Nebula Graph 源码解读系列 | Vol.01 Nebula Graph Overview

上篇序言中我们讲述了源码解读系列的由来,在 Nebula Graph Overview 篇中我们将带你了解下 Nebula Graph 的架构以及代码仓分布、代码结构和模块规划。
1. 架构
Nebula Graph 是一个开源的分布式图数据库。Nebula采用存储计算分离的设计,解耦存储与计算。同时在数据库内核之外,我们也提供了很多周边工具,比如数据导入,监控,部署,可视化,图计算等等。
Nebula 设计请参见《图数据库综述与 Nebula 在图数据库设计的实践》。
整体架构设计如下图所示:
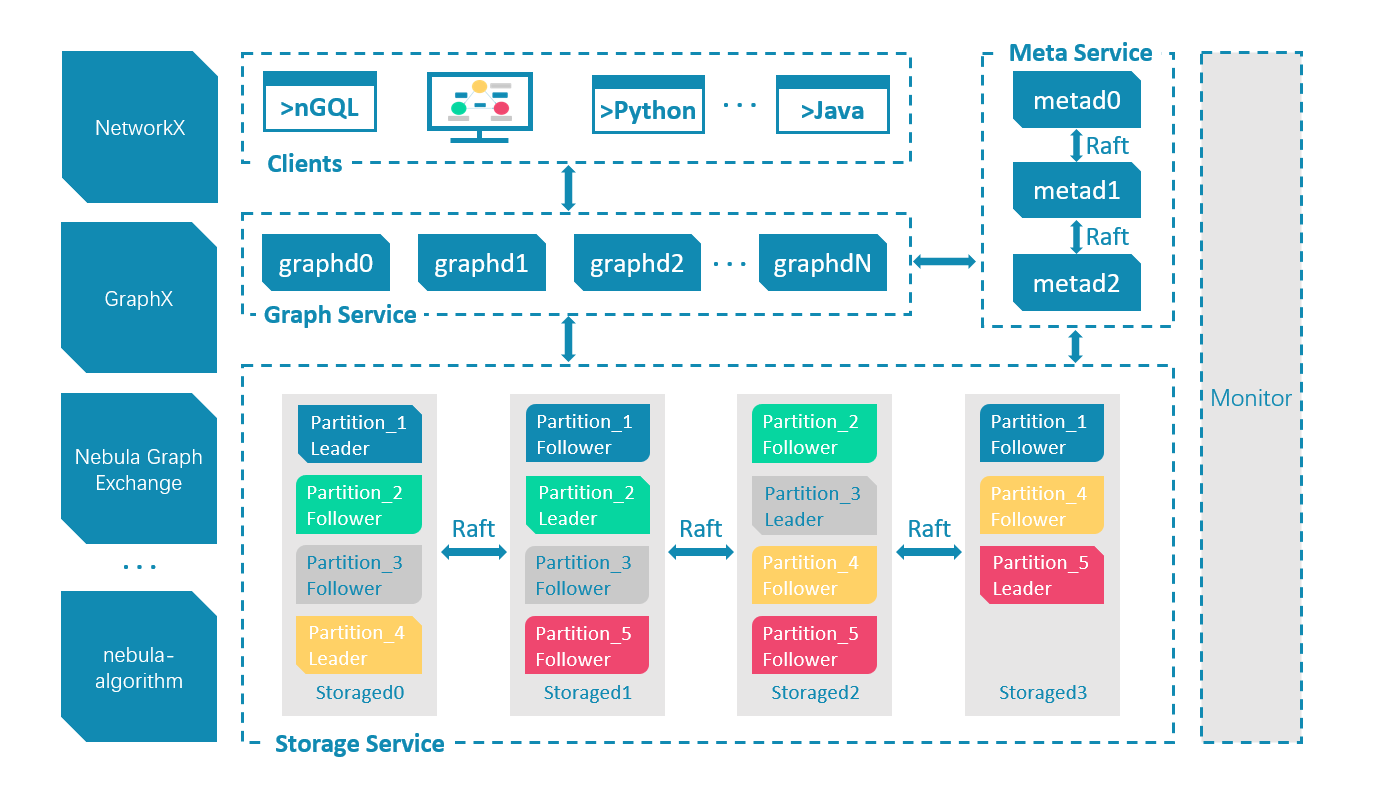
查询引擎采用无状态设计,可轻松实现横向扩展,分为语法分析、语义分析、优化器、执行引擎等几个主要部分。
详细设计参见《图数据库的查询引擎设计》,《初识 Nebula Graph 2.0 Query Engine》。
查询引擎架构设计如下图所示:
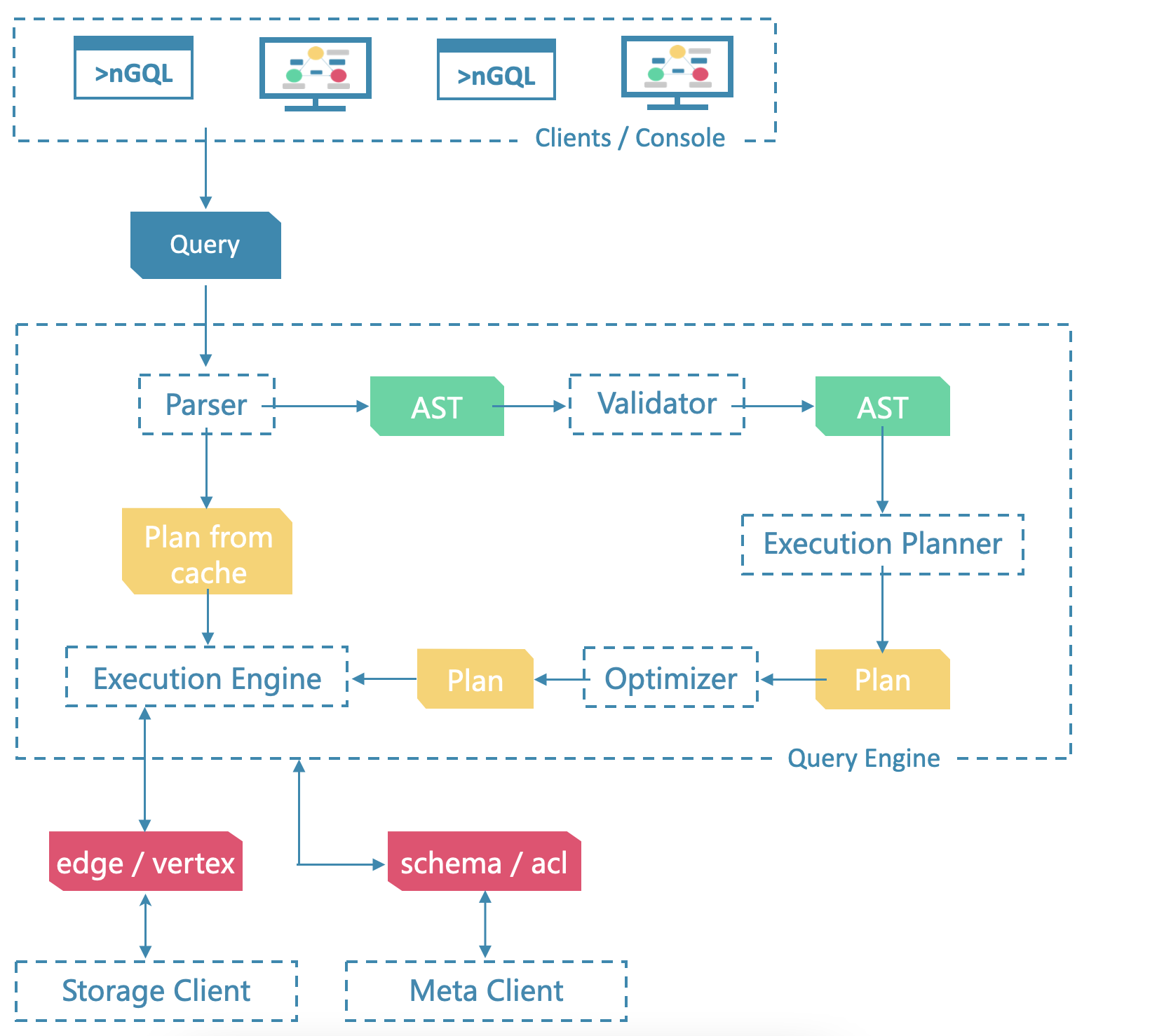
Storage 包含两个部分, 一是 meta 相关的存储, 我们称之为 Meta Service ,另一个是 data 相关的存储, 我们称之为 Storage Service。
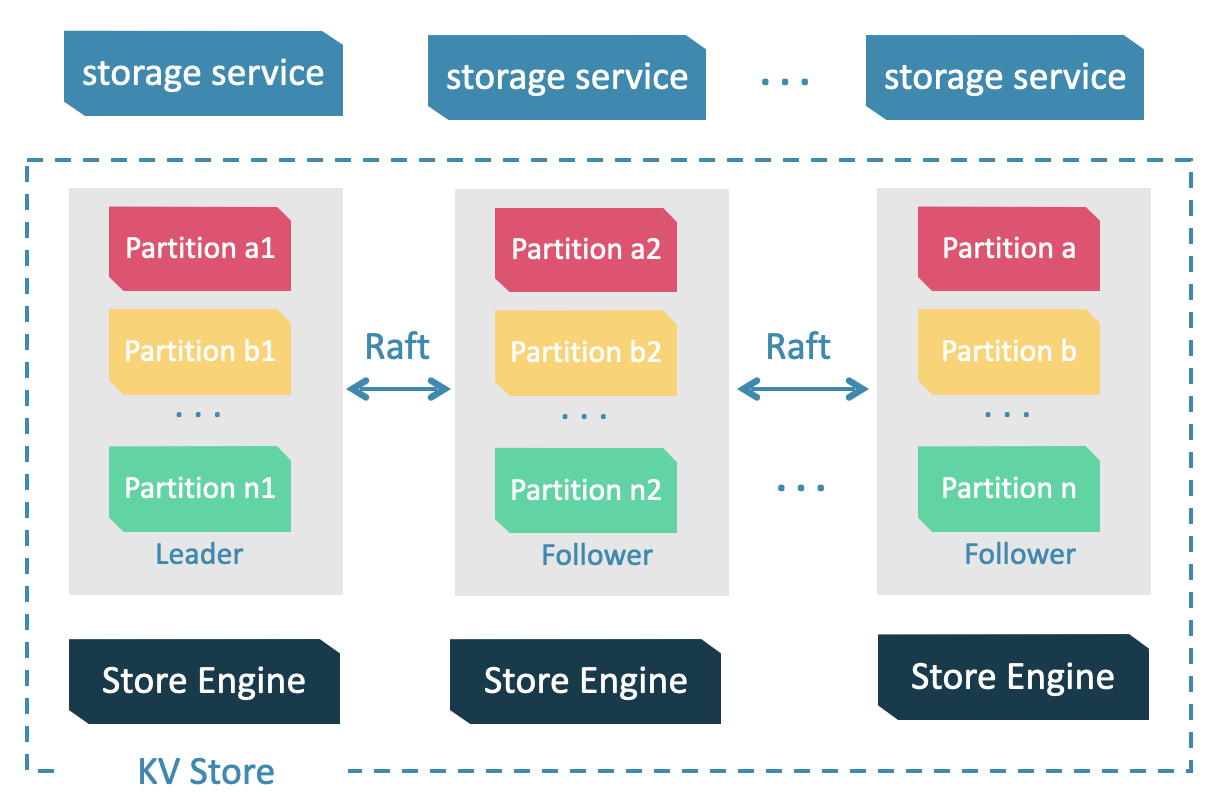
Storage Service 共有三层:最底层是 Store Engine;之上便是我们的 Consensus 层,实现了 Multi Group Raft;最上层,便是我们的 Storage interfaces,这一层定义了一系列和图相关的 API。
详细设计参见《图数据库的存储设计》 。
存储引擎架构设计如下图所示:
2. 代码仓库概览
欢迎来到 vesoft 代码仓库(vesoft 为图数据库 Nebula Graph 开发商)。
目前 Nebula 产品架构中,包含了图数据库内核,客户端,工具,测试框架,编译,可视化,监控等。
本文的主要目的是简单介绍 Nebula Graph 主要 Repo 的代码结构,并说明各个模块的基本功能。后续会有更多的详细设计说明。希望能够帮助到社区读者更好地理解 Nebula Graph,并能够为 Nebula 社区做出自己的贡献,比如提交 Feature,修复 Bug,提交文档等。
