DM数据库 回表优化案例
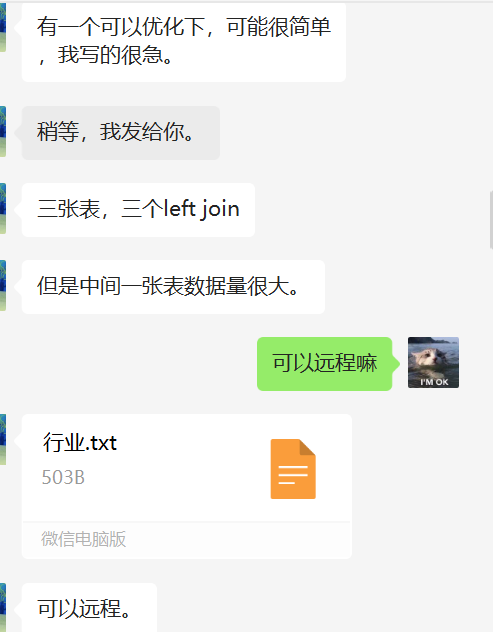
京华开发一哥们找我优化条SQL,反馈在DM数据库执行时间很慢需要 40s 才能出结果,安排。
原SQL:
SELECT A.IND_CODE,
A.IND_NAME AS "specialName",
COUNT(C.ORDER_ID) AS "orderCount",
COUNT(CASE WHEN D.MEDIATE_RESULT IN ('达成调解协议', '双方自行和解') THEN C.ORDER_ID END) AS "successCount"
FROM WCWCWC.AAAAAAAAA A
LEFT JOIN WCWCWC.BBBBBBBBB B
ON A.IND_CODE = B.INDUSTRY_CD
LEFT JOIN
WCWCWC.ccccccccccccccccc C
ON B.UNISCID = C.UNISCID
LEFT JOIN WCWCWC.DDDDDDDDDDDDDD D
ON C.ORDER_ID = D.ORDER_ID
WHERE A.IND_CODE = 'C'
GROUP BY A.IND_CODE,
A.IND_NAME;
执行计划:
1 #NSET2: [491, 1, 96]
2 #PRJT2: [491, 1, 96]; exp_num(4), is_atom(FALSE)
3 #HAGR2: [491, 1, 96]; grp_num(2), sfun_num(2), distinct_flag[0,0]; slave_empty(0) keys(DMTEMPVIEW_889674440.TMPCOL0, DMTEMPVIEW_889674440.TMPCOL1)
4 #PRJT2: [466, 324467, 96]; exp_num(4), is_atom(FALSE)
5 #HASH RIGHT JOIN2: [466, 324467, 96]; key_num(1), ret_null(0), KEY(D.ORDER_ID=C.ORDER_ID)
6 #CSCN2: [1, 15287, 56]; INDEX33557062(DDDDDDDDDDDDDD as D)
7 #HASH RIGHT JOIN2: [437, 324467, 96]; key_num(1), ret_null(0), KEY(C.UNISCID=B.UNISCID)
8 #CSCN2: [11, 97535, 56]; INDEX33557061(ccccccccccccccccc as C)
9 #HASH LEFT JOIN2: [386, 324467, 96]; key_num(1), partition_keys_num(0), ret_null(0), mix(0) KEY(A.IND_CODE=B.INDUSTRY_CD)
10 #INDEX JOIN LEFT JOIN2: [386, 324467, 96] ret_null(0)
11 #ACTRL: [386, 324467, 96];
12 #BLKUP2: [1, 1, 96]; INDEX33557119(A)
