文本识别分类系统python,基于深度学习的CNN卷积神经网络算法
一、介绍
文本分类系统,使用Python作为主要开发语言,通过TensorFlow搭建CNN卷积神经网络对十余种不同种类的文本数据集进行训练,最后得到一个h5格式的本地模型文件,然后采用Django开发网页界面,实现用户在界面中输入一段文字,识别其所属的文本种类。
在我们的日常生活和工作中,文本数据无处不在。它们来自各种来源,包括社交媒体、新闻文章、客户反馈、科研论文等。随着大数据和人工智能技术的不断发展,如何从庞大的文本数据中提取有用的信息,识别文本的种类,成为了当前数据处理领域的一个热门课题。我们很高兴向大家介绍一个全新的文本分类系统,它将深度学习技术、Python语言与网页应用开发融为一体,以用户友好的方式提供精确的文本分类服务。
二、效果展示
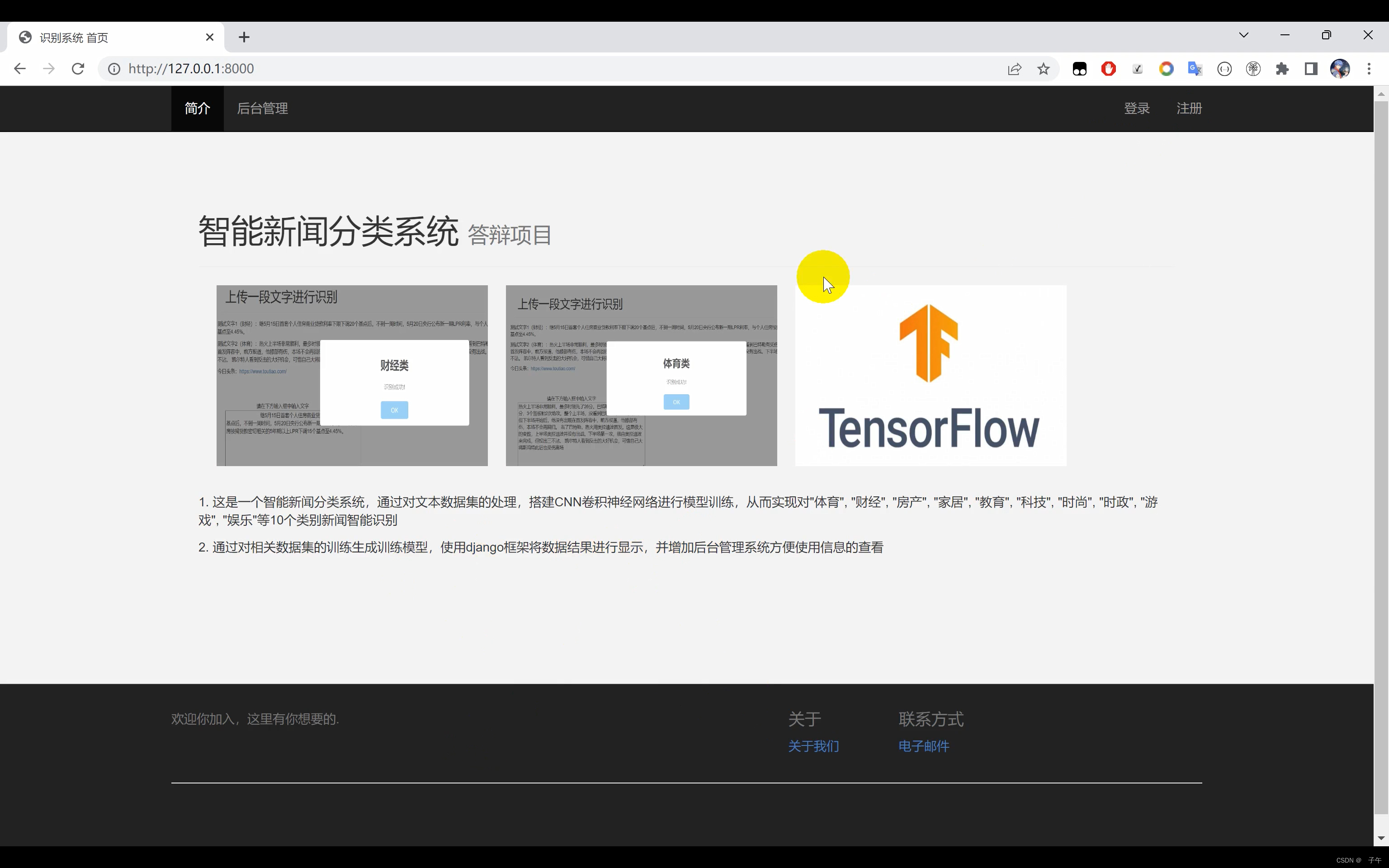
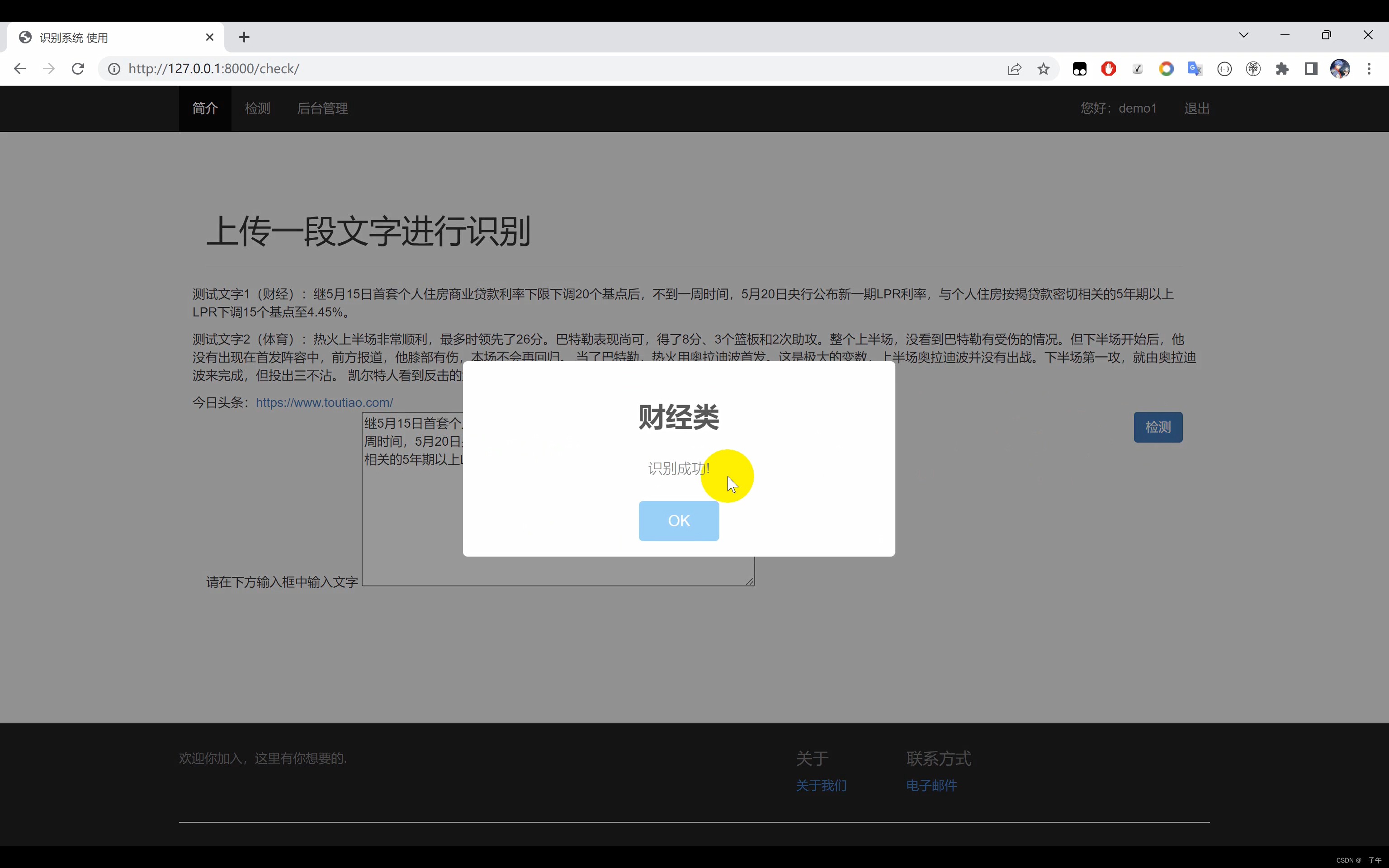
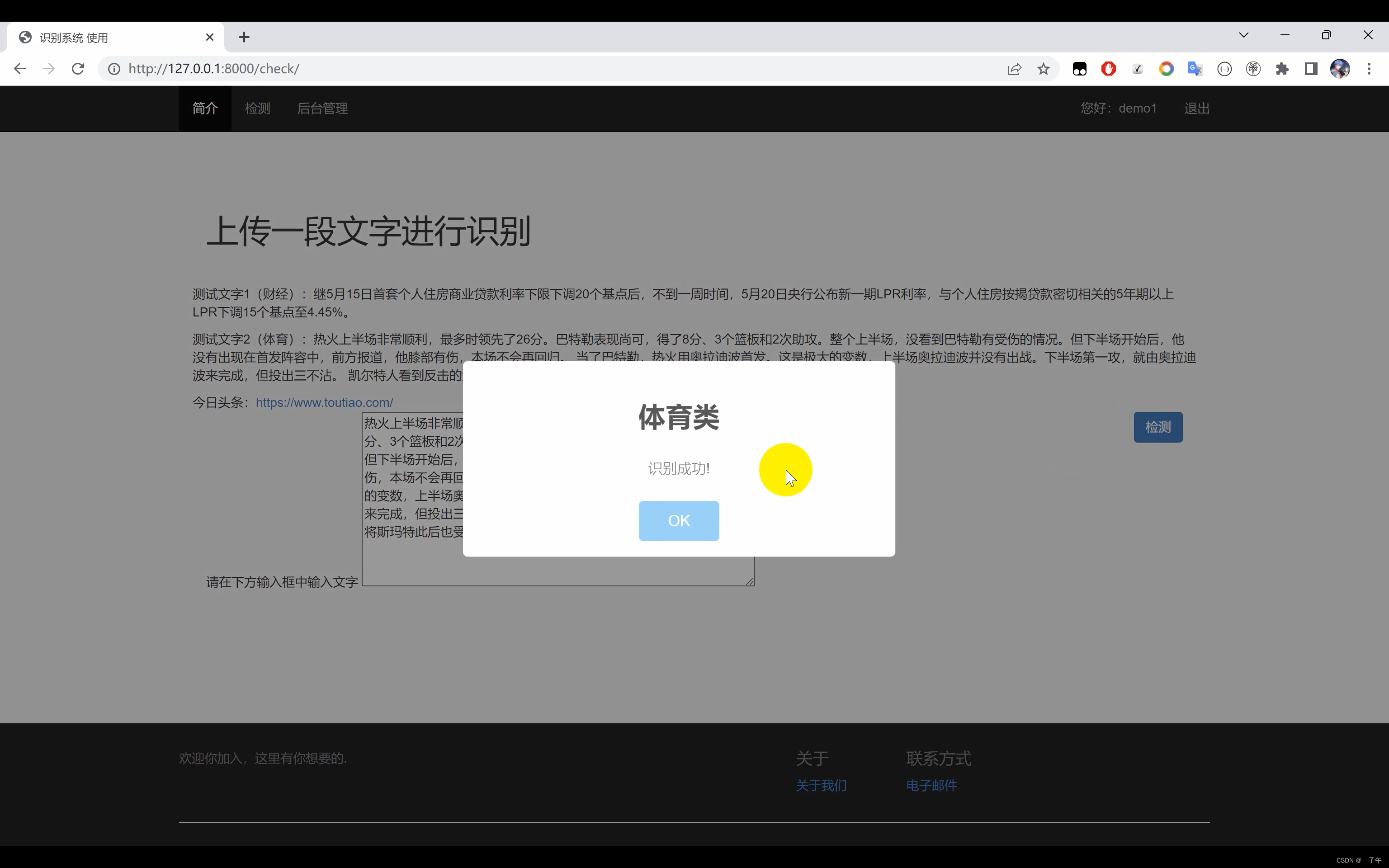
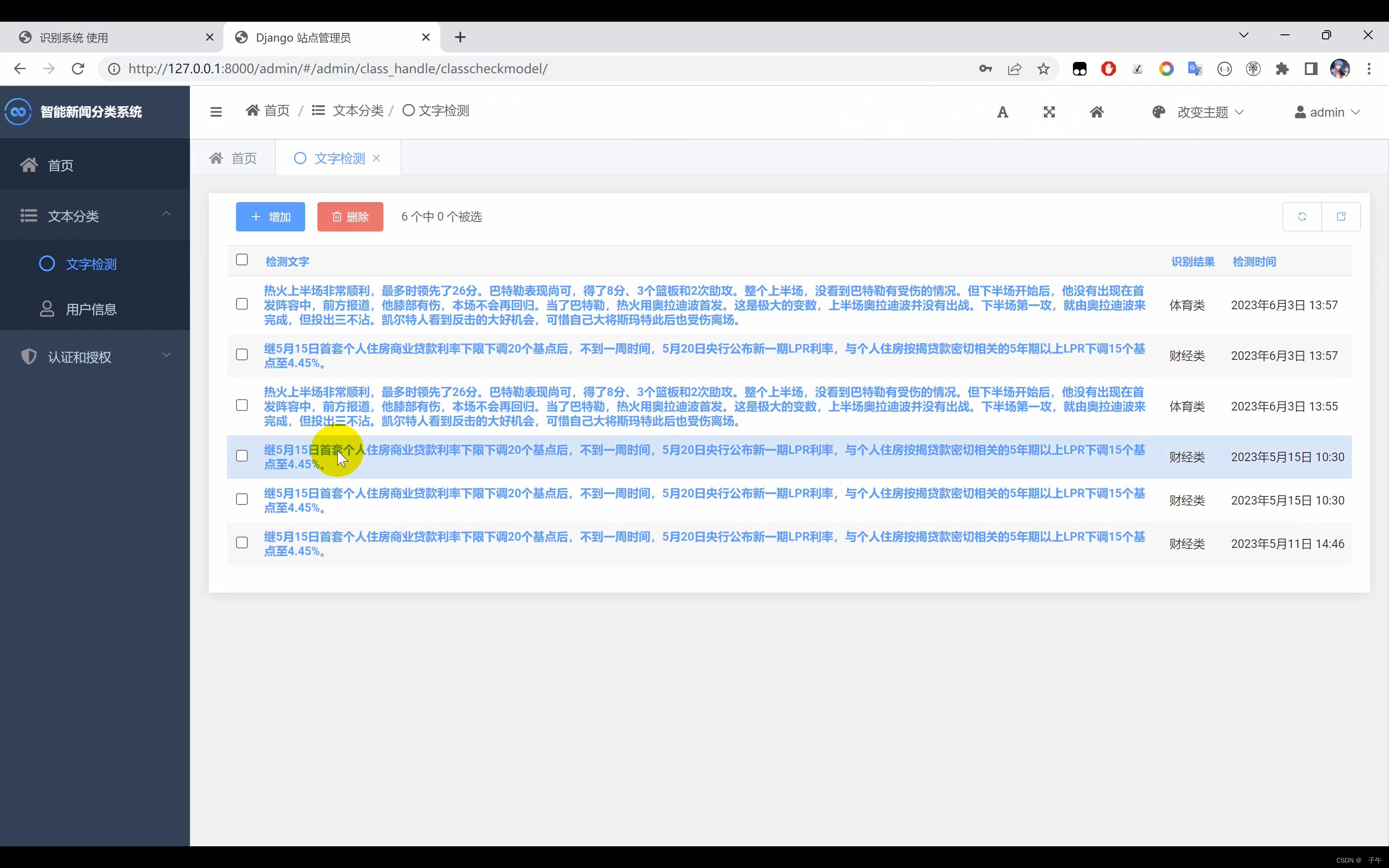
三、演示视频+代码
视频+代码:https://www.yuque.com/ziwu/yygu3z/dm2c902i8cckeayy
四、主要功能
这个系统的核心是一个基于卷积神经网络(CNN)的深度学习模型,通过TensorFlow框架搭建而成。我们知道,CNN是一种强大的模型,最初用于图像识别,但近年来在自然语言处理领域也展现了惊人的性能。我们的系统训练了一个CNN模型,通过对十余种不同种类的文本数据集进行学习,最后得到了一个h5格式的本地模型文件,它可以准确地识别输入文本的种类。