以下列出 vesoft-inc 仓库中大部分的代码仓库:
- nebula:Nebula 1.0 的内核代码
- nebula graph:Nebula 2.0 查询计算引擎
- nebula storage:Nebula 2.0 存储引擎
- nebula common:Nebula 2.0 内核工具包
- Nebula Clients
- nebula-java:Java 客户端
- nebula-cpp:CPP 客户端
- nebula-go:Go 客户端
- nebula-python:Python 客户端
- Nebula Tools
- nebula-importer:基于 Go 客户端实现的高性能数据导入工具
- nebula-spark-utils:收录工具 Spark Connector、Exchange、Algorithm
- nebula-br:备份恢复工具
- nebula-ansible、nebula-operator:部署工具
- Nebula Test
- nebula-bench:压力与性能测试工程
- nebula-chaos:混沌测试工程
- Compiling
- nebula-third-party:Nebula Graph 图数据库内核依赖的第三方包
- nebula-gears:Nebula Graph 图数据库内核工具链
- nebula-graph-studio:Nebula Graph 可视化工具
3. 代码结构及模块说明
3.1 Nebula Graph
├── cmake
├── conf
├── LICENSES
├── package
├── resources
├── scripts
├── src
│ ├── context
│ ├── daemons
│ ├── executor
│ ├── optimizer
│ ├── parser
│ ├── planner
│ ├── scheduler
│ ├── service
│ ├── session
│ ├── stats
│ ├── util
│ ├── validator
│ └── visitor
└── tests
