为什么MySQL单表不能超过2000万行?
摘要:MySQL一张表最多能存多少数据?
本文分享自华为云社区《为什么MySQL单表不能超过2000万行?》,作者: GaussDB 数据库 。
最近看到一篇《我说MySQL每张表最好不要超过2000万数据,面试官让我回去等通知》的文章,非常有趣。
文中提到,他朋友在面试的过程中说,自己的工作就是把用户操作信息存到MySQL里,因为数据量超大(5000万条左右),需要每天定时生成3张表,然后将数据取模分别存到这三张表里。
下面是两人的对话:

面试后续暂且不论,不过,互联网江湖上的确流传着一个说法:单表数据量超过500万行时就要进行分表分库,已经超过2000万行时MySQL的性能就会急剧下降。
那么,MySQL一张表最多能存多少数据?
今天我们就从技术层面剖析一下,MySQL单表数据不能过大的根本原因是什么?
猜想一:是索引深度吗?
很多人认为:数据量超过500万行或2000万行时,引起B+tree的高度增加,延长了索引的搜索路径,进而导致了性能下降。事实果真如此吗?
我们先理一下关系,MySQL采用了索引组织表的形式组织数据,叶子节点存储数据,非叶子节点存储主键与页面号的映射关系。若用户的主键长度是8字节时,MySQL中页面偏移占4个字节,在非叶子节点的时候实际上是8+4=12个字节,12个字节表示一个页面的映射关系。
MySQL默认是16K的页面,抛开它的配置header,大概就是15K,因此,非叶子节点的索引页面可放15*1024/12=1280条数据,按照每行1K计算,每个叶子节点可以存15条数据。同理,三层就是15*1280*1280=24576000条数据。只有数据量达到24576000条时,深度才会增加为4,所以,索引深度没有那么容易增加,详细数据可参考下表:

搜索路径延长导致性能下降的说法,与当时的机械硬盘和内存条件不无关系。
之前机械硬盘的IOPS在100左右,而现在普遍使用的SSD的IOPS已经过万,之前的内存最大几十G,现在服务器内存最大可达到TB级。
因此,即使深度增加,以目前的硬件资源,IO也不会成为限制MySQL单表数据量的根本性因素。
那么,限制MySQL单表不能过大的根本性因素是什么?
猜想二:是SMO无法并发吗?
我们可以尝试从MySQL所采用的存储引擎InnoDB本身来探究一下。
大家知道InnoDB引擎使用的是索引组织表,它是通过索引来组织数据的,而它采用B+tree作为索引的数据结构。
B+Tree操作非原子,所以当一个线程做结构调整(SMO,Struction-Modification-Operation)时一般会涉及多个节点的改动。
SMO动作过程中,此时若有另一个线程进来可能会访问到错误的B+Tree结构,InnoDB为了解决这个问题采用了乐观锁和悲观锁的并发控制协议。
