone Test
为了减少 false positive 区域,我们可以对 tile frustum 的 4 个侧面使用 cone test 而非 sphere-cone test。
frustum 的四个侧面在投影空间中围成一个四边形,而球体在投影空间也是一个圆,这时的问题就可以视为是 2D 空间下的四边形与圆的求交问题。如果这四个侧面仍然用 sphere-frustum test 的做法,那么 false positive 就会如下图红色部分;而 cone test 的做法是 计算出刚好包围该四边形的圆的半径,然后拿去和光源做圆与圆的相交测试 ,cone test 的 false postive 如下图的蓝色部分。
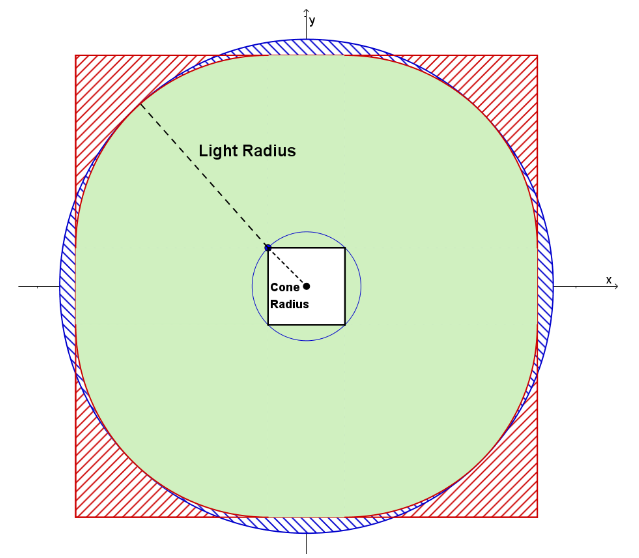
实际上,当圆远远大于四边形的时候,cone test 的 false positive(蓝色区域)会比 sphere-frustum test 的 false positive(红色区域)要更少;反之,当四边形远远大于四边形的时候,使用 sphere-cone test 会更少 false positive。
light radius 往往比 frustum 的正面四边形(面向 view 的,即 xoy 平面)要大得多,因此对于构成该四边形的四个侧面,我们可以替换成 cone test;而 frustum 的侧面四边形(xoz 或 yoz 平面)有可能因为 min/max depth 相差太大导致形状拉伸地很长,得到的 cone radius 就很大,也就不适合做 cone test。
当然在实践中,我们不用计算投影平面上的半径,而是计算 cos 值(象征着夹角大小,夹角越大cos值越小),并通过来比较光源的半角+tile的半角是否大于光源中心到 tile 中心的夹角,若是则意味着测试通过:
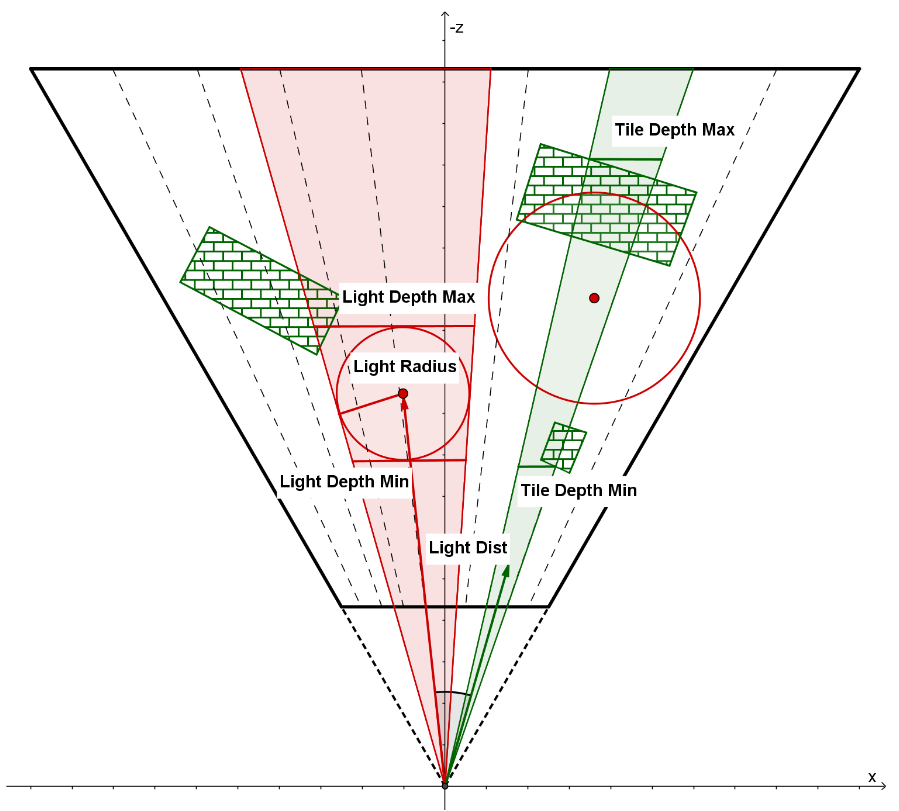
vec3 tileCenterVec = normalize(sides[0] + sides[1] + sides[2] + sides[3]);
float tileCos = min(min(min(dot(tileCenterVec, sides[0]), dot(tileCenterVec, sides[1])), dot(tileCenterVec, sides[2])), dot(tileCenterVec, sides[3]));
float tileSin = sqrt(1 - tileCos * tileCos);
// get lightPos and lightRadius in view space
float lightDistSqr = dot(lightPos, lightPos);
float lightDist = sqrt(lightDistSqr);
vec3 lightCenterVec = lightPos / lightDist;
float lightSin = clamp(lightRadius / lightDist, 0.0, 1.0);
float lightCos = sqrt(1 - lightSin * lightSin);
// angle of light center to tile center
float lightTileCos = dot(lightCenterVec, tileCenterVec);
