神经网络优化篇:理解指数加权平均数(Understanding exponentially weighted averages)
理解指数加权平均数
回忆一下这个计算指数加权平均数的关键方程。
\({{v}_{t}}=\beta {{v}_{t-1}}+(1-\beta ){{\theta }_{t}}\)
\(\beta=0.9\)的时候,得到的结果是红线,如果它更接近于1,比如0.98,结果就是绿线,如果\(\beta\)小一点,如果是0.5,结果就是黄线。
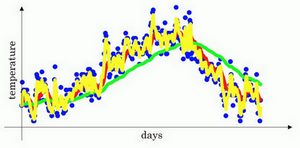
进一步地分析,来理解如何计算出每日温度的平均值。
同样的公式,\({{v}_{t}}=\beta {{v}_{t-1}}+(1-\beta ){{\theta }_{t}}\)
使\(\beta=0.9\),写下相应的几个公式,所以在执行的时候,\(t\)从0到1到2到3,\(t\)的值在不断增加,为了更好地分析,写的时候使得\(t\)的值不断减小,然后继续往下写。
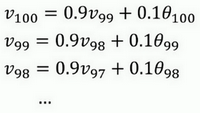
首先看第一个公式,理解\(v_{100}\)是什么?调换一下这两项(\(0.9v_{99}0.1\theta_{100}\)),\(v_{100}= 0.1\theta_{100} + 0.9v_{99}\)。
那么\(v_{99}\)是什么?就代入这个公式(\(v_{99} = 0.1\theta_{99} +0.9v_{98}\)),所以:
\(v_{100} = 0.1\theta_{100} + 0.9(0.1\theta_{99} + 0.9v_{98})\)。
那么\(v_{98}\)是什么?可以用这个公式计算(\(v_{98} = 0.1\theta_{98} +0.9v_{97}\)),把公式代进去,所以:
\(v_{100} = 0.1\theta_{100} + 0.9(0.1\theta_{99} + 0.9(0.1\theta_{98} +0.9v_{97}))\)。
以此类推,如果把这些括号都展开,
\(v_{100} = 0.1\theta_{100} + 0.1 \times 0.9 \theta_{99} + 0.1 \times {(0.9)}^{2}\theta_{98} + 0.1 \times {(0.9)}^{3}\theta_{97} + 0.1 \times {(0.9)}^{4}\theta_{96} + \ldots\)
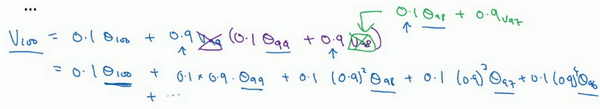
所以这是一个加和并平均,100号数据,也就是当日温度。分析\(v_{100}\)的组成,也就是在一年第100天计算的数据,但是这个是总和,包括100号数据,99号数据,97号数据等等。画图的一个办法是,假设有一些日期的温度,所以这是数据,这是\(t\),所以100号数据有个数值,99号数据有个数值,98号数据等等,\(t\)为100,99,98等等,这就是数日的温度数值。
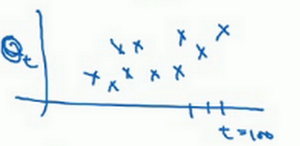
然后构建一个指数衰减函数,从0.1开始,到\(0.1 \times 0.9\),到\(0.1 \times {(0.9)}^{2}\),以此类推,所以就有了这个指数衰减函数。

计算\(v_{100}\)是通过,把两个函数对应的元素,然后求和,用这个数值100号数据值乘以0.1,99号数据值乘以0.1乘以\({(0.9)}^{2}\),这是第二项,以此类推,所以选取的是每日温度,将其与指数衰减函数相乘,然后求和,就得到了\(v_{100}\)。

结果是,稍后详细讲解,不过所有的这些系数(\(0.10.1 \times 0.90.1 \times {(0.9)}^{2}0.1 \times {(0.9)}^{3}\ldots\)),相加起来为1或者逼近1,称之为偏差修正。
