MaxCompute(ODPS)和Hive的区别
Hive概述
架构于Hadoop之上,可以将结构化的HDFS文件映射成一张表,并提供了类似于SQL语法的HQL查询功能。
核心本质:将HQL语句转换成MapReduce任务。
Hive的优缺点
优点
避免了开发人员去实现Map和Reduce的接口,大大降低了学习成本。
HQL语法类似于SQL语法,简单、容易上手。
缺点
执行效率比较低 Hive生成的MapReduce任务,不够智能化,容易造成数据倾斜。
Hive架构图
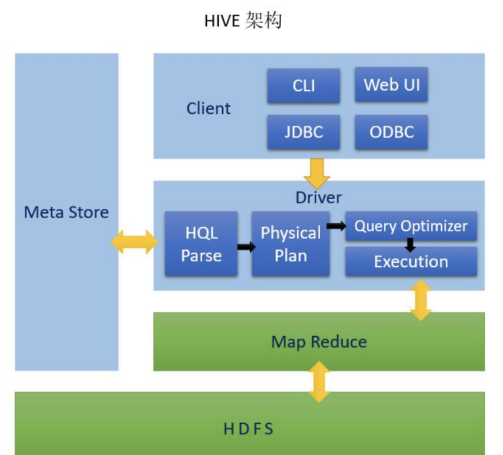
每个模块负责的内容:
Meta Store: 元数据,一般存储在mysql
Client: 客户端
Driver:驱动器
HQL Parse: 解析器,HQL解析和语法分析
Physical Plan: 编译生成逻辑执行计划
Query Optimizer: 对逻辑执行计划进行优化
Execution: 把逻辑执行计划转换成物理执行计划
Hadoop
Map Reduce: 执行计算
HDFS: 文件存储
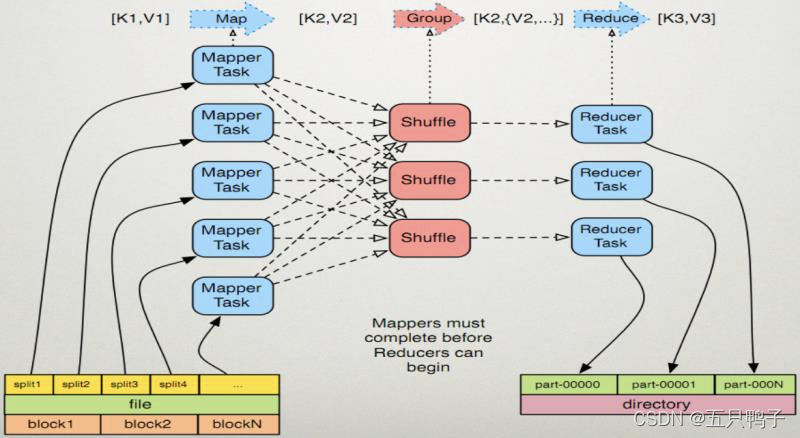
MapReduce 执行原理
MapReduce是一种分布式计算模型,由Map和Reduce组成。 Map()负责把一个大的block块进行切片并计算。 Reduce() 负责把Map()切片的数据进行汇总、计算。
执行的核心思想: 相同key的键值对为一组调用一次Reduce方法,方法内迭代这组数据进行计算。
【Map Reduce 详细步骤图】
ODPS与Hive的关系
ODPS是阿里基于Hive的核心思想构建的,不同的是Hive的文件存储在hdfs上,ODPS则存在阿里的盘古里,而且ODPS针对Hive做了一些优化。
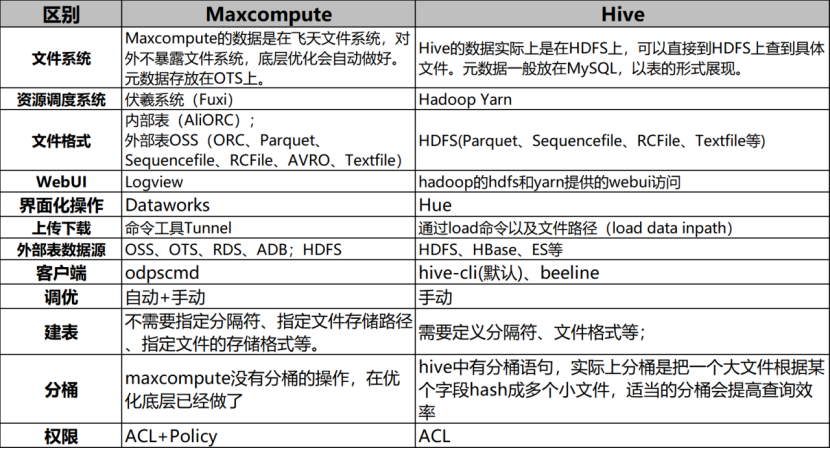
两者的区别
ODPS架构图
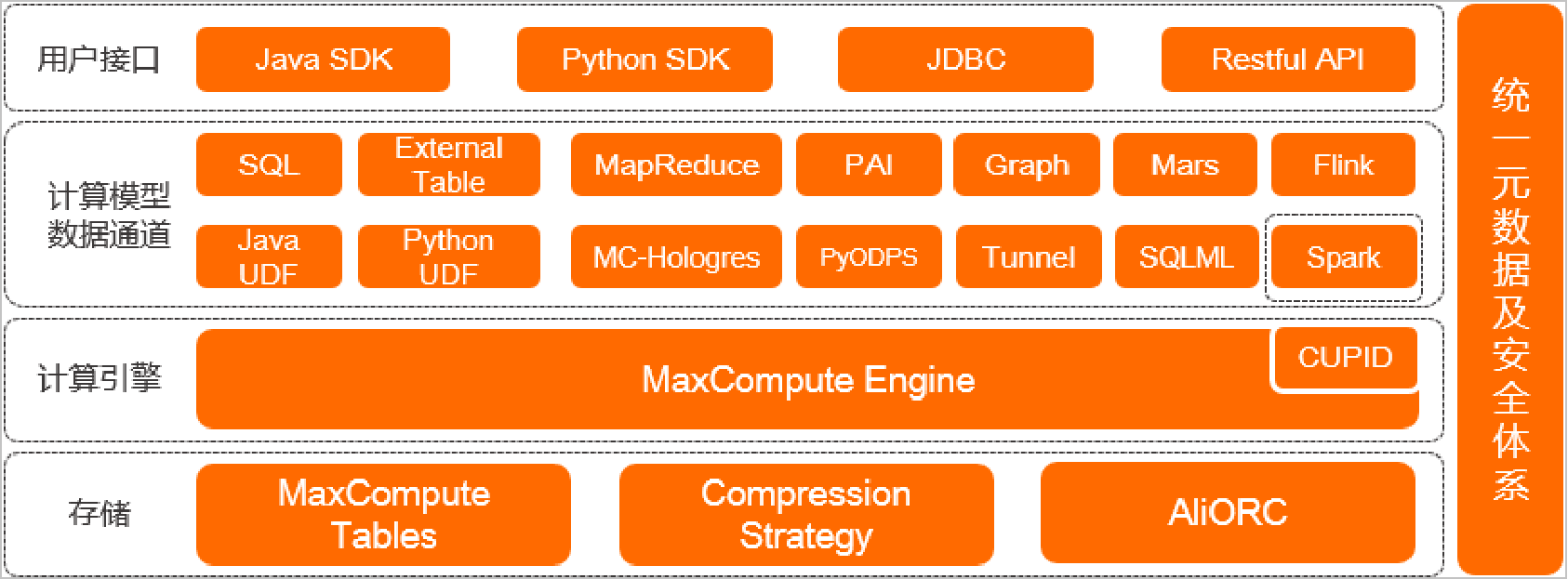
存储
MaxCompute Tables:表是MaxCompute的数据存储单元。不同类型作业的操作对象(输入、输出)都是表。
Compression Strategy:MaxCompute采用列压缩存储格式,通常情况下具备5倍压缩能力。
AliORC:MaxCompute数据存储格式全面升级为AliORC,具备更高存储性能。
