[转帖]3.3.7. 自动诊断和建议报告SYS_KDDM
https://help.kingbase.com.cn/v8/perfor/performance-optimization/performance-optimization-6.html#sys-ksh
KDDM 是 KingbaseES 性能自动诊断和建议的报告。它基于 KWR 快照采集的性能指标和数据库时间模型(DB Time),自动分析等待事件、IO、网络、内存和 SQL 执行时间等,给出一系列性能优化建议。通过 KDDM 报告,能够实现数据库性能的快速调优。
KDDM 存在于 KWR 插件里,和 KWR 一起对外提供服务。
目前 KDDM 报告仅支持 TEXT 格式,不支持 HTML 格式输出。
3.3.7.1. 快速生成 KDDM 报告 ¶
通过 KWR 自动快照或者手动快照创建一系列 KWR 快照,然后就可以通过 perf.kddm_report({snap_1}, {snap_2}) 来创建 KDDM 报告:
CREATE EXTENSION sys_kwr;
SELECT * FROM perf.create_snapshot();
INSERT INTO t1 SELECT generate_series(1, 1000000);
SELECT * FROM perf.create_snapshot();
SELECT * FROM perf.kddm_report(1,2);
生成的报告如下:
SELECT * FROM perf.kddm_report(1,2);

3.3.7.2. 使用 KDDM ¶
3.3.7.2.1. 配置 GUC 参数 ¶
sys_kwr.language:指定 KDDM 报告输出的语言,TEXT类型,有效的值:'english'/'eng'/'chinese'/'chn',默认 'chinese',即按中文显示报告。
说明:KDDM 报告依赖 KWR 快照,关于KWR快照部分 GUC 参数,请参考 KWR 相关章节。
3.3.7.2.2. 生成KDDM报告 ¶
生成 kddm 报告
SELECT * FROM perf.kddm_report(1, 2);
说明:KDDM 报告也会自动在数据库服务器 DATA 目录的 sys_log 下保存一份。
生成 kddm 报告并保存到指定文件
SELECT * FROM perf.kddm_report_to_file(1, 2, '/home/test/kddm_1_2.txt');
为指定 query id 的 SQL 语句生成 SQL 报告
SELECT * FROM perf.kddm_sql_report(1, 2, 5473583404117387630);
根据快照范围和具体的 SQL ID,给出 SQL 详细报告,主要用于分析耗时较多的 SQL 语句占用的 CPU,IO 资源的使用情况。
3.3.7.3. KDDM 报告 ¶
kddm 报告根据 KWR 快照内容,给出以下的建议和报告:
数据库时间分解报告
CPU 相关建议
TOP SQL 建议
使用扩展 SQL 协议建议
CPU 负载高建议
优化回滚事务建议
优化堆页面裁剪建议
使用索引建议
等待事件相关建议
TOP 等待事件建议
LWLock 类等待事件建议
IO 类等待事件建议
Client 类等待建议
完整 SQL 列表
每条具体建议包含三项内容:
建议依据:描述了数据库当前存在的性能问题。
建议动作:按优先级给出性能优化的建议操作,通过指定的操作选项能够改善当前存在的性能问题。
参考信息:描述了当前性能问题的具体指标。
示例报告:TOP SQL 建议
该报告展示可以通过 TOP SQL 找到消耗资源最多的SQL语句,当设置成如下配置参数时,对外提供树状结构显示 TOP SQL 的报告。
