DM数据库 回表优化案例
京华开发一哥们找我优化条SQL,反馈在DM数据库执行时间很慢需要 40s 才能出结果,安排。
原SQL:
SELECT A.IND_CODE,
A.IND_NAME AS "specialName",
COUNT(C.ORDER_ID) AS "orderCount",
COUNT(CASE WHEN D.MEDIATE_RESULT IN ('达成调解协议', '双方自行和解') THEN C.ORDER_ID END) AS "successCount"
FROM WCWCWC.AAAAAAAAA A
LEFT JOIN WCWCWC.BBBBBBBBB B
ON A.IND_CODE = B.INDUSTRY_CD
LEFT JOIN
WCWCWC.ccccccccccccccccc C
ON B.UNISCID = C.UNISCID
LEFT JOIN WCWCWC.DDDDDDDDDDDDDD D
ON C.ORDER_ID = D.ORDER_ID
WHERE A.IND_CODE = 'C'
GROUP BY A.IND_CODE,
A.IND_NAME;
执行计划:
1 #NSET2: [491, 1, 96]
2 #PRJT2: [491, 1, 96]; exp_num(4), is_atom(FALSE)
3 #HAGR2: [491, 1, 96]; grp_num(2), sfun_num(2), distinct_flag[0,0]; slave_empty(0) keys(DMTEMPVIEW_889674440.TMPCOL0, DMTEMPVIEW_889674440.TMPCOL1)
4 #PRJT2: [466, 324467, 96]; exp_num(4), is_atom(FALSE)
5 #HASH RIGHT JOIN2: [466, 324467, 96]; key_num(1), ret_null(0), KEY(D.ORDER_ID=C.ORDER_ID)
6 #CSCN2: [1, 15287, 56]; INDEX33557062(DDDDDDDDDDDDDD as D)
7 #HASH RIGHT JOIN2: [437, 324467, 96]; key_num(1), ret_null(0), KEY(C.UNISCID=B.UNISCID)
8 #CSCN2: [11, 97535, 56]; INDEX33557061(ccccccccccccccccc as C)
9 #HASH LEFT JOIN2: [386, 324467, 96]; key_num(1), partition_keys_num(0), ret_null(0), mix(0) KEY(A.IND_CODE=B.INDUSTRY_CD)
10 #INDEX JOIN LEFT JOIN2: [386, 324467, 96] ret_null(0)
11 #ACTRL: [386, 324467, 96];
12 #BLKUP2: [1, 1, 96]; INDEX33557119(A)
13 #SSEK2: [1, 1, 96]; scan_type(ASC), INDEX33557119(AAAAAAAAA as A), scan_range['C','C']
14 #BLKUP2: [351, 324467, 48]; IND_INDUSTRY_CD(B)
15 #SSEK2: [351, 324467, 48]; scan_type(ASC), IND_INDUSTRY_CD(BBBBBBBBB as B), scan_range[A.IND_CODE,A.IND_CODE]
16 #CSCN2: [727, 5840415, 96]; INDEX33558123(BBBBBBBBB as B)
A、B、C、D 表 所有关联列都有索引,整体SQL返回一行数据,但是要 39s 左右,非常不合理。
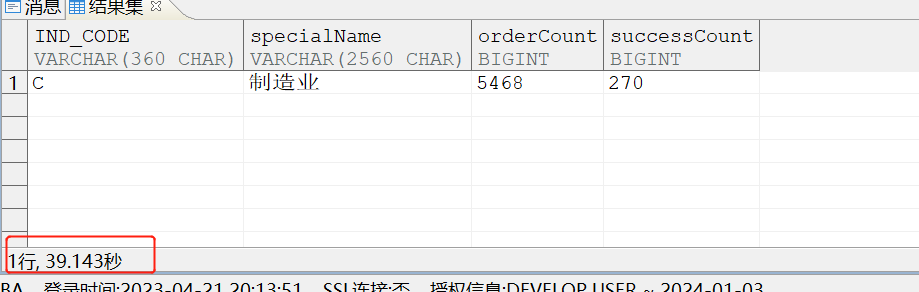
数据量如下:
select count(1) ,'A' from WCWCWC.AAAAAAAAA
union all
select count(1) ,'B' from WCWCWC.BBBBBBBBB
union all