计算引擎
MaxCompute本身具备计算引擎能力。在处理Spark作业时,MaxCompute运行在阿里云自研的CUPID平台之上,可以原生支持开源社区Yarn所支持的计算框架。
计算模型数据通道
MaxCompute支持多种数据通道满足多场景需求:SQL、PyODPS、MapReduce、Graph、Mars、PAI、Java/Python UDF等。
用户接口
MaxCompute提供如下用户接口:Java SDK、Python SDK、JDBC、Restful API
统一元数据及安全体系
MaxCompute提供项目元数据及使用历史数据,用户可以对作业的运行情况进行分析,用于优化作业或规划资源容量。
MaxCompute还提供了完善的安全管理体系,例如访问控制、数据加密、动态脱敏等为数据安全性提供保障。
ODPS针对Hive的优化
Query Optimizer 优化器的优化
RBO: 基于规则的优化器 (Oracle 6-9i, Hive)
• 一种过时的优化器框架,它只认规则,对数据不敏感。优化是 局部贪婪,容易陷入局部优但是全局差的场景,容易受应用规 则的顺序而生产迥异的执行计划,往往结果是不是最优的。
CBO:基于代价的优化器 (Oracle 8开始,Oracle 10g完 全取代RBO; MaxCompute)
• Volcano模型,展开各种可能等价的执行计划,然后依赖数据的统计信息,计算这些等价执行计划的“代价”,最后从中选 用cost最低的执行计划。
最典型的优化点:
distinct 的性能优化到和 group by 一致
reduce 分配更加平滑
MaxCompute(ODPS)和Hive的区别的更多相关文章
- Hbase总结(一)-hbase命令,hbase安装,与Hive的区别,与传统数据库的区别,Hbase数据模型
Hbase总结(一)-hbase命令 下面我们看看HBase Shell的一些基本操作命令,我列出了几个常用的HBase Shell命令,如下: 名称 命令表达式 创建表 create '表名称', ...
- hive hbase区别
1.hive是sql语言,通过数据库的方式来操作hdfs文件系统,为了简化编程,底层计算方式为mapreduce. 2.hive是面向行存储的数据库. 3.Hive本身不存储和计算数据,它完全依赖于H ...