sys_stat_statements.track = 'all'

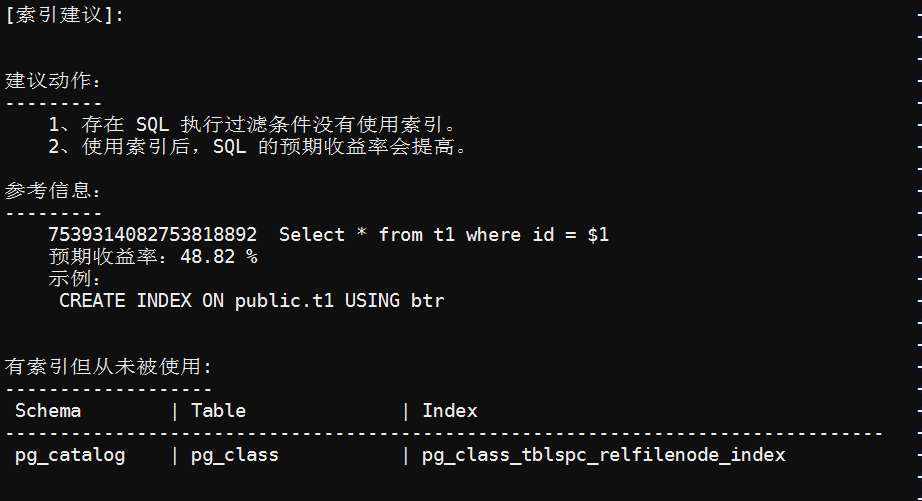
示例报告:使用索引建议
该报告展示可以通过使用索引来提高 SQL 性能的建议,不仅给出了具体的 SQL 语句,还会给出创建索引的 DDL 语句,以及预期收益率。
该报告也给出了存在但未被使用的索引,DBA 可以根据实际情况进一步操作。
合理的索引使用可以加速检索过程。
3.3.7.4. GUC 参数建议 ¶
KDDM 提供 GUC 参数建议功能,根据数据库服务器的硬件情况和用户指定的业务类型,显示建议结果:
SELECT * FROM perf.kddm_guc_advisor(); --最大连接数:300,使用默认值
--CPU核心数:96,自动获取
--总物理内存:256 GB,自动获取
--应用类型:OLTP,使用默认值
--建议参数列表:
max_connections = 300
shared_buffers = 64GB
effective_cache_size = 192GB
maintenance_work_mem = 2GB
work_mem = 55MB
wal_buffers = 16MB
min_wal_size = 1GB
max_wal_size = 4GB
max_worker_processes = 24
max_parallel_workers_per_gather = 4
max_parallel_workers = 24
max_parallel_maintenance_workers = 4
可以通过制定最大连接数、CPU 核心数、内存大小、业务类型等参数来定制化 GUC 参数建议列表,函数的声明如下:
TEXT perf.kddm_guc_advisor(
IN conn bigint = 0,
IN service_type TEXT = 'oltp',
IN cpu bigint = 0,
IN memory bigint = 0);
参数说明:
conn:最大连接数,默认300,范围:1-1000
cpu:CPU 核心数,默认自动获取,范围:1-1000
memory:内存大小,单位为 MB,默认自动获取,范围:128MB - 1T
service_type:业务类型,默认为 ’oltp’,可选范围:
oltp:事务型数据库服务器
olap:分析性数据库服务器
web:Web服务器
desktop:桌面应用
mixed:混合应用
[转帖]3.3.7. 自动诊断和建议报告SYS_KDDM的更多相关文章
- [转]Oracle10g数据库自动诊断监视工具(ADDM)使用指南
第一章 ADDM简介 在Oracle9i及之前,DBA们已经拥有了很多很好用的性能分析工具,比如,tkprof.sql_trace.statspack.set even ...
- 自动诊断档案库(ADR)学习
(1)ADR概述 Oracle 11g的FDI(Fault Diagnosability Infrastructure)是自动化诊断方面的一个增强,其核心组件为自动诊断库(Automatic Diag ...
- Oracle ADDM性能诊断利器及报告解读
性能优化是一个永恒的话题,性能优化也是最具有价值,最值得花费精力深入研究的一个课题,因为资源是有限的,时间是有限的.在Oracle数据库中,随着Oracle功能的不断强大和完善,Oralce数据库在性 ...
- python--selenium实用的自动生成测试HTML报告方法--HTMLTestRunner
python--selenium实用的自动生成测试HTML报告方法--HTMLTestRunner 下面给大家介绍下用HTMLTestRunner模块自动生成测试报告的方法. 一.首先我们导入unit ...
