MaxCompute(ODPS)和Hive的区别
Hive概述
架构于Hadoop之上,可以将结构化的HDFS文件映射成一张表,并提供了类似于SQL语法的HQL查询功能。
核心本质:将HQL语句转换成MapReduce任务。
Hive的优缺点
优点
避免了开发人员去实现Map和Reduce的接口,大大降低了学习成本。
HQL语法类似于SQL语法,简单、容易上手。
缺点
执行效率比较低 Hive生成的MapReduce任务,不够智能化,容易造成数据倾斜。
Hive架构图
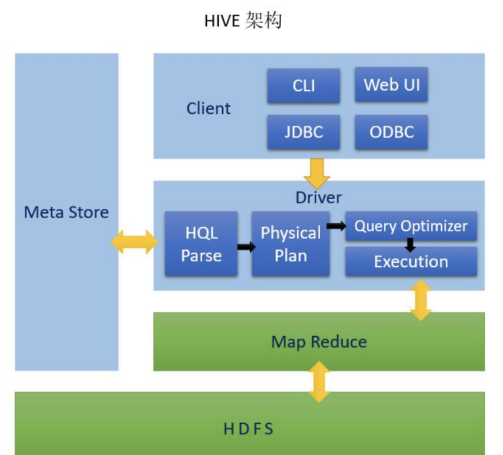
每个模块负责的内容:
Meta Store: 元数据,一般存储在mysql
Client: 客户端
Driver:驱动器
HQL Parse: 解析器,HQL解析和语法分析
Physical Plan: 编译生成逻辑执行计划
Query Optimizer: 对逻辑执行计划进行优化
Execution: 把逻辑执行计划转换成物理执行计划
Hadoop
Map Reduce: 执行计算
HDFS: 文件存储
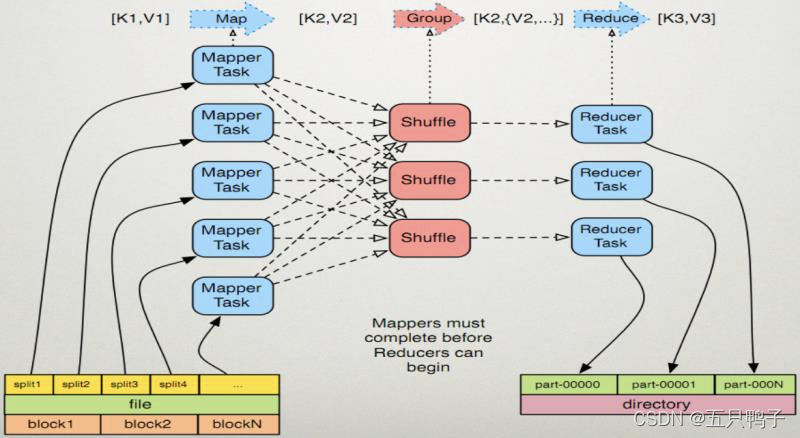
MapReduce 执行原理
MapReduce是一种分布式计算模型,由Map和Reduce组成。 Map()负责把一个大的block块进行切片并计算。 Reduce() 负责把Map()切片的数据进行汇总、计算。
执行的核心思想: 相同key的键值对为一组调用一次Reduce方法,方法内迭代这组数据进行计算。
【Map Reduce 详细步骤图】
ODPS与Hive的关系
ODPS是阿里基于Hive的核心思想构建的,不同的是Hive的文件存储在hdfs上,ODPS则存在阿里的盘古里,而且ODPS针对Hive做了一些优化。
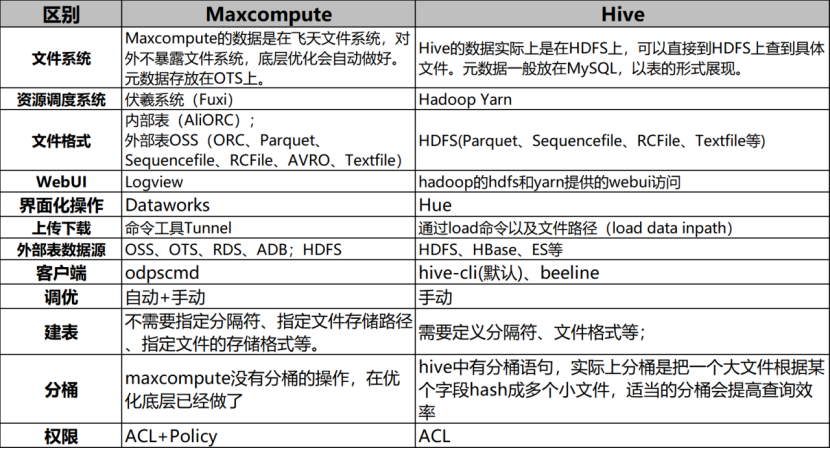
两者的区别
ODPS架构图
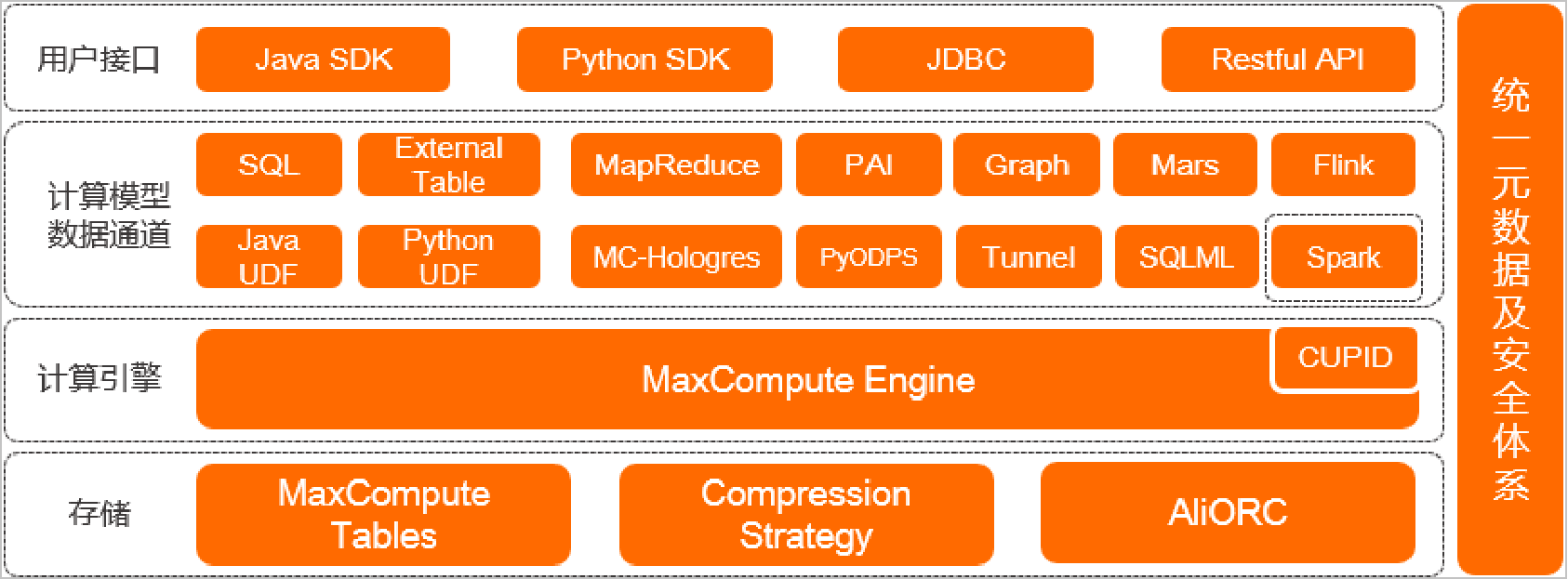
存储
MaxCompute Tables:表是MaxCompute的数据存储单元。不同类型作业的操作对象(输入、输出)都是表。
