2023-06-25:redis中什么是缓存穿透?该如何解决?
2023-06-25:redis中什么是缓存穿透?该如何解决?
答案2023-06-25:
缓存穿透
缓存穿透指的是查询一个根本不存在的数据,在这种情况下,无论是缓存层还是存储层都无法命中。因此,每次请求都需要访问数据库,这将导致不存在的数据每次都需要查询存储层,这样缓存就失去了保护后端存储的作用。缓存穿透问题的解决对于维护系统性能和资源利用至关重要。
造成缓存穿透的基本原因有两个。
缓存穿透的主要原因有两个。
首先,可能是由于业务代码或数据本身出现问题。例如,如果数据库中的ID从1开始自增,而某些请求携带了不存在的ID值(比如负数或特别大的值),如果对参数不进行校验,这些请求将会绕过缓存直接访问数据库。由于数据库中也查不到对应的数据,每个请求都会以相同的方式处理,这样会给数据库带来很大压力,尤其是在高并发的情况下,容易导致系统崩溃。
其次,缓存穿透也可能由恶意攻击、爬虫等行为造成,这些请求大量命中缓存但数据却不存在,导致每个请求都需要访问存储层。这种情况下,攻击者可以通过大量的无意义请求消耗系统资源,从而影响系统的正常运行。

如何解决
1.缓存空对象
当存储层不命中时,即使在数据库中也没有找到命中的数据,仍然将空对象保存到缓存层中。这样,下次对该数据的访问将从缓存中获取,从而保护了后端数据源的访问。然而,需要注意的是如果频繁存储空值,会导致缓存层占用更多的内存空间,尤其在面对攻击时问题更为严重。因此,可以为这类数据设置较短的过期时间,以使其能够自动被清理出缓存。
2.布隆过滤器拦截
在访问缓存层和存储层之前,使用布隆过滤器提前保存已存在的键,并进行第一层拦截。例如,对于一个推荐系统,存在4亿个用户ID,每个小时根据用户的历史行为计算并存储推荐数据。然而,对于最新的用户由于没有历史行为,可能发生缓存穿透。为此,可以将所有推荐数据的用户ID构建成布隆过滤器。如果布隆过滤器认为某个用户ID不存在,就不会进一步访问存储层,从而在一定程度上保护了存储层。
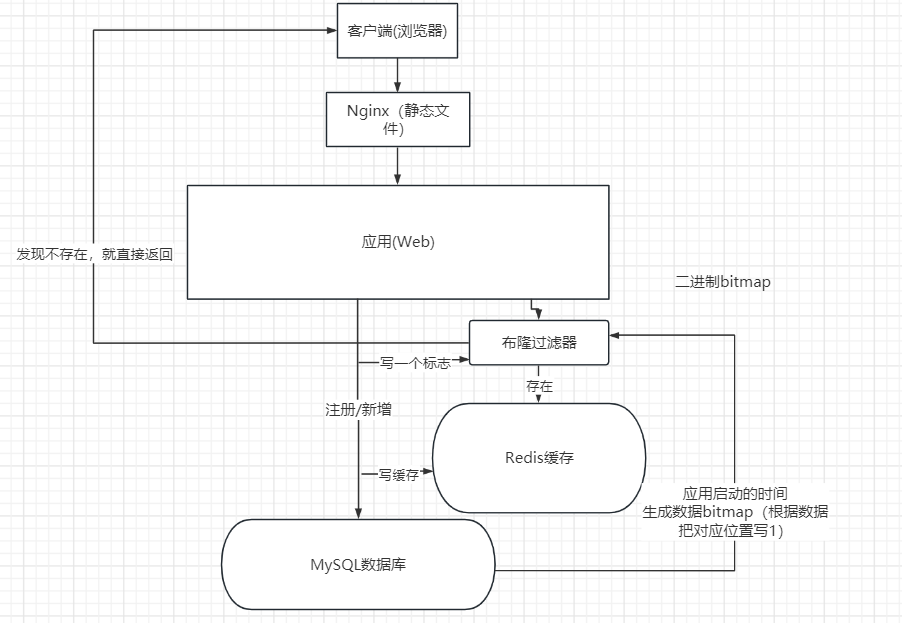
这些方法适用于数据命中率不高、数据相对稳定、实时性要求较低(通常是数据集较大)的应用场景。尽管实施这些方法可能会增加代码的维护复杂性,但能有效减少缓存空间的占用。
2023-06-25:redis中什么是缓存穿透?该如何解决?的更多相关文章
- 【Redis场景3】缓存穿透、击穿问题
场景问题及原因 缓存穿透: 原因:客户端请求的数据在缓存和数据库中不存在,这样缓存永远不会生效,请求全部打入数据库,造成数据库连接异常. 解决思路: 缓存空对象 对于不存在的数据也在Redis建立缓存 ...
- 什么是redis的缓存雪崩与缓存穿透?如何解决?
一.缓存雪崩 1.1 什么是缓存雪崩? 首先我们先来回答一下我们为什么要用缓存(Redis): 1.提高性能能:缓存查询是纯内存访问,而硬盘是磁盘访问,因此缓存查询速度比数据库查询速度快 2.提高并发 ...