InnoDB对于叶子节点的修改操作如下:
方式一,先采用乐观锁的方式尝试进行修改
对根节点加S锁(shared lock,叫共享锁,也称读锁),依次对非叶子节点加S锁。
如果叶子节点的修改不会引起B+Tree结构变动,如分裂、合并等操作,那么只需要对叶子节点进行加X锁(exclusive lock,叫排他锁,也称为写锁)即可完成修改。如下图中所示 :
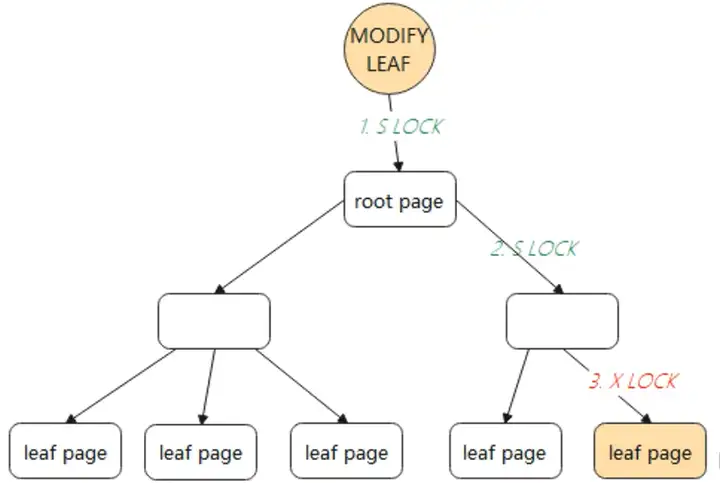
方式二,采用悲观锁的方式
如果对叶子结点的修改会触发SMO,那么会采用悲观锁的方式。
采用悲观锁,需要重新遍历B+Tree,对根节点加全局SX锁(SX锁是行锁),然后从根节点到叶子节点可能修改的节点加X锁。
在整个SMO过程中,根节点始终持有SX锁(SX锁表示有意向修改这个保护的范围,SX锁与SX锁、X锁冲突,与S锁不冲突),此时其他的SMO则需要等待。
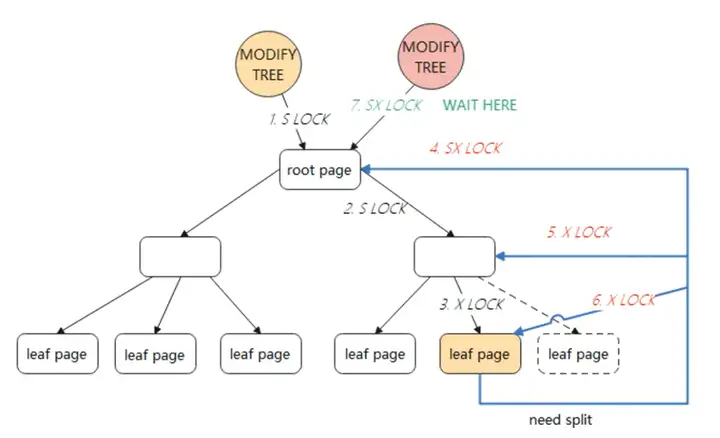
因此,InnoDB对于简单的主键查询比较快,因为数据都存储在叶子节点中,但对于数据量大且改操作比较多的TP型业务,并发会有很严重的瓶颈问题。
在对叶子节点的修改操作中,InnoDB可以实现较好的1与1、1与2的并发,但是无法解决2的并发。因为在方式2中,根节点始终持有SX锁,必须串行执行,等待上一个SMO操作完成。这样在具有大量的SMO操作时,InnoDB的B+Tree实现就会出现很严重的性能瓶颈。
解决方案
目前业界有一个更好的方案B-Link Tree,与B+Tree相比,B-Link Tree优化了B+Tree结构调整时的锁粒度,只需要逐层加锁,无需对root节点加全局锁。因此,可以做到在SMO过程中写操作的并发执行,保持高并发下性能的稳定。
B-Link Tree主要改进点有2个:
1.中间节点增加link指针,指向右兄弟节点;
2.每个节点内增加字段high key,存储该节点中最大的key值。
新增的link指针是为了解决SMO过程中并发写的问题,在SMO过程中,B-Link Tree对修改节点逐层加锁,修改完一层即可放锁,然后去加上一层节点的锁继续修改。这样在InnoDB引擎中被SMO阻塞的写操作可以有机会在SMO操作过程中并发进行。
如下图所示,在节点2分裂为节点2和4的过程中,只需要在最后一步将父节点1指向新节点4时,对父节点1加锁,其他操作均无需对父节点加锁,更无需对root节点加锁,因此,大大提升了SMO过程中写操作的并发度。
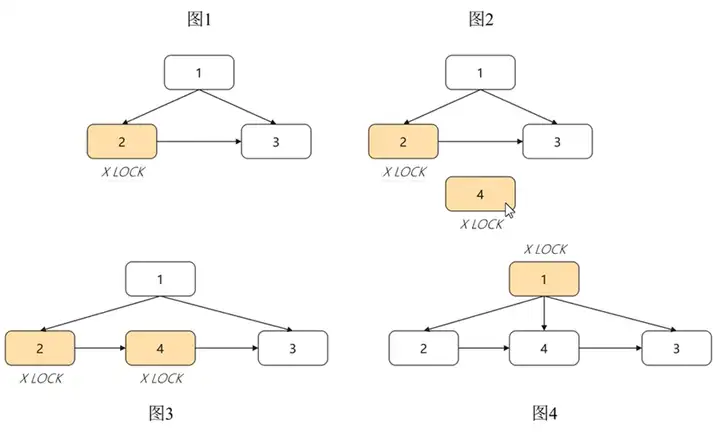
由此可见,与B+Tree全局加锁对比,B-Link Tree在高并发操作下的性能是显著优于B+Tree的。GaussDB当前采用的就是B-Link Tree索引数据结构。