float lightTileSin = sqrt(1 - lightTileCos * lightTileCos);
// special for light inside a tile
bool lightInsideTile = lightRadius > lightDist;
// sum angle = light cone half angle + tile cone half angle
// ps: cos(A+B) = cos(A)*cos(B) - sin(A)*sin(B)
float sumCos = lightInsideTile ? -1.0 : (tileCos * lightCos - tileSin * lightSin);
if (sumCos <= lightTileCos // cone test
&& lightDepth - lightRadius <= tileMaxDepth // far plane test
&& lightDepth + lightRadius >= tileMinDepth // near plane test
)
{
// light intersect this tile
}
Spherical-sliced Cone Test
对于 frustum 的 near&far plane,传统的 sphere-frusutm test 只基于深度去判断,会导致相当多的 false positive(如下图左侧);而 spherical-sliced cone test 则基于距离去判断,并且还考虑了投影在距离轴上的实际 min&max 范围,具有更好的 culling 效率(如下图右侧)。
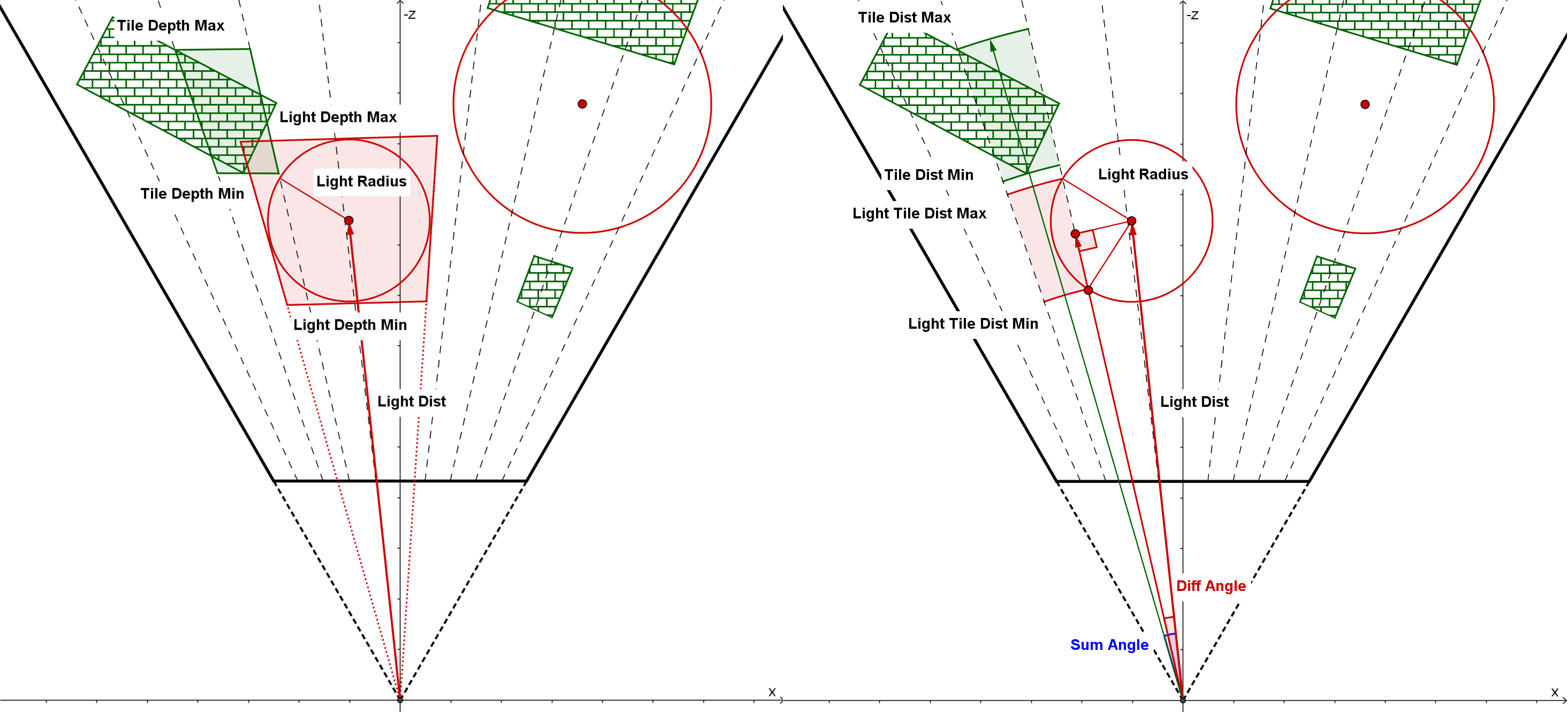
Spherical-sliced Cone Test 的大概做法是算出 light 中心投影在距离轴上的位置(lightTileDistBase)和 light 半径投影在距离轴上的长度(lightTileDistOffset),从而确定了 min&max dist 的范围:
ps:因为 spherical-sliced cone test 是基于距离的,因此 tile 被视为一个切过片的圆,从而能更容易做 light 投影到 tile 距离轴的计算;至于基于深度的方式,要投影到深度轴则计算困难得多,且 culling 效率也不如距离轴。
// diff angle = sum angle - tile cone half angle
// clamp to handle the case when light center is within tile cone
float diffSin = clamp(lightTileSin * tileCos - lightTileCos * tileSin, 0.0, 1.0);
float diffCos = (diffSin == 0.0) ? 1.0 : lightTileCos * tileCos + lightTileSin * tileSin;
float lightTileDistOffset = sqrt(lightRadius * lightRadius - lightDistSqr * diffSin * diffSin);
float lightTileDistBase = lightDist * diffCos;