最后也许会问,到底需要平均多少天的温度。实际上\({(0.9)}^{10}\)大约为0.35,这大约是\(\frac{1}{e}\),e是自然算法的基础之一。大体上说,如果有\(1-\varepsilon\),在这个例子中,\(\varepsilon=0.1\),所以\(1-\varepsilon=0.9\),\({(1-\varepsilon)}^{(\frac{1}{\varepsilon})}\)约等于\(\frac{1}{e}\),大约是0.34,0.35,换句话说,10天后,曲线的高度下降到\(\frac{1}{3}\),相当于在峰值的\(\frac{1}{e}\)。
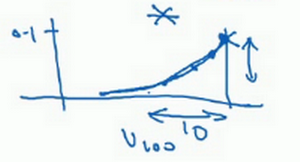
又因此当\(\beta=0.9\)的时候,说仿佛在计算一个指数加权平均数,只关注了过去10天的温度,因为10天后,权重下降到不到当日权重的三分之一。
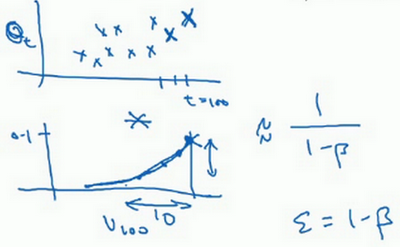
相反,如果,那么0.98需要多少次方才能达到这么小的数值?\({(0.98)}^{50}\)大约等于\(\frac{1}{e}\),所以前50天这个数值比\(\frac{1}{e}\)大,数值会快速衰减,所以本质上这是一个下降幅度很大的函数,可以看作平均了50天的温度。因为在例子中,要代入等式的左边,\(\varepsilon=0.02\),所以\(\frac{1}{\varepsilon}\)为50,由此得到公式,平均了大约\(\frac{1}{(1-\beta)}\)天的温度,这里\(\varepsilon\)代替了\(1-\beta\),也就是说根据一些常数,能大概知道能够平均多少日的温度,不过这只是思考的大致方向,并不是正式的数学证明。
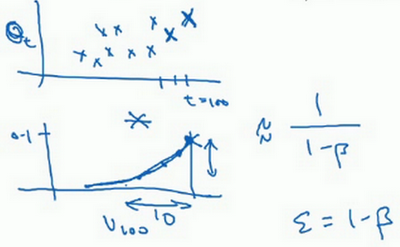
最后讲讲如何在实际中执行,还记得吗?一开始将\(v_{0}\)设置为0,然后计算第一天\(v_{1}\),然后\(v_{2}\),以此类推。
现在解释一下算法,可以将\(v_{0}\),\(v_{1}\),\(v_{2}\)等等写成明确的变量,不过在实际中执行的话,要做的是,一开始将\(v\)初始化为0,然后在第一天使\(v:= \beta v + (1 - \beta)\theta_{1}\),然后第二天,更新\(v\)值,\(v: = \beta v + (1 -\beta)\theta_{2}\),以此类推,有些人会把\(v\)加下标,来表示\(v\)是用来计算数据的指数加权平均数。
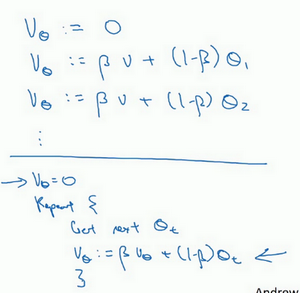
再说一次,但是换个说法,\(v_{\theta} =0\),然后每一天,拿到第\(t\)天的数据,把\(v\)更新为\(v: = \beta v_{\theta} + (1 -\beta)\theta_{t}\)。
指数加权平均数公式的好处之一在于,它占用极少内存,电脑内存中只占用一行数字而已,然后把最新数据代入公式,不断覆盖就可以了,正因为这个原因,其效率,它基本上只占用一行代码,计算指数加权平均数也只占用单行数字的存储和内存,当然它并不是最好的,也不是最精准的计算平均数的方法。如果要计算移动窗,直接算出过去10天的总和,过去50天的总和,除以10和50就好,如此往往会得到更好的估测。但缺点是,如果保存所有最近的温度数据,和过去10天的总和,必须占用更多的内存,执行更加复杂,计算成本也更加高昂。
神经网络优化篇:理解指数加权平均数(Understanding exponentially weighted averages)的更多相关文章
- 【零基础】神经网络优化之Adam
一.序言 Adam是神经网络优化的另一种方法,有点类似上一篇中的“动量梯度下降”,实际上是先提出了RMSprop(类似动量梯度下降的优化算法),而后结合RMSprop和动量梯度下降整出了Adam,所以 ...
- Tensorflow学习:(三)神经网络优化
一.完善常用概念和细节 1.神经元模型: 之前的神经元结构都采用线上的权重w直接乘以输入数据x,用数学表达式即,但这样的结构不够完善. 完善的结构需要加上偏置,并加上激励函数.用数学公式表示为:.其中 ...
- 神经网络优化算法:梯度下降法、Momentum、RMSprop和Adam
最近回顾神经网络的知识,简单做一些整理,归档一下神经网络优化算法的知识.关于神经网络的优化,吴恩达的深度学习课程讲解得非常通俗易懂,有需要的可以去学习一下,本人只是对课程知识点做一个总结.吴恩达的深度 ...