Compression Strategy:MaxCompute采用列压缩存储格式,通常情况下具备5倍压缩能力。
AliORC:MaxCompute数据存储格式全面升级为AliORC,具备更高存储性能。
计算引擎
MaxCompute本身具备计算引擎能力。在处理Spark作业时,MaxCompute运行在阿里云自研的CUPID平台之上,可以原生支持开源社区Yarn所支持的计算框架。
计算模型数据通道
MaxCompute支持多种数据通道满足多场景需求:SQL、PyODPS、MapReduce、Graph、Mars、PAI、Java/Python UDF等。
用户接口
MaxCompute提供如下用户接口:Java SDK、Python SDK、JDBC、Restful API
统一元数据及安全体系
MaxCompute提供项目元数据及使用历史数据,用户可以对作业的运行情况进行分析,用于优化作业或规划资源容量。
MaxCompute还提供了完善的安全管理体系,例如访问控制、数据加密、动态脱敏等为数据安全性提供保障。
ODPS针对Hive的优化
Query Optimizer 优化器的优化
RBO: 基于规则的优化器 (Oracle 6-9i, Hive)
• 一种过时的优化器框架,它只认规则,对数据不敏感。优化是 局部贪婪,容易陷入局部优但是全局差的场景,容易受应用规 则的顺序而生产迥异的执行计划,往往结果是不是最优的。
CBO:基于代价的优化器 (Oracle 8开始,Oracle 10g完 全取代RBO; MaxCompute)
• Volcano模型,展开各种可能等价的执行计划,然后依赖数据的统计信息,计算这些等价执行计划的“代价”,最后从中选 用cost最低的执行计划。
最典型的优化点:
distinct 的性能优化到和 group by 一致
reduce 分配更加平滑
MaxCompute(ODPS)和Hive的区别的更多相关文章
- Hbase总结(一)-hbase命令,hbase安装,与Hive的区别,与传统数据库的区别,Hbase数据模型
Hbase总结(一)-hbase命令 下面我们看看HBase Shell的一些基本操作命令,我列出了几个常用的HBase Shell命令,如下: 名称 命令表达式 创建表 create '表名称', ...