if (lightTileCos >= sumCos &&
lightTileDistBase - lightTileDistOffset <= maxTileDist &&
lightTileDistBase + lightTileDistOffset >= minTileDist)
{
// light intersect this tile
}

如图分别为:(a) 正常渲染; (b) 通过 sphere-frustum test 的 tiles; (c) 通过 cone test 的 tiles; (d) 通过 cone test + spherical-sliced cone test 的 tiles;
| Lighting Time | Improvement | |
|---|---|---|
| Sphere-Frustum Test(6 planes) | 5.55 ms | 0% |
| Cone Test(4 side planes) + Sphere-Frustum Test(near&far planes) | 5.30 ms | 4.50% |
| Cone Test(4 side planes) + Spherical-sliced Cone Test(near&far planes) | 4.68 ms | 15.68% |
UnrealEngine 5.1 Light Culling 简析
cluster-based light culling,每个 cluster(在 UE5.1 里被称为 grid)在屏幕上占据 64 × 64 pixels,在 z 轴上默认分成 32 个 slices。
相交检测:
在 view space 进行 sphere-AABB test:对 cluster 从 clip space 的 AABB 变换到 view space 下的六面体,并再建立新的 AABB 包围住该六面体;最后让该 AABB 与 point light 进行 sphere-AABB test。
针对 spot light 的 cone-AABB test:对 cluster 从 clip space 的 AABB 变换到 view space 下的六面体,并再建立新的 AABB 包围住该六面体;然后构建一个贴在 spot light cone 上的平面,并且这个平面正对着 AABB 中心;最后让该平面与 AABB 进行 plane-AABB test。
UE5.1 的相交检测其实大有优化空间,因为建立新的 AABB 会导致 cluster 的额外扩展,造成很多 false positive 以及带来的 culling 效率下降。
culling 数据结构的构建:
- 可以选择均匀空间的 cluster light index 数组:
- 省去了 compact pass。
- 占据更多显存空间(而且绝大部分是被浪费的)。
- 某些地方极端多光源的情况下,部分 tile 会发生光源截断(即不能容纳所有的光源)。
- 可以选择基于 Linked List 的 culling 流程:
- LDS(local data share)优化:先利用 groupshare 组成局部 linked list,然后再组成全局 linked list。
UE 5.1 culling 数据结构的构建:
LightGridInjection.usf和LightGridCommon.ush。UE 5.1 很多渲染流程都在最终 shading 用到了 light culling:
- 前向渲染:默认启动 cluster-based light culling;shader 代码见
ForwardLightingCommon.ush。- 延迟渲染管线: 需启用
r.UseClusteredDeferredShading;shader 代码见MobileDeferredShading.usf。- mobile 延迟渲染管线:需启用
r.Mobile.UseClusteredDeferredShading;shader 代码见ClusteredDeferredShadingPixelShader.usf。
更多 idea
- 面对千万级的光源数量,填充 culling 数据结构的流程本身就需要遍历太多光源,相当耗费性能,可以分层次剔除,并且越大的层次 test 粒度可以越粗:先用大块 tile 进行粗粒度 test(例如八叉树),再用小块 tile 进行细粒度 test 。
- 可以将优化的相交检测同样应用到 cluster-based light culling 上:
- 对于 spot light 这种锥形的形状进行 culling 的算法可能是费时的,可以考虑用球包围盒将其锥形包住,并将其视为 sphere 进行与 point light 一样的 culling 处理。当然球包围盒可以在 CPU 端预先计算出来,这样传递给 GPU 将可以统一成对 sphere 处理的 shader 代码。
float spotLightConeHalfAngleCos = cos(spotLightFOV * 0.5f); float sphereRadius = spotlightRange * 0.5f / (spotLightConeHalfAngleCos *spotLightConeHalfAngleCos);
float3 sphereCenter = spotLightPos + spotLightDirection * sphereRadius;
当然也可以探索锥形形状的 culling 算法,例如有涉及 cone-sphere test 的文章: "Cull that Cone”。
- light culling 往往用于 view frustum 内的 direct lighting shading,而 view frustum 之外就没有 culling 数据结构;因此如果要将 light culling 的思想应用于 GI,就需要建立另一套 culling 数据结构以囊括 view frustum 之外的空间(GI 仍有可能需要在 view frustum 内搜集 direct lighting,这时候也可以选择复用传统的 culling 数据结构,在 view frustum 之外则 fall back 成别的 culling 结构)。
Battlefield V 就使用了囊括 camera 周围空间(而非只覆盖 view frustum)的 grid-based light culling,并同样使用 linked list 作为实际数据结构;此外由于该游戏地图大部分在一个地面上,因此在高度轴上可以不进行划分(即 grid.dimension.y = 1),减少 grid 的总数。
sorted lights:在 CPU 就根据光源类型排序好光源,从而让 shader 减少类型判断代码,针对同一类型的光源批量处理。