select count(1) ,'C' from WCWCWC.ccccccccccccccccc
union all
select count(1) ,'D' from WCWCWC.DDDDDDDDDDDDDD;
监控下缓慢的节点:
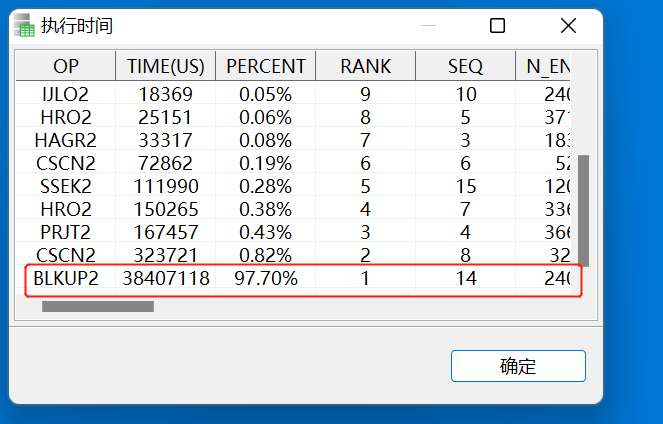
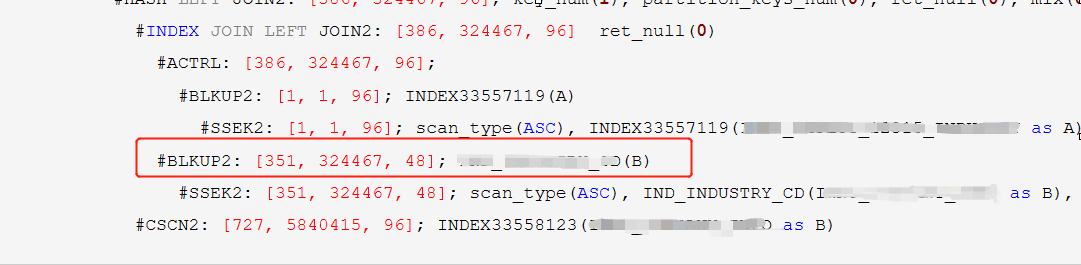
发现慢的节点是 B 表产生BLKUP2,500多W行数据回表 ,IND_INDUSTRY_CD 索引无法找到所有数据。
B表创建联合索引:
create index idx_BBBBBBBBB_1_2 on WCWCWC.BBBBBBBBB(INDUSTRY_CD,UNISCID);
新的执行计划:
1 #NSET2: [158, 1, 96]
2 #PRJT2: [158, 1, 96]; exp_num(4), is_atom(FALSE)
3 #HAGR2: [158, 1, 96]; grp_num(2), sfun_num(2), distinct_flag[0,0]; slave_empty(0) keys(DMTEMPVIEW_889674491.TMPCOL0, DMTEMPVIEW_889674491.TMPCOL1)
4 #PRJT2: [133, 324467, 96]; exp_num(4), is_atom(FALSE)
5 #HASH RIGHT JOIN2: [133, 324467, 96]; key_num(1), ret_null(0), KEY(D.ORDER_ID=C.ORDER_ID)
6 #CSCN2: [1, 15287, 56]; INDEX33557062(DDDDDDDDDDDDDD as D)
7 #HASH RIGHT JOIN2: [104, 324467, 96]; key_num(1), ret_null(0), KEY(C.UNISCID=B.UNISCID)
8 #CSCN2: [11, 97535, 56]; INDEX33557061(ccccccccccccccccc as C)
9 #HASH LEFT JOIN2: [54, 324467, 96]; key_num(1), partition_keys_num(0), ret_null(0), mix(0) KEY(A.IND_CODE=B.INDUSTRY_CD)
10 #INDEX JOIN LEFT JOIN2: [54, 324467, 96] ret_null(0)
11 #ACTRL: [54, 324467, 96];
12 #BLKUP2: [1, 1, 96]; INDEX33557119(A)
13 #SSEK2: [1, 1, 96]; scan_type(ASC), INDEX33557119(AAAAAAAAA as A), scan_range['C','C']
14 #SSEK2: [49, 324467, 96]; scan_type(ASC), IDX_BBBBBBBBB_1_2(BBBBBBBBB as B), scan_range[(A.IND_CODE,min),(A.IND_CODE,max))
15 #SSCN: [727, 5840415, 96]; IDX_BBBBBBBBB_1_2(BBBBBBBBB as B)
可以看到在创建完联合索引后,#BLKUP2: [351, 324467, 48]; 回表计划消失了,SQL也能0.3S跑出结果。
B表UNISCID字段本身就是主键,而INDUSTRY_CD字段本身有索引,开发老哥以为走了两个字段都走索引不会有什么问题,而忽略了回表计划,在大表产生回表计划是非常恐怖的事情!!!
总结:近两年感觉国产数据库市场份额越来越高了,笔者SQL优化的案例更多得也是从ORACLE、MySQL变成了DM、金仓数据库,
建议大家还是要好好深入学习下国产数据库,免得35岁被优化了找不到工作 。 
DM数据库 回表优化案例的更多相关文章
- MySQL的索引单表优化案例分析
建表 建立本次优化案例中所需的数据库及数据表 CREATE DATABASE db0206; USE db0206; CREATE TABLE `db0206`.`article`( `id` INT ...