我们选择Python作为主要的开发语言,不仅因为Python的简洁、易学和丰富的开源库,更因为Python在数据科学和机器学习领域的广泛应用。使用Python,我们能更高效地开发和维护系统,同时也能让更多的开发者参与到我们的项目中来。
为了让用户能更方便地使用我们的文本分类系统,我们利用Django开发了一个网页界面。Django是一款开源的Web开发框架,能够帮助我们快速构建高质量的Web应用。在我们的系统中,用户可以在界面中输入一段文字,系统会立即返回该段文字的分类结果。无论你是数据科学家需要处理大量文本数据,还是一位普通用户想要了解你的文本可能属于哪个类别,我们的系统都能为你提供方便、快捷的服务。
通过文本分类系统不仅能够提供精确的分类结果,还具有极高的可扩展性。我们的系统设计师希望这个系统能适应未来的需求,因此在设计时充分考虑了模块化和组件化。这意味着我们的系统可以轻松地添加新的文本种类,或者用新的模型替换现有的模型。这样,无论未来的需求如何变化,我们的系统都能轻松应对。
综上所述,这个全新的文本分类系统是一个将深度学习技术、Python语言和Web应用开发结合在一起的高级工具。它不仅能帮助我们处理和理解海量的文本数据,也为我们打开了新的可能性。如果你有处理文本数据的需求,或者对新的技术感兴趣,欢迎来试用我们的系统。我们相信,你会发现它是一个强大而有用的工具。
五、示例代码
这是一个基本的示例,描述了如何使用Python和TensorFlow训练一个CNN模型进行文本分类,并使用Django创建一个网页应用来使用这个模型。
- 使用TensorFlow训练一个CNN模型:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Conv1D, GlobalMaxPooling1D, Dense