对于静态光源可以建立具有滚动优化的 light grid 结构,并且一般 grid 粒度更细;对于动态光源则建立正常 light grid 结构,一般 grid 粒度更粗。
- 滚动优化:新 grid 在上一帧结构找到原位时,直接复制原 grid 的光源列表到新的光源列表;否则,再对全局光源列表进行遍历检测相交来添加到新的光源列表。
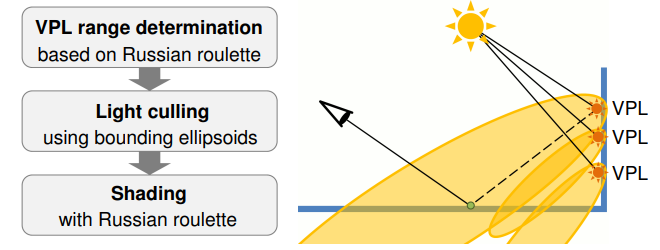
基于 VPL(virtual point light) specular lobe 的 light culling:
- 将 VPL 视为光源,根据它们的 specular lobe 来构造椭圆包围盒,并通过 russian roulette 来随机决定 lobe 的长度(避免因 culling 造成的能量截断)。
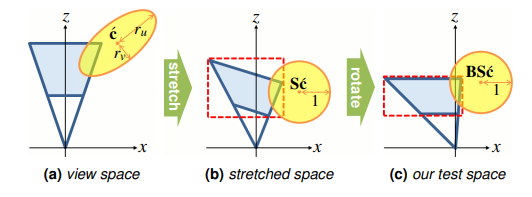
- 通过 stretch 和 rotate 来做椭圆和 frustum 的相交检测。
参考
- Improve Tile-based Light Culling with Spherical-sliced Cone | Eric's Blog
- A 2.5D CULLING FOR FORWARD+ | SIGGRAPH ASIA 2012
- Optimizing tile-based light culling | Wicked Engine Net
- 《GPU Pro 7: Advanced Rendering Techniques》
- It Just Works: Ray-Traced Reflections in "Battlefield V" | GDC 2019
- Stochastic Light Culling for VPLs on GGX Microsurfaces [Tokuyoshi 2017]
多光源渲染方案 - Light Culling的更多相关文章
- 精确光源(Punctual Light Sources)
<Physically-Based Shading Models in Film and Game Production>(SIGGRAPH 2010 Course Notes) (地址: ...
- Unity原生渲染方案
Unity原生渲染方案 作者:3dimensions three_dimensions@live.cn 本文为原创内容,转载请注明出处. 做这个的动机是想在原生代码中使用Unity的材质系统绘制,同时 ...
- AIR 3.0针对移动设备的高性能渲染方案
转自:http://blog.domlib.com/articles/242.html 当我们一边正在等待Stage3D的发布时,很多开发者似乎还停留在这个印象中:即使AIR 3.0也无法在移动设备上 ...
- Web开发中,页面渲染方案
转载自:http://www.jianshu.com/p/d1d29e97f6b8 (在该文章中看到一段感兴趣的文字,转载过来) 在Web开发中,有两种主流的页面渲染方案: 服务器端渲染,通过页面渲染 ...
- PIE SDK地图图层渲染方案管理
1. 功能简介 在数据种类较多.渲染规则复杂的情况下,逐个设置其渲染方式是一件繁琐的工作.PIE SDK提供了一种省力省心的办法, PIE SDK提供栅格和矢量数据渲染方案的打开与保存.能够将配色方案 ...