13 #SSEK2: [1, 1, 96]; scan_type(ASC), INDEX33557119(AAAAAAAAA as A), scan_range['C','C']
14 #BLKUP2: [351, 324467, 48]; IND_INDUSTRY_CD(B)
15 #SSEK2: [351, 324467, 48]; scan_type(ASC), IND_INDUSTRY_CD(BBBBBBBBB as B), scan_range[A.IND_CODE,A.IND_CODE]
16 #CSCN2: [727, 5840415, 96]; INDEX33558123(BBBBBBBBB as B)
A、B、C、D 表 所有关联列都有索引,整体SQL返回一行数据,但是要 39s 左右,非常不合理。
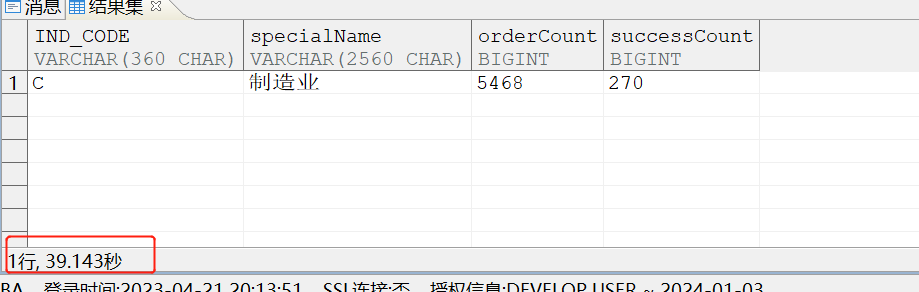
数据量如下:
select count(1) ,'A' from WCWCWC.AAAAAAAAA
union all
select count(1) ,'B' from WCWCWC.BBBBBBBBB
union all
select count(1) ,'C' from WCWCWC.ccccccccccccccccc
union all
select count(1) ,'D' from WCWCWC.DDDDDDDDDDDDDD;
监控下缓慢的节点:
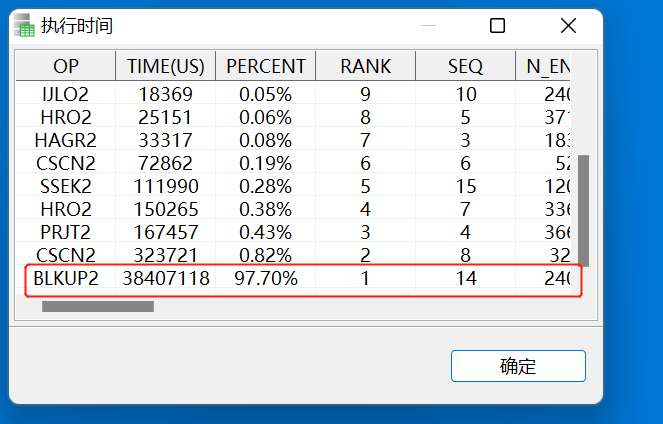
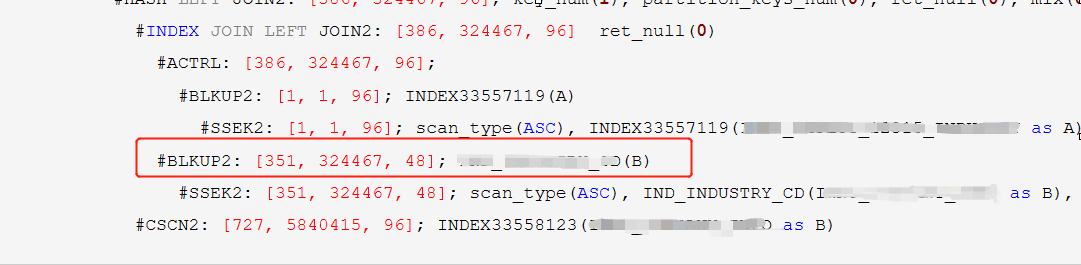
发现慢的节点是 B 表产生BLKUP2,500多W行数据回表 ,IND_INDUSTRY_CD 索引无法找到所有数据。
B表创建联合索引:
create index idx_BBBBBBBBB_1_2 on WCWCWC.BBBBBBBBB(INDUSTRY_CD,UNISCID);
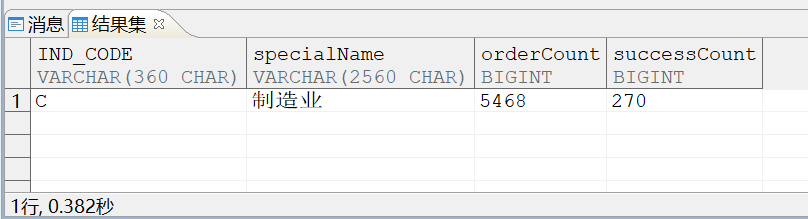
新的执行计划:
1 #NSET2: [158, 1, 96]
2 #PRJT2: [158, 1, 96]; exp_num(4), is_atom(FALSE)
3 #HAGR2: [158, 1, 96]; grp_num(2), sfun_num(2), distinct_flag[0,0]; slave_empty(0) keys(DMTEMPVIEW_889674491.TMPCOL0, DMTEMPVIEW_889674491.TMPCOL1)
4 #PRJT2: [133, 324467, 96]; exp_num(4), is_atom(FALSE)
5 #HASH RIGHT JOIN2: [133, 324467, 96]; key_num(1), ret_null(0), KEY(D.ORDER_ID=C.ORDER_ID)
6 #CSCN2: [1, 15287, 56]; INDEX33557062(DDDDDDDDDDDDDD as D)
7 #HASH RIGHT JOIN2: [104, 324467, 96]; key_num(1), ret_null(0), KEY(C.UNISCID=B.UNISCID)