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 假设我们有一些训练数据
texts = [...] # 输入文本数据
labels = [...] # 输入文本对应的类别
# 设置词汇表大小和序列长度
vocab_size = 10000
sequence_length = 100
# 使用Tokenizer进行文本预处理
tokenizer = Tokenizer(num_words=vocab_size)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
data = pad_sequences(sequences, maxlen=sequence_length)
# 创建CNN模型
model = Sequential()
model.add(Embedding(vocab_size, 128, input_length=sequence_length))
model.add(Conv1D(128, 5, activation='relu'))
model.add(GlobalMaxPooling1D())
model.add(Dense(10, activation='softmax')) # 假设我们有10个文本类别
# 编译并训练模型
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(data, labels, epochs=10, validation_split=0.2)
# 保存模型
model.save('text_classification_model.h5')
- 使用Django创建一个Web应用:
首先,你需要在你的Django项目中创建一个新的app。然后,在views.py文件中,你可以加载你的模型并创建一个视图来处理用户的输入。
from django.shortcuts import render
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 加载模型
model = load_model('text_classification_model.h5')
def classify_text(request):
if request.method == 'POST':
text = request.POST['text']
# 对文本进行预处理
sequences = tokenizer.texts_to_sequences([text])
data = pad_sequences(sequences, maxlen=sequence_length)
# 预测文本类别
prediction = model.predict(data)
label = prediction.argmax(axis=-1)
return render(request, 'classification_result.html', {'label': label})
return render(request, 'classify_text.html')
在这个视图中,我们首先检查请求是否是POST请求。如果是,我们从请求中获取用户输入的文本,对其进行预处理,并使用我们的模型进行预测。最后,我们返回一个页面,显示预测的文本类别。
然后,你需要在urls.py文件中添加一个URL模式,以便用户可以访问这个视图:
from django.urls import path
from . import views
urlpatterns = [
path('classify-text/', views.classify_text, name='classify_text'),