- MySQL数据库回表与索引
目录 回表的概念 1.stu_info表案例 2.查看刚刚建立的表结构 3.插入测试数据 4.分析过程 5.执行计划 回表的概念 先得出结论,根据下面的实验.如果我要获得['liu','25']这条记 ...
- mysql:如何利用覆盖索引避免回表优化查询
说到覆盖索引之前,先要了解它的数据结构:B+树. 先建个表演示(为了简单,id按顺序建): id name 1 aa 3 kl 5 op 8 aa 10 kk 11 kl 14 jk 16 ml 17 ...
- MySQL索引优化(索引单表优化案例)
1.单表查询优化 建表SQL CREATE TABLE IF NOT EXISTS `article` ( `id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUT ...
- MySQL索引优化(索引两表优化案例)
建表SQL CREATE TABLE IF NOT EXISTS `class` ( `id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, `card` INT ...
- MySQL优化:如何避免回表查询?什么是索引覆盖? (转)
数据库表结构: create table user ( id int primary key, name varchar(20), sex varchar(5), index(name) )engin ...
- MySQL 回表查询 & 索引覆盖优化
回表查询 先通过普通索引的值定位聚簇索引值,再通过聚簇索引的值定位行记录数据 建表示例 mysql> create table user( -> id int(10) auto_incre ...
- 你的 SQL 还在回表查询吗?快给它安排覆盖索引
什么是回表查询 小伙伴们可以先看这篇文章了解下什么是聚集索引和辅助索引:Are You OK?主键.聚集索引.辅助索引,简单回顾下,聚集索引的叶子节点包含完整的行数据,而非聚集索引的叶子节点存储的是每 ...
- (MYSQL)回表查询原理,利用联合索引实现索引覆盖
一.什么是回表查询? 这先要从InnoDB的索引实现说起,InnoDB有两大类索引: 聚集索引(clustered index) 普通索引(secondary index) InnoDB聚集索引和普通 ...
- 再议 MySQL 回表
一:回表概述 关于回表的概念网上已经有很多了,这里不过多赘述.下面我们直接放一张图可能更直观说明什么是回表. 图中 非聚集索引也叫二级索引,二级索引本质上也是 一 个 B+ 树结构,与聚集索引(也叫主 ...
随机推荐
- Java 调用gdal API(二)——栅格裁剪
gdal可以说是GIS数据处理比较好的工具之一,虽然也提供了Java API,但是官方文档确实太过简单,用起来确实太难受,每次都需要去参考对应的C++api,然后在对应使用. 因此小编决定从这篇文章开 ...
- TCP超时分析
参考链接: Linux 建立 TCP 连接的超时时间分析 Linux 建立 TCP 连接的超时时间分析 Linux 系统默认的建立 TCP 连接的超时时间为 127 秒. 2 分 7 秒即 127 秒 ...
- MySQL的索引详解
在MySQL中,常见的索引类型有以下几种: B-Tree索引: B-Tree(Balanced Tree)索引是MySQL中最常见的索引类型.它基于B-Tree数据结构,适用于等值查询.范围查询和排序 ...
- linux文本编辑YCM报错
linux文本编辑YCM报错 刚从github安装了vimplus,可是发现存在不少的问题.索性给直接记录一下. The ycmd server SHUT DOWN (restart with ':Y ...
- Canvas好难,如何让研发低成本实现Web端流程图设计功能
摘要:本文由葡萄城技术团队于博客园原创并首发.转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 前言 相信大家在职场中经常会用到流程图,在互联网行业,绘制流程 ...
- 【go笔记】标准库-strings
标准库-strings 前言 标准库strings用于处理utf-8编码的字符串. 字符串比较-Compare func Compare(a,b string) int 若 a==b ,则返回0:若 ...
- 带你快速上手HetuEngine
本文分享自华为云社区<[手把手带你玩转HetuEngine](一)HetuEngine快速上手>,作者:HetuEngine九级代言. HetuEngine是什么 HetuEngine是华 ...
- #Powerbi 1分钟学会,RANK函数,多字段排名函数.
一:思维导图&数据源示例 1.1思维导图 1.2示例数据源 二:参数构成 三:案例度量值 基础度量值 总销量 = CALCULATE(SUM('数据源'[销量])) 总销售额 = CALCUL ...
- 【page cache】简介
目录 page cache 直接 IO 与 缓存 IO Linux IO 栈 Linux 中的具体实现 相关结构体 超级块 super_block 索引节点 inode 文件 file 目录项 den ...
- Redis的五大数据类型的数据结构
概述 Redis底层有六种数据类型包括:简单动态字符串.双向链表.压缩列表.哈希表.跳表和整数数组.这六种数据结构五大数据类型关系如下: String:简单动态字符串 List:双向链表.压缩列表 ...