8 #CSCN2: [11, 97535, 56]; INDEX33557061(ccccccccccccccccc as C)
9 #HASH LEFT JOIN2: [54, 324467, 96]; key_num(1), partition_keys_num(0), ret_null(0), mix(0) KEY(A.IND_CODE=B.INDUSTRY_CD)
10 #INDEX JOIN LEFT JOIN2: [54, 324467, 96] ret_null(0)
11 #ACTRL: [54, 324467, 96];
12 #BLKUP2: [1, 1, 96]; INDEX33557119(A)
13 #SSEK2: [1, 1, 96]; scan_type(ASC), INDEX33557119(AAAAAAAAA as A), scan_range['C','C']
14 #SSEK2: [49, 324467, 96]; scan_type(ASC), IDX_BBBBBBBBB_1_2(BBBBBBBBB as B), scan_range[(A.IND_CODE,min),(A.IND_CODE,max))
15 #SSCN: [727, 5840415, 96]; IDX_BBBBBBBBB_1_2(BBBBBBBBB as B)
可以看到在创建完联合索引后,#BLKUP2: [351, 324467, 48]; 回表计划消失了,SQL也能0.3S跑出结果。
B表UNISCID字段本身就是主键,而INDUSTRY_CD字段本身有索引,开发老哥以为走了两个字段都走索引不会有什么问题,而忽略了回表计划,在大表产生回表计划是非常恐怖的事情!!!
总结:近两年感觉国产数据库市场份额越来越高了,笔者SQL优化的案例更多得也是从ORACLE、MySQL变成了DM、金仓数据库,
建议大家还是要好好深入学习下国产数据库,免得35岁被优化了找不到工作 。 
DM数据库 回表优化案例的更多相关文章
- MySQL的索引单表优化案例分析
建表 建立本次优化案例中所需的数据库及数据表 CREATE DATABASE db0206; USE db0206; CREATE TABLE `db0206`.`article`( `id` INT ...
- MySQL数据库回表与索引
目录 回表的概念 1.stu_info表案例 2.查看刚刚建立的表结构 3.插入测试数据 4.分析过程 5.执行计划 回表的概念 先得出结论,根据下面的实验.如果我要获得['liu','25']这条记 ...
- mysql:如何利用覆盖索引避免回表优化查询
说到覆盖索引之前,先要了解它的数据结构:B+树. 先建个表演示(为了简单,id按顺序建): id name 1 aa 3 kl 5 op 8 aa 10 kk 11 kl 14 jk 16 ml 17 ...
- MySQL索引优化(索引单表优化案例)
1.单表查询优化 建表SQL CREATE TABLE IF NOT EXISTS `article` ( `id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUT ...