InnoDB的索引组织表更容易触发SMO
索引组织表的叶子节点,存储主键以及应对行的数据,InnoDB默认页面为16K,若每行数据的大小为1000字节,每个叶子节点仅能存储16行数据。
在索引组织表中,当叶子节点的扇出值过低时,SMO的触发将更加频繁,进而放大了SMO无法并发写的缺陷。
目前业界有一个堆组织表的数据组织方案,也是华为云数据库GaussDB采用的方案。它的叶子节点存储索引键以及对应的行指针(所在的页面编号及页内偏移),堆组织表叶子节点可以存更多的数据,分析可得在同样的数据量与业务并发量下,堆组织表会比索引组织表发生SMO概率低许多。
性能对比
在8U32G的两台服务器分别搭建了MySQL(B+Tree和索引组织表)与GaussDB(B-Link Tree和堆组织表)的环境,进行了如下性能验证:
实验场景:在基础表的场景上,测试增量随机插入性能。
1.基础表总大小10G,包含主键随机分布的1000w行数据,每行数据1k;
2.插入主键随机分布的1000w行数据,每行数据大小1k,测试并发插入性能。
结论:随着并发数的上升,GaussDB能稳步提升系统的TPS,而MySQL并发数的提高并不能带来TPS的显著提升。
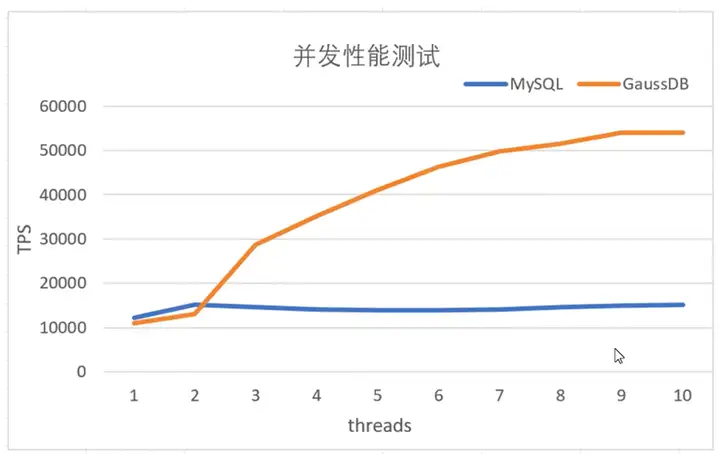
综上所述,MySQL无法支持大数据量下并发修改的根本原因,是由于其索引并发控制协议的缺陷造成的,而MySQL选择索引组织表,又放大了这一缺陷。所以,开源MySQL数据库更适用于主键查询为主的简单业务场景,如互联网类应用,对于复杂的商业场景限制比较明显。
相比之下 ,采用B-Link Tree和堆组织表的GaussDB数据库在性能和场景应用方面更胜一筹。
为什么MySQL单表不能超过2000万行?的更多相关文章
- MySQL单表存储上限
-------------- mysql的上限不是单纯的根据内容的大小决定的.跟数据的条数也有关系. 可以把mysql理解成一个服务器.处理数据的通道的流量有限.(这段瞎编的) MySQL本身并没有对 ...
- MySQL单表数据不要超过500万行:是经验数值,还是黄金铁律?
本文阅读时间大约3分钟. 梁桂钊 | 作者 今天,探讨一个有趣的话题:MySQL 单表数据达到多少时才需要考虑分库分表?有人说 2000 万行,也有人说 500 万行.那么,你觉得这个数值多少才合适呢 ...
- MySQL单表数据不超过500万:是经验数值,还是黄金铁律?
今天,探讨一个有趣的话题:MySQL 单表数据达到多少时才需要考虑分库分表?有人说 2000 万行,也有人说 500 万行.那么,你觉得这个数值多少才合适呢? 曾经在中国互联网技术圈广为流传着这么一个 ...