- zz图像、神经网络优化利器:了解Halide
动图示例实在太好 图像.神经网络优化利器:了解Halide Oldpan 2019年4月17日 0条评论 1,327次阅读 3人点赞 前言 Halide是用C++作为宿主语言的一个图像处理相 ...
- Halide视觉神经网络优化
Halide视觉神经网络优化 概述 Halide是用C++作为宿主语言的一个图像处理相关的DSL(Domain Specified Language)语言,全称领域专用语言.主要的作用为在软硬层面上( ...
- java提高篇-----理解java的三大特性之封装
在<Think in java>中有这样一句话:复用代码是Java众多引人注目的功能之一.但要想成为极具革命性的语言,仅仅能够复制代码并对加以改变是不够的,它还必须能够做更多的事情.在这句 ...
- 理解LSTM网络--Understanding LSTM Networks(翻译一篇colah's blog)
colah的一篇讲解LSTM比较好的文章,翻译过来一起学习,原文地址:http://colah.github.io/posts/2015-08-Understanding-LSTMs/ ,Posted ...
- 神经网络优化算法:Dropout、梯度消失/爆炸、Adam优化算法,一篇就够了!
1. 训练误差和泛化误差 机器学习模型在训练数据集和测试数据集上的表现.如果你改变过实验中的模型结构或者超参数,你也许发现了:当模型在训练数据集上更准确时,它在测试数据集上却不⼀定更准确.这是为什么呢 ...
- Task6.PyTorch理解更多神经网络优化方法
1.了解不同优化器 2.书写优化器代码3.Momentum4.二维优化,随机梯度下降法进行优化实现5.Ada自适应梯度调节法6.RMSProp7.Adam8.PyTorch种优化器选择 梯度下降法: ...
- [Math]理解卡尔曼滤波器 (Understanding Kalman Filter) zz
1. 卡尔曼滤波器介绍 卡尔曼滤波器的介绍, 见 Wiki 这篇文章主要是翻译了 Understanding the Basis of the Kalman Filter Via a Simple a ...
随机推荐
- Springboot+Mybatis+Mybatisplus 框架中增加自定义分页插件和sql 占位符修改插件
一.Springboot简介 springboot 是当下最流行的web 框架,Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程 ...
- Unity3D 选择焦点切换
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- inventory 主机清单
inventory 主机清单 //Inventory支持对主机进行分组,每个组内可以定义多个主机,每个主机都可以定义在任何一个或多个主机组内. //如果是名称类似的主机,可以使用列表的方式标识各个主机 ...
- tailwindcss 选型,以及vue配置使用
一.为什么选择tailwindcss? Tailwind CSS 是一个受欢迎的.功能丰富的CSS框架,它与传统的CSS框架(如Bootstrap)有些不同.以下是一些人们通常对于Tailwind C ...
- java泛型<? extends E>和<? super E>的区别和适用场景
<? extends E>是Upper Bound(上限)的通配符,用来限制元素类型的上限,如: List<? extends Fruit> fruits; 表示集合中的元素的 ...
- Apache Hudi Timeline:支持 ACID 事务的基础
Apache Hudi 维护在给定表上执行的所有操作的Timeline(时间线),以支持以符合 ACID 的方式高效检索读取查询的数据. 在写入和表服务期间也会不断查阅时间线,这是表正常运行的关键. ...
- 虚拟机centos7上安装docker+jenkins
虚拟机centos7上安装docker+jenkins 学习某册子的CICD时,安装了docker和jenkins,记录的安装过程和中间碰到的问题. 使用的虚拟机为Parallels Desktop, ...
- [洛谷P8867] [NOIP2022] 建造军营
[NOIP2022] 建造军营 题目描述 A 国与 B 国正在激烈交战中,A 国打算在自己的国土上建造一些军营. A 国的国土由 \(n\) 座城市组成,\(m\) 条双向道路连接这些城市,使得任意两 ...
- 第一章 JavaEE应用和开发环境
1.1 java EE应用概述 1.java EE的分层模型 数据库--[提供持久化服务]-->Domain Object层 --[封装]--〉DAO层--[提供数据访问服务]-->业务逻 ...
- LeetCode 503:下一个更大的元素|| (单调栈 or 线段树)
解题思路: 1.单调栈:因为是循环数组,因此把数组复制三遍,ans 数组复制为2倍长,维护一个单调非递增的栈,栈保存的元素是元组(a[i] , i ),如果后面的值有比栈顶元素的值大,栈顶元素出栈,更 ...