├── admin
├── bench
├── common
├── data
├── job
├── maintain
├── mutate
├── query
└── tck
- conf/:查询引擎配置文件目录
- package/:graph 打包脚本
- resources/:资源文件
- scripts/:启动脚本
- src/:查询引擎源码目录
- src/context/:查询的上下文信息,包括 AST(抽象语法树),Execution Plan(执行计划),执行结果以及其他计算相关的资源。
- src/daemons/:查询引擎主进程
- src/executor/:执行器,各个算子的实现
- src/optimizer/:RBO(基于规则的优化)实现,以及优化规则
- src/parser/:词法解析,语法解析,:AST结构定义
- src/planner/:算子,以及执行计划生成
- src/scheduler/:执行计划的调度器
- src/service/:查询引擎服务层,提供鉴权,执行 Query 的接口
- src/session/:Session 管理
- src/stats/:执行统计,比如 P99、慢查询统计等
- src/util/:工具函数
- src/validator/:语义分析实现,用于检查语义错误,并进行一些简单的改写优化
- src/visitor/:表达式访问器,用于提取表达式信息,或者优化
- tests/:基于 BDD 的集成测试框架,测试所有 Nebula Graph 提供的功能
3.2 Nebula Storage
├── cmake
├── conf
├── docker
├── docs
├── LICENSES
├── package
├── scripts
└── src
├── codec
├── daemons
├── kvstore
├── meta
├── mock
├── storage
├── tools
├── utils
└── version
- conf/:存储引擎配置文件目录
- package/:storage 打包脚本
- scripts/:启动脚本
- src/:存储引擎源码目录
- src/codec/:序列化反序列化工具
- src/daemons/:存储引擎和元数据引擎主进程