- MySQL单表最大记录数不能超过多少?
MySQL单表最大记录数不能超过多少? 很多人困惑这个问题.其实,MySQL本身并没有对单表最大记录数进行限制,这个数值取决于你的操作系统对单个文件的限制本身. 从性能角度来讲,MySQL单表数据不要 ...
- 单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
https://github.com/alibaba/p3c/blob/master/阿里巴巴Java开发手册(详尽版).pdf 单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表 ...
- python 3 mysql 单表查询
python 3 mysql 单表查询 1.准备表 company.employee 员工id id int 姓名 emp_name varchar 性别 sex enum 年龄 age int 入职 ...
- Mysql 单表查询where初识
Mysql 单表查询where初识 准备数据 -- 创建测试库 -- drop database if exists student_db; create database student_db ch ...
- MySQL单表最大限制
想把一个项目的数据库导出来,然后倒入到自己熟悉的MySQL数据库中进行运行和调试.导出来后,发现sql文件整整有12G多大,忽然想起来,MySQL好像有个叫做容量限制的神奇特性,但是忘了上限是多少了, ...
- mysql单表大小的限制
mysql单表大小的限制一.MySQL数据库的MyISAM存储 引擎单表大小限制已经不是有MySQL数据库本身来决定(限制扩大到64pb),而是由所在主机的OS上面的文件系统来决定了.在mysql5. ...
- MySQL单表多字段模糊查询
今天工作时遇到一个功能问题:就是输入关键字搜索的字段不只一个字段,比如 我输入: 超天才 ,需要检索出 包含这个关键字的 name . company.job等多个字段.在网上查询了一会就找到了答案. ...
随机推荐
- MySQL的驱动表与被驱动表
驱动表与被驱动表的含义 在MySQL中进行多表联合查询时,MySQL会通过驱动表的结果集作为基础数据,在被驱动表中匹配对应的数据,匹配成功合并后的临时表再作为驱动表或被驱动表继续与第三张表进行匹配合并 ...
- Python - 字典3
修改字典项 您可以通过引用其键名来更改特定项的值: 示例,将 "year" 更改为 2018: thisdict = { "brand": "Ford ...
- k8s-单节点升级为集群(高可用)
单master节点升级为高可用集群 对于生产环境来说,单节点master风险太大了. 非常有必要做一个高可用的集群,这里的高可用主要是针对控制面板来说的,比如 kube-apiserver.etcd. ...
- Atcoder Regular Contest 165
B. Sliding Window Sort 2 被题目名里的滑动窗口误导了,于是卡 B 40min /fn Description 给定长度为 \(n\) 的排列 \(P\) 和一个整数 \(K\) ...
- webpack配置打包
一.webpack基本安装 1.创建webpack项目目录如webpackDemo,并进入webpackDemo; 2. 在node已经安装的前提下,打开命令行控制器,输入如下命令: npm init ...
- KMeans算法全面解析与应用案例
本文深入探讨了KMeans聚类算法的核心原理.实际应用.优缺点以及在文本聚类中的特殊用途,为您在聚类分析和自然语言处理方面提供有价值的见解和指导. 关注TechLead,分享AI全维度知识.作者拥有1 ...
- CDQ分治(初步入门)
CDQ分治 CDQ分治,传说中是一个神犇创造的算法. 在了解这种算法之前,我们有必要了解一下一种基本的思想:分治. 分治介绍 分而治之,将原问题不断划分成若干个子问题,直到子问题规模小到足以直接解决 ...
- Spring Cloud 整合
前言 玩SpringCloud之前最好懂SpringBoot,别搞撑死骆驼的事.Servlet整一下变成Spring:SSM封装.加入东西就变为SpringBoot:SpringBoot再封装.加入东 ...
- 主界面(零基础适合小白)基础javaweb前端项目实战【包含增删改查,mysql】三
首先编写sp文件(index.jsp) <%@ page contentType="text/html;charset=UTF-8" language="java& ...
- top命令和ps命令
top 命令和 ps 命令 ps 命令 ps 命令查看系统的瞬时信息.通常使用ps -ef | grep 进程名, -e 代表显示所有进程,-f 表示做一个更为完整的输出.经常使用这个命令获得进程的 ...