- 面试:Hbase和Hive的区别
区别: 1. Hive是一个构建在Hadoop基础设施之上的数据仓库,通过HQL查询存放在HDFS上的数据,不能交互查询.HBase是一种Key/Value系统,它运行在HDFS之上,可以交互查询. ...
- MaxCompute - ODPS重装上阵 第六弹 - User Defined Type
MaxCompute(原ODPS)是阿里云自主研发的具有业界领先水平的分布式大数据处理平台, 尤其在集团内部得到广泛应用,支撑了多个BU的核心业务. MaxCompute除了持续优化性能外,也致力于提 ...
- Pig与Hive的区别
Language 在Hive中可以执行 插入/删除 等操作,但是Pig中我没有发现有可以 插入 数据的方法,请允许我暂且认为这是最大的不同点吧. Schemas Hive中至少还有一个“表”的概念, ...
- Hadoop学习之HBase和Hive的区别
Hive是为简化编写MapReduce程序而生的,使用MapReduce做过数据分析的人都知道,很多分析程序除业务逻辑不同外,程序流程基本一样.在这种情况下,就需要Hive这样的用户编程接口.Hive ...
- [转]Pig与Hive 概念性区别
Pig是一种编程语言,它简化了Hadoop常见的工作任务.Pig可加载数据.表达转换数据以及存储最终结果.Pig内置的操作使得半结构化数据变得有意义(如日志文件).同时Pig可扩展使用Java中添加的 ...
- 【转载】Impala和Hive的区别
Impala和Hive的关系 Impala是基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata,意味着impala元数据都存储在Hive的metastore中.并且im ...
- Hbase的基本原理(与HIVE的区别、数据结构模型、拓扑结构、水平分区原理、场景)
重点:HBase的基本数据模型.拓扑结构.部署配置方法,并介绍通过命令行和编程方式使用HBase的基本方法. HBase:一种列存储模式与键值对相结合的NoSQL软件,但更多的是使用列存储模式,底层的 ...
- maxCompute odps 行转列
select name ,REGEXP_REPLACE(str,"[\\[\"\\]]",'') from ( select trans_array(, ",& ...
随机推荐
- C# 通过ServiceStack 操作Redis——Hash类型的使用及示例
接着上一篇,下面转到hash类型的代码使用 Hash:结构 key-key-value,通过索引快速定位到指定元素的,可直接修改某个字段 /// <summary> /// Hash:类似 ...
- lucene.net全文检索(一)相关概念及示例
相关概念 站内搜索 站内搜索通俗来讲是一个网站或商城的"大门口",一般在形式上包括两个要件:搜索入口和搜索结果页面,但在其后台架构上是比较复杂的,其核心要件包括:中文分词技术.页面 ...
- 百度网盘(百度云)SVIP超级会员共享账号每日更新(2023.11.30)
一.百度网盘SVIP超级会员共享账号 可能很多人不懂这个共享账号是什么意思,小编在这里给大家做一下解答. 我们多知道百度网盘很大的用处就是类似U盘,不同的人把文件上传到百度网盘,别人可以直接下载,避免 ...
- [转帖]nginx 日志打印响应时间 request_time 和 upstream_response_time
https://www.cnblogs.com/chooperman/p/14722450.html 设置log_format,添加request_time,$upstream_response_ti ...
- [转帖]jmeter实现不写代码把测试结果存入execl
这里使用数据库作为中间件来实现不写代码就把测试结果存入execl,下面是步骤 1.新建一个setup线程组用来设置数据库连接信息和新建数据库,如下图所示,我们使用sqlite数据库来存储信息,因为不需 ...
- 【转帖】让互联网更快:新一代QUIC协议在腾讯的技术实践分享
https://www.cnblogs.com/jb2011/p/8458549.html 本文来自腾讯资深研发工程师罗成在InfoQ的技术分享. 1.前言 如果:你的 App,在不需要任何修改的情况 ...
- [转帖]一文解决内核是如何给容器中的进程分配CPU资源的?
https://zhuanlan.zhihu.com/p/615570804 现在很多公司的服务都是跑在容器下,我来问几个容器 CPU 相关的问题,看大家对天天在用的技术是否熟悉. 容器中的核是真 ...
- [转帖]redis操作 + StrictRedis使用
https://www.cnblogs.com/szhangli/p/9979600.html Redis string类型 字符串类型是 Redis 中最为基础的数据存储类型. 它在 Redis 中 ...
- ubuntu18.04 安装wine以及添加mono和gecko打开简单.net应用的方法
1. 今天突然想试试能不能用ubuntu跑一下公司的.net的智能客户端(SmartClient). 想到的办法就是 安装wine 但是过程略坑..这里简单说一下总结之后的过程. 2. 第一步安装wi ...
- Rsync的简单使用
Rsync的简单使用 需求 一个运行很久的系统里面可能包含了非常多的垃圾文件. 但是又不可能随便删除, 很多垃圾可能有某些奇葩的用法. 有时候新建一个应用复制文件的话比较浪费磁盘和带宽. 所以这里简单 ...