- hive hbase区别
1.hive是sql语言,通过数据库的方式来操作hdfs文件系统,为了简化编程,底层计算方式为mapreduce. 2.hive是面向行存储的数据库. 3.Hive本身不存储和计算数据,它完全依赖于H ...
- 面试:Hbase和Hive的区别
区别: 1. Hive是一个构建在Hadoop基础设施之上的数据仓库,通过HQL查询存放在HDFS上的数据,不能交互查询.HBase是一种Key/Value系统,它运行在HDFS之上,可以交互查询. ...
- MaxCompute - ODPS重装上阵 第六弹 - User Defined Type
MaxCompute(原ODPS)是阿里云自主研发的具有业界领先水平的分布式大数据处理平台, 尤其在集团内部得到广泛应用,支撑了多个BU的核心业务. MaxCompute除了持续优化性能外,也致力于提 ...
- Pig与Hive的区别
Language 在Hive中可以执行 插入/删除 等操作,但是Pig中我没有发现有可以 插入 数据的方法,请允许我暂且认为这是最大的不同点吧. Schemas Hive中至少还有一个“表”的概念, ...
- Hadoop学习之HBase和Hive的区别
Hive是为简化编写MapReduce程序而生的,使用MapReduce做过数据分析的人都知道,很多分析程序除业务逻辑不同外,程序流程基本一样.在这种情况下,就需要Hive这样的用户编程接口.Hive ...
- [转]Pig与Hive 概念性区别
Pig是一种编程语言,它简化了Hadoop常见的工作任务.Pig可加载数据.表达转换数据以及存储最终结果.Pig内置的操作使得半结构化数据变得有意义(如日志文件).同时Pig可扩展使用Java中添加的 ...
- 【转载】Impala和Hive的区别
Impala和Hive的关系 Impala是基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata,意味着impala元数据都存储在Hive的metastore中.并且im ...
- Hbase的基本原理(与HIVE的区别、数据结构模型、拓扑结构、水平分区原理、场景)
重点:HBase的基本数据模型.拓扑结构.部署配置方法,并介绍通过命令行和编程方式使用HBase的基本方法. HBase:一种列存储模式与键值对相结合的NoSQL软件,但更多的是使用列存储模式,底层的 ...
- maxCompute odps 行转列
select name ,REGEXP_REPLACE(str,"[\\[\"\\]]",'') from ( select trans_array(, ",& ...
随机推荐
- vue-draggable 学习和使用
vue-draggable 学习和使用 https://www.jianshu.com/p/e8ff1e1cafb1
- Kubernetes APIServer 最佳实践
1. kubernetes 整体架构 kubernetes 由 master 节点和工作节点组成.其中,master 节点的组件有 APIServer,scheduler 和 controller-m ...
- 概率图模型 · 蒙特卡洛采样 · MCMC | 非常好的教学视频
https://www.bilibili.com/video/BV17D4y1o7J2?p=1 非常感谢!感觉学会一点了,应该能写作业了
- git仓库之gogs安装(docker版/二进制版)
二进制安装gogs tar zxf gogs_0.11.91_linux_amd64.tar.gz -C /data/gogs chown -R www.www /data/gogs su - www ...
- 43 干货系列从零用Rust编写负载均衡及代理,内网穿透方案完整部署
wmproxy wmproxy已用Rust实现http/https代理, socks5代理, 反向代理, 静态文件服务器,四层TCP/UDP转发,七层负载均衡,内网穿透,后续将实现websocket代 ...
- UPF - Power Intent Basic
Mainstream Low Power techniques Low Vth - 阈值电压比较低,翻转时间小,漏电流比较大,功耗大,速度快 High Vth - 阈值电压比较高,翻转时间长,漏电流比 ...
- Spring Boot+Vue实现汽车租赁系统(毕设)
一.前言 汽车租赁系统,很常见的一个系统,但是网上还是以前的老框架实现的,于是我打算从设计到开发都用现在比较流行的新框架.想学习或者做毕设的可以私信联系哦!! 二.技术栈 - 后端技术 Spring ...
- ECharts——快速入门
ECharts快速入门 引入 ECharts <!DOCTYPE html> <html> <head> <meta charset="utf-8& ...
- C#调用C++——CLR方式
一直是在写C#,最近接触到的项目中有C#调用C++接口的逻辑,自己学习了下,写个步骤日志,C#掉用C++的托管代码 项目分三个项目:1.底层C++动态库项目,2.中间层的CLR项目,3.上层的C#项目 ...
- [转帖]jmeter命令大全(命令行模式)
jmeter命令 --? 打印命令行选项并退出 -h. --帮助 打印使用信息和退出 -v. --版本 打印版本信息并退出 -p. --propfile<argument> 要使用的jme ...