- src/kvstore/:基于 raft 的分布式 KV 存储实现
- src/meta/:基于 KVStore 的元数据管理服务实现,用于管理元数据信息,集群管理,长耗时任务管理等
- src/storage/:基于 KVStore 的图数据存储引擎实现
- src/tools/:一些小工具实现
- src/utils/:代码工具函数
3.3 Nebula Common
├── cmake
│ └── nebula
├── LICENSES
├── src
│ └── common
│ ├── algorithm
│ ├── base
│ ├── charset
│ ├── clients
│ ├── concurrent
│ ├── conf
│ ├── context
│ ├── cpp
│ ├── datatypes
│ ├── encryption
│ ├── expression
│ ├── fs
│ ├── function
│ ├── graph
│ ├── hdfs
│ ├── http
│ ├── interface
│ ├── meta
│ ├── network
│ ├── plugin
│ ├── process
│ ├── session
│ ├── stats
│ ├── test
│ ├── thread
│ ├── thrift
│ ├── time
│ ├── version
│ └── webservice
└── third-party
Nebula Common 仓库代码是 Nebula 内核代码的工具包,提供一些常用工具的高效实现。一些常用工具包相信各位工程师一定也是了然于心。这里只对其中和图数据库密切相关的目录进行说明。
- src/common/clients/:meta,storage 客户端的 CPP 实现
- src/common/datatypes/:Nebula Graph 中数据类型及计算的定义,比如 string,int,bool,float,Vertex,Edge 等。
- rc/common/expression/:nGQL 中表达式的定义
- src/common/function/:nGQL 中的函数的定义
- src/common/interface/:graph、meta、storage 服务的接口定义