- [GEiv]第七章:着色器 高效GPU渲染方案
第七章:着色器 高效GPU渲染方案 本章介绍着色器的基本知识以及Geiv下对其提供的支持接口.并以"渐变高斯模糊"为线索进行实例的演示解说. [背景信息] [计算机中央处理器的局限 ...
- 腾讯新闻抢金达人活动node同构直出渲染方案的总结
我们的业务在展开的过程中,前端渲染的模式主要经历了三个阶段:服务端渲染.前端渲染和目前的同构直出渲染方案. 服务端渲染的主要特点是前后端没有分离,前端写完页面样式和结构后,再将页面交给后端套数据,最后 ...
- 基于.NetCore开发博客项目 StarBlog - (19) Markdown渲染方案探索
前言 笔者认为,一个博客网站,最核心的是阅读体验. 在开发StarBlog的过程中,最耗时的恰恰也是文章的展示部分功能. 最开始还没研究出来如何很好的使用后端渲染,所以只能先用Editor.md组件做 ...
- vue的两种服务器端渲染方案
作者:京东零售 姜欣 关于服务器端渲染方案,之前只接触了基于react的Next.js,最近业务开发vue用的比较多,所以调研了一下vue的服务器端渲染方案. 首先:长文预警,下文包括了两种方案的实践 ...
- 从《BLAME!》说开去——新一代生产级卡通真实感混合的渲染方案
<BLAME!>是Polygon Pictures Inc.(以下简称PPI)创业33周年以来制作的第一部CG剧场电影,故事来自于贰瓶勉的同名漫画作品(中文译名为<探索者>或者 ...
随机推荐
- DG:三种模式切换
应用归档日志方式进行数据同步 SQL> alter system set log_archive_dest_2='SERVICE=standby arch noaffirm valid_for= ...
- GDOU-CTF-2023新生赛Pwn题解与反思
第一次参加CTF新生赛总结与反思 因为昨天学校那边要进行天梯模拟赛,所以被拉过去了.16点30分结束,就跑回来宿舍开始写.第一题和第二题一下子getshell,不用30分钟,可能我没想那么多,对比网上 ...
- React 组件进入和退出动画实现
在实现一个React中的弹框组件时,想给组件加个进入和退出动画,但发现React没有Vue3那样现成的api,因此需要自己设计. 主要思路为给组件添加一个state来选择className,不同的cl ...
- 开心档之MySQL WHERE 子句
MySQL WHERE 子句 我们知道从 MySQL 表中使用 SQL SELECT 语句来读取数据. 如需有条件地从表中选取数据,可将 WHERE 子句添加到 SELECT 语句中. 语法 以下是 ...
- 第7章. 部署到GiteePages
Gitee Pages 是一个免费的静态网页托管服务,您可以使用 Gitee Pages 托管博客.项目官网等静态网页.如果您使用过 Github Pages 那么您会很快上手使用 Gitee 的 P ...
- vue移动端预览 pdf 文件
pdf预览,在项目中是很常见的需求,在PC端web项目中,我们可以使用window.open(url)直接打开pdf进行预览,那么移动端虽然我们也可以使用此方法,但是这是新开了一个webview页面, ...
- 用C#发送post请求,实现更改B站直播间标题[简单随笔]
第一次发这样的网络数据包.记录一下. API参考 https://github.com/SocialSisterYi/bilibili-API-collect/blob/master/live/man ...
- [Opencv-C++] 2. Opencv入门
一.显示图像 从磁盘加载并在屏幕上显示一幅图像的简单Opencv程序 //Example 2-1. A simple OpenCV program that loads an image from d ...
- python库Munch的使用记录
开头 日常操作字典发现发现并不是很便利,特别是需要用很多 get('xxx','-') 的使用,就觉得很烦,偶然看到Kuls大佬公众号发布的一篇技术文有对 python munch库的使用, 使得字典 ...
- 2021-02-01:Redis 集群会有写操作丢失吗?
福哥答案2021-02-01: 以下情况可能导致写操作丢失:1.过期 key 被清理.2.最大内存不足,导致 Redis 自动清理部分 key 以节省空间.3.主库故障后自动重启,从库自动同步.4.单 ...