- Redis(七)缓存穿透、缓存击穿、缓存雪崩以及分布式锁
应用问题解决 1 缓存穿透 1.1 访问结构 正常情况下,服务器接收到浏览器发来的web服务请求,会先去访问redis缓存,如果缓存中存在数据则直接返回,否则会去查询数据库里面的数据,然后保存在red ...
- [python]mysql数据缓存到redis中 取出时候编码问题
描述: 一个web服务,原先的业务逻辑是把mysql查询的结果缓存在redis中一个小时,加快请求的响应. 现在有个问题就是根据请求的指定的编码返回对应编码的response. 首先是要修改响应的bo ...
- redis缓存穿透,缓存击穿,缓存雪崩原因+解决方案
一.前言 在我们日常的开发中,无不都是使用数据库来进行数据的存储,由于一般的系统任务中通常不会存在高并发的情况,所以这样看起来并没有什么问题,可是一旦涉及大数据量的需求,比如一些商品抢购的情景,或者是 ...
- Redis面试题记录--缓存双写情况下导致数据不一致问题
转载自:https://blog.csdn.net/lzhcoder/article/details/79469123 https://blog.csdn.net/u013374645/article ...
- Redis 中的原子操作(3)-使用Redis实现分布式锁
Redis 中的分布式锁如何使用 分布式锁的使用场景 使用 Redis 来实现分布式锁 使用 set key value px milliseconds nx 实现 SETNX+Lua 实现 使用 R ...
- Redis 中的事务分析,Redis 中的事务可以满足ACID属性吗?
Redis 中的事务 什么是事务 1.原子性(Atomicity) 2.一致性(Consistency) 3.隔离性(Isolation) 4.持久性(Durability) 分析下 Redis 中的 ...
- redis之缓存穿透、缓存击穿、缓存雪崩
一.缓存穿透 1 什么是缓存穿透 缓存穿透是指查询一个在redis和DB中都不存在的数据,redis中查不到去DB查,DB查不到则不写入redis,导致每次查询这个数据都要穿过redis穿透到DB 2 ...
- Java模拟并解决缓存穿透
什么叫做缓存穿透 缓存穿透只会发生在高并发的时候,就是当有10000个并发进行查询数据的时候,我们一般都会先去redis里面查询进行数据,但是如果redis里面没有这个数据的时候,那么这10000个并 ...
随机推荐
- python医学病理图片svs装换
SVS文件是什么? 最开始拿到SVS文件一脸懵逼的,这货长这样(在windows下可以用Aperio ImageScope这个开源软件打开): 我现在接触的这种图片的大小一般在60M-1.5G之间,可 ...
- MordernC++之 auto 和 decltype
在C++11标准中,auto作为关键字被引入,可以用来自动推导变量类型,auto可以用于定义变量,函数返回值,lambda表达式等,在定义变量时可以使用auto来代替具体类型,编译器根据变量初始化表达 ...
- 一分钟使用Gitee,把本地项目放入gitee仓库中
一.先创建一个Gitee账号 首先需要自己去别的地方看创建一个空仓库,然后复制仓库的地址 省略... 现有本地有项目代码,远程空仓库一个,如何把本地项目代码推到远程仓库? 1.在项目根目录初始化 Gi ...
- Linux进程管理(命令)入门
进程是一个运行中的程序 进程查看 ps 能够查看当前终端下运行的进程 $ ps PID TTY TIME CMD 26305 pts/0 00:00:00 bash 26312 pts/0 00:00 ...
- DRF的限流组件(源码分析)
DRF限流组件(源码分析) 限流,限制用户访问频率,例如:用户1分钟最多访问100次 或者 短信验证码一天每天可以发送50次, 防止盗刷. 对于匿名用户,使用用户IP作为唯一标识. 对于登录用户,使用 ...
- javasec(三)类加载机制
这篇文章介绍java的类加载机制. Java是一个依赖于JVM(Java虚拟机)实现的跨平台的开发语言.Java程序在运行前需要先编译成class文件,Java类初始化的时候会调用java.lang. ...
- 【对比】文心一言对飚ChatGPT实操对比体验
前言 缘由 百度[文心一言]体验申请通过 本狗中午干饭时,天降短信,告知可以体验文心一言,苦等一个月的实操终于到来.心中这好奇的对比心理油然而生,到底是老美的[ChatGPT]厉害,还是咱度娘的[文心 ...
- uniapp小程序开发准备工作
1.下载HbuilderX HBuilderX官网:https://www.dcloud.io/hbuilderx.html 下载正式版--下载完后解压--双击打开HBuilderX.exe文件就可以 ...
- VUE的路由懒加载及组件懒加载
一,为什么要使用路由懒加载 为给客户更好的客户体验,首屏组件加载速度更快一些,解决白屏问题 二,懒加载简单来说就是延迟加载或按需加载,即在需要的时候的时候进行加载 三,常用的懒加载方式有两种:即使用v ...
- .gitignore 文件语法介绍
.gitignore 文件的作用 A gitignore file specifies intentionally untracked files that Git should ignore. Fi ...