以上为本篇文章的介绍内容。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
Nebula Graph 源码解读系列 | Vol.01 Nebula Graph Overview的更多相关文章
- swoft| 源码解读系列二: 启动阶段, swoft 都干了些啥?
date: 2018-8-01 14:22:17title: swoft| 源码解读系列二: 启动阶段, swoft 都干了些啥?description: 阅读 sowft 框架源码, 了解 sowf ...
- Alamofire源码解读系列(二)之错误处理(AFError)
本篇主要讲解Alamofire中错误的处理机制 前言 在开发中,往往最容易被忽略的内容就是对错误的处理.有经验的开发者,能够对自己写的每行代码负责,而且非常清楚自己写的代码在什么时候会出现异常,这样就 ...
- Alamofire源码解读系列(四)之参数编码(ParameterEncoding)
本篇讲解参数编码的内容 前言 我们在开发中发的每一个请求都是通过URLRequest来进行封装的,可以通过一个URL生成URLRequest.那么如果我有一个参数字典,这个参数字典又是如何从客户端传递 ...
- Alamofire源码解读系列(三)之通知处理(Notification)
本篇讲解swift中通知的用法 前言 通知作为传递事件和数据的载体,在使用中是不受限制的.由于忘记移除某个通知的监听,会造成很多潜在的问题,这些问题在测试中是很难被发现的.但这不是我们这篇文章探讨的主 ...
- Alamofire源码解读系列(五)之结果封装(Result)
本篇讲解Result的封装 前言 有时候,我们会根据现实中的事物来对程序中的某个业务关系进行抽象,这句话很难理解.在Alamofire中,使用Response来描述请求后的结果.我们都知道Alamof ...
- Alamofire源码解读系列(六)之Task代理(TaskDelegate)
本篇介绍Task代理(TaskDelegate.swift) 前言 我相信可能有80%的同学使用AFNetworking或者Alamofire处理网络事件,并且这两个框架都提供了丰富的功能,我也相信很 ...