]
文本识别分类系统python,基于深度学习的CNN卷积神经网络算法的更多相关文章
- day-16 CNN卷积神经网络算法之Max pooling池化操作学习
利用CNN卷积神经网络进行训练时,进行完卷积运算,还需要接着进行Max pooling池化操作,目的是在尽量不丢失图像特征前期下,对图像进行downsampling. 首先看下max pooling的 ...
- 《Python深度学习》《卷积神经网络的可视化》精读
对于大多数深度学习模型,模型学到的表示都难以用人类可以理解的方式提取和呈现.但对于卷积神经网络来说,我们可以很容易第提取模型学习到的表示形式,并以此加深对卷积神经网络模型运作原理的理解. 这篇文章的内 ...
- 【深度学习系列】卷积神经网络CNN原理详解(一)——基本原理
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度.有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可 ...
- 深度学习笔记 (一) 卷积神经网络基础 (Foundation of Convolutional Neural Networks)
一.卷积 卷积神经网络(Convolutional Neural Networks)是一种在空间上共享参数的神经网络.使用数层卷积,而不是数层的矩阵相乘.在图像的处理过程中,每一张图片都可以看成一张“ ...
- SIGAI深度学习第九集 卷积神经网络3
讲授卷积神经网络面临的挑战包括梯度消失.退化问题,和改进方法包括卷积层.池化层的改进.激活函数.损失函数.网络结构的改 进.残差网络.全卷机网络.多尺度融合.批量归一化等 大纲: 面临的挑战梯度消失问 ...