- 141_Power Query之获取钉钉审批流自动刷新Power BI报告
博客:www.jiaopengzi.com 焦棚子的文章目录 请点击下载附件 一.背景 钉钉办公给很多企业带来了很多方便,比如审批流线上化,通用化.线上化填写后,数据自动获取又是一个硬伤了,虽然数据可 ...
- [转帖]在 k8s 中自动为域名配置 https
在 k8s 中自动为域名配置 https https://juejin.im/post/5db8d94be51d4529f73e2833 随着 web 的发展,https 对于现代网站来说是必不可少的 ...
- 131_Power Query之获取钉钉日志自动刷新Power BI报告
博客:www.jiaopengzi.com 焦棚子的文章目录 请点击下载附件 一.背景 最近在玩钉钉日志,企业填写简单数据后方便汇总到一起比较实用的工具,但数据填写以后还是需要下载日志报表,比较麻烦. ...
- OCP读书笔记(9) - 诊断数据库
数据库恢复顾问 Data Recovery Advisor的命令行选项 1. 启动 RMAN 进程并连接到目标$ rman target=/ 2. 假设发生了某个错误,希望找出原因,使用 list f ...
- IntelliJ IDEA 的 20 个代码自动完成的特性
http://www.oschina.net/question/12_70799 在这篇文章中,我想向您展示 IntelliJ IDEA 中最棒的 20 个代码自动完成的特性,可让 Java 编码变得 ...
- SQL Server 2008创建定期自动备份任务
首先需要启动SQL Server Agent服务,这个服务如果不启动是无法运行新建作业的,点击“开始”–“所有程序”–“Microsoft SQL Server 2008”–“启动SQL Server ...
随机推荐
- Windows环境下为Android编译OpenCV4.3
Windows环境下为Android编译OpenCV4.3 踩了三四天的坑,今天终于顺利跑通了,原来是toolchain的问题,外网的教程大多都是用opencv source里的toolchain,会 ...
- Provider的八种提供者
代码 class Example extends StatelessWidget { @override Widget build(BuildContext context) { return Sca ...
- Java 打印Excel工作表
示例要点 本文介绍如何通过Java程序打印Excel工作表.可通过以下方法打印: 默认打印机打印 指定打印机打印 程序环境 spire.xls.jar JDK版本要求1.6.0及以上的高版本 IDEA ...
- MySQL 数据库救火:磁盘爆满了,怎么办?
摘要:当磁盘空间爆满后,MySQL会发生什么事呢?又应该怎么应对? 本文分享自华为云社区<[MySQL 数据库救火]- 磁盘突然爆满的处理方式>,原文作者:技术火炬手 . 大多数用户在对于 ...
- CWE4.6标准中加入 OWASP 2021 TOP10
摘要: 新发布的CWE4.6标准,加入了OWASP 2021 TOP10的视图. 本文分享自华为云社区<CWE 4.6 和 OWAPS TOP10(2021)>,作者: Uncle_Tom ...
- Java 匿名函数的概念和写法
匿名函数的实现 1.定义一个函数式接口.只有一个抽象方法的接口就是函数式接口 //1.定义一个函数式接口.只有一个抽象方法的接口就是函数式接口 interface ILike { void hit(l ...
- WebApi 接口请求耗时记录
.Net Core NLog 配置 通过日志,记录每个接口请求的耗时情况 结合 <logger name="*" level="Trace" write ...
- Hugging News #0918: Hub 加入分类整理功能、科普文本生成中的流式传输
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- CO02生产订单新增组件
"-----------------------------------------@斌将军-------------------------------------------- LOOP ...
- Codeforces Round #723 (Div. 2) (A~C题题解)
补题链接:Here 1526A. Mean Inequality 给定 \(2 * n\) 个整数序列 \(a\),请按下列两个条件输出序列 \(b\) 序列是 \(a\) 序列的重排序 \(b_i ...