- Alamofire源码解读系列(七)之网络监控(NetworkReachabilityManager)
Alamofire源码解读系列(七)之网络监控(NetworkReachabilityManager) 本篇主要讲解iOS开发中的网络监控 前言 在开发中,有时候我们需要获取这些信息: 手机是否联网 ...
- Alamofire源码解读系列(八)之安全策略(ServerTrustPolicy)
本篇主要讲解Alamofire中安全验证代码 前言 作为开发人员,理解HTTPS的原理和应用算是一项基本技能.HTTPS目前来说是非常安全的,但仍然有大量的公司还在使用HTTP.其实HTTPS也并不是 ...
- Alamofire源码解读系列(九)之响应封装(Response)
本篇主要带来Alamofire中Response的解读 前言 在每篇文章的前言部分,我都会把我认为的本篇最重要的内容提前讲一下.我更想同大家分享这些顶级框架在设计和编码层次究竟有哪些过人的地方?当然, ...
- Alamofire源码解读系列(十)之序列化(ResponseSerialization)
本篇主要讲解Alamofire中如何把服务器返回的数据序列化 前言 和前边的文章不同, 在这一篇中,我想从程序的设计层次上解读ResponseSerialization这个文件.更直观的去探讨该功能是 ...
随机推荐
- rust入坑指南之ownership
作者:京东零售 王梦津 I. 前言 Rust,不少程序员的白月光,这里我们简单罗列一些大牛的评价. Linus Torvalds:Linux内核的创始人,对Rust的评价是:"Rust的主要 ...
- 浅析大促备战过程中出现的fullGc,我们能做什么?
作者:京东科技 白洋 前言: 背景: 为应对618.双11大促,消费金融侧会根据零售侧大促节奏进行整体系统备战.对核心流量入口承载的系统进行加固优化,排除系统风险,保证大促期间系统稳定. 由于大促期间 ...
- 独立安装VS的C++编译器build tools
Microsoft C++ 生成工具 Microsoft C++ 生成工具 - Visual Studio Microsoft C++ 生成工具通过可编写脚本的独立安装程序提供 MSVC 工具集,无需 ...
- 使用Lua做为MMOARPG游戏逻辑开发脚本的一点体会
项目背景 目前在一个大型MMOARPG游戏中使用Lua做为逻辑开发语言,Lua占整体代码量的80%. 我们这个MMO游戏开发近2年,客户端8人,项目组总体人数在100人(美术占70%),目前代码量很大 ...
- nodejs的npm改为国内源和参数
npm源改为国内 此方法不需要安装cnpm也可以使用淘宝镜像,提高国内访问速度 由于 Node 的官方模块仓库网速太慢,模块仓库需要切换到阿里的源. npm config set registry h ...
- endnote文献使用简明教程+遇到问题
安装下载endnote 1.双击[EndNote X9 v19.0.0.12062 Setup.msi]安装EndNote X9,安装时选择试用,安装完成后不要运行EndNote: 2.如果想使用汉化 ...
- C/C++ 内存转储与获取DLL加载
CREATE_PROCESS_DEBUG_EVENT 创建进程的调试事件.CREATE_PROCESS_DEBUG_INFO结构体描述了该类调试事件的详细信息 OUTPUT_DEBUG_STRING_ ...
- C#9中使用静态匿名函数
匿名函数是很早以前在C#编程语言中引入的.尽管匿名功能有很多好处,但它们并不便宜.避免不必要的分配很重要,这就是为什么在C#9中引入静态匿名函数的原因.在C#9中,lambda或匿名方法可以具有静态修 ...
- Windows安装MySQL8.0.31
环境 Windows 10 mysql 8.0.31 配置 下载mysql 下载地址:https://dev.mysql.com/downloads/mysql/ 点击"Download&q ...
- 性能暴增70%!AMD线程撕裂者RPO 7000将于10月19日发布: 96核心Zen 4史无前例
据wccftech最新报道,AMD的下一代Ryzen Threadripper(线程撕裂者)PRO 7000"Storm Peak"CPU将于10月19日作为终极工作站解决方案亮相 ...