- 基于深度学习的人脸性别识别系统(含UI界面,Python代码)
摘要:人脸性别识别是人脸识别领域的一个热门方向,本文详细介绍基于深度学习的人脸性别识别系统,在介绍算法原理的同时,给出Python的实现代码以及PyQt的UI界面.在界面中可以选择人脸图片.视频进行检 ...
- 基于深度学习的车型识别系统(Python+清新界面+数据集)
摘要:基于深度学习的车型识别系统用于识别不同类型的车辆,应用YOLO V5算法根据不同尺寸大小区分和检测车辆,并统计各类型数量以辅助智能交通管理.本文详细介绍车型识别系统,在介绍算法原理的同时,给出P ...
- 基于深度学习的智能PCB板缺陷检测系统(Python+清新界面+数据集)
摘要:智能PCB板缺陷检测系统用于智能检测工业印刷电路板(PCB)常见缺陷,自动化标注.记录和保存缺陷位置和类型,以辅助电路板的质检.本文详细介绍智能PCB板缺陷检测系统,在介绍算法原理的同时,给出P ...
- 基于深度学习的人脸识别系统(Caffe+OpenCV+Dlib)【三】VGG网络进行特征提取
前言 基于深度学习的人脸识别系统,一共用到了5个开源库:OpenCV(计算机视觉库).Caffe(深度学习库).Dlib(机器学习库).libfacedetection(人脸检测库).cudnn(gp ...
- 基于深度学习的人脸识别系统(Caffe+OpenCV+Dlib)【一】如何配置caffe属性表
前言 基于深度学习的人脸识别系统,一共用到了5个开源库:OpenCV(计算机视觉库).Caffe(深度学习库).Dlib(机器学习库).libfacedetection(人脸检测库).cudnn(gp ...
随机推荐
- 电商AARRR模型分析(二)—R语言
AARRR模型可以说是用户运营和业务增长非常重要的模型.模型以用户的生命周期为核心,把增长步骤拆分为5个步骤,分别是:获取用户(Acquisition).用户激活(Activiation).用户留存( ...
- kubernetes(k8s)中部署 efk
Kubernetes 开发了一个 Elasticsearch 附加组件来实现集群的日志管理.这是一个 Elasticsearch.Fluentd 和 Kibana 的组合. Elasticsearch ...
- Java 开源项目整合
在JAVA学习过程中,学习到的简单项目,在这里记录下. SSM框架的整合 使用到的框架:SpringMVC + Spring + MyBatis 地址:https://github.com/liyif ...
- day47:Bootstrap
什么是Bootstrap? Bootstrap是一个开源框架,是对html\css\js\jquery等的封装,用法,复制黏贴一把梭. 关于Bootstrap的一些常用网址 网址: https://w ...
- Carla 自动驾驶仿真平台的安装与配置指南
简介 Carla 是一款基于 Python 编写和 UE(虚幻引擎)的开源仿真器,用于模拟自动驾驶车辆在不同场景下的行为和决策.它提供了高度可定制和可扩展的驾驶环境,包括城市.高速公路和农村道路等.C ...
- C++核心知识回顾(自定义数据类型)
复习C++ 类 自定义数据类型最灵活的方式就是使用C++的类结构 现在定义一个货币类型Currency: enum signType{PLUS,MINUS}; class Currency { pub ...
- PyTorch实践模型训练(Torchvision)
模型训练的开发过程可以看作是一套完整的生产流程,这些环节包括: 数据读取.网络设计.优化方法与损失函数的选择以及一些辅助的工具等,TorchVision是一个和PyTorch配合使用的Python包, ...
- Longformer详解——从Self-Attention说开去
1.Longformer的应用场景 为了理解Longformer的原理,我们最好首先从为何需要使用Longformer开始说起.(这里默认各位已经对Self Attention等基础知识有一定的了解) ...
- Swift Codable协议实战:快速、简单、高效地完成JSON和Model转换!
前言 Codable 是 Swift 4.0 引入的一种协议,它是一个组合协议,由 Decodable 和 Encodable 两个协议组成.它的作用是将模型对象转换为 JSON 或者是其它的数据格式 ...
- Godot 4.0 文件系统特性的总结
关于文件系统,官方文档犹抱琵琶半遮面,有一些很独特的特性并没有集中地摆出来,导致用的时候晕头转向. 这里总结了目前我发现的Godot文件系统的一些特性. 这是专门针对导出后的,因为一些操作在编辑器里面 ...