- MySQL索引优化(索引两表优化案例)
建表SQL CREATE TABLE IF NOT EXISTS `class` ( `id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, `card` INT ...
- MySQL优化:如何避免回表查询?什么是索引覆盖? (转)
数据库表结构: create table user ( id int primary key, name varchar(20), sex varchar(5), index(name) )engin ...
- MySQL 回表查询 & 索引覆盖优化
回表查询 先通过普通索引的值定位聚簇索引值,再通过聚簇索引的值定位行记录数据 建表示例 mysql> create table user( -> id int(10) auto_incre ...
- 你的 SQL 还在回表查询吗?快给它安排覆盖索引
什么是回表查询 小伙伴们可以先看这篇文章了解下什么是聚集索引和辅助索引:Are You OK?主键.聚集索引.辅助索引,简单回顾下,聚集索引的叶子节点包含完整的行数据,而非聚集索引的叶子节点存储的是每 ...
- (MYSQL)回表查询原理,利用联合索引实现索引覆盖
一.什么是回表查询? 这先要从InnoDB的索引实现说起,InnoDB有两大类索引: 聚集索引(clustered index) 普通索引(secondary index) InnoDB聚集索引和普通 ...
- 再议 MySQL 回表
一:回表概述 关于回表的概念网上已经有很多了,这里不过多赘述.下面我们直接放一张图可能更直观说明什么是回表. 图中 非聚集索引也叫二级索引,二级索引本质上也是 一 个 B+ 树结构,与聚集索引(也叫主 ...
随机推荐
- Git SSH 认证配置
[前言] 我们在开发过程中,经常会和github,gitlab或者gitee打交道,一般临时克隆(clone)其他人的项目学习参考时,我们大多采用 https 的方式进行 clone 但如果在参与多个 ...
- Angular报错:Error: Unknown argument: spec
解决方案 使用--skip-tests代替 效果展示 可以看到spec.ts消失了 参考链接 https://stackoverflow.com/questions/62228834/angular- ...
- ubuntu 安装sublime
Install the GPG key: wget -qO - https://download.sublimetext.com/sublimehq-pub.gpg | sudo apt-key ad ...
- MySQL5.5+配置主从同步并结合ThinkPHP5设置分布式数据库
前言: 本文章是在同处局域网内的两台windows电脑,且MySQL是5.5以上版本下进行的一主多从同步配置,并且使用的是集成环境工具PHPStudy为例.最后就是ThinkPHP5的分布式的连接,读 ...
- [POI2007]GRZ-Ridges and Valleys 题解
(2022-12-28 ) AcWing 1106 洛谷 P3456 题目大意 找出一个图中所有大于(或小于)周围相邻的非连通块点的所有连通块个数. 就是说,对于一个连通块: 如果它周围的点都低于它, ...
- Typescript - 索引签名
1 索引签名概述 在 TypeScript 中,索引签名是一种定义对象类型的方式,它允许我们使用字符串或数字作为索引来访问对象的属性. 1.1 索引签名的定义和作用 索引签名通过以下语法进行定义: { ...
- pycharm+anaconda的关联
Pycharm+anaconda的关联 关联好处:Pycharm和anaconda关联后,pycharm可以直接调用anaconda中已安装好的模块,而anaconda里安装和卸载模块都比较方便. 关 ...
- jQuery下拉框级联实现
参考代码: //企业类别级联 function getCatalog(){ var name=document.getElementById("Lcata").value; var ...
- jQuery默认选中下拉框的某个值
$("#quaterSelect").val("0");//id为quaterSelect的下拉框默认选中value是0的option选项
- 推荐一个react上拉加载更多插件:react-infinite-scroller
在开发网页和移动应用时,经常需要处理大量数据的展示和加载.如果数据量非常大,一次性全部加载可能会导致页面卡顿或崩溃.为了解决这个问题,我们可以使用无限滚动(Infinite Scroll)的技术.Re ...