使用 Hugging Face 微调 Gemma 模型
我们最近宣布了,来自 Google Deepmind 开放权重的语言模型 Gemma现已通过 Hugging Face 面向更广泛的开源社区开放。该模型提供了两个规模的版本:20 亿和 70 亿参数,包括预训练版本和经过指令调优的版本。它在 Hugging Face 平台上提供支持,可在 Vertex Model Garden 和 Google Kubernetes Engine 中轻松部署和微调。
Gemma 模型系列同样非常适合利用 Colab 提供的免费 GPU 资源进行原型设计和实验。在这篇文章中,我们将简要介绍如何在 GPU 和 Cloud TPU 上,使用 Hugging Face Transformers 和 PEFT 库对 Gemma 模型进行参数高效微调(PEFT),这对想要在自己的数据集上微调 Gemma 模型的用户尤其有用。
为什么选择 PEFT?

即使对于中等大小的语言模型,常规的全参数训练也会非常占用内存和计算资源。对于依赖公共计算平台进行学习和实验的用户来说,如 Colab 或 Kaggle,成本可能过高。另一方面,对于企业用户来说,调整这些模型以适应不同领域的成本也是一个需要优化的重要指标。参数高效微调(PEFT)是一种以低成本实现这一目标的流行方法。
了解更多 PEFT 请参考文章:PEFT: 在低资源硬件上对十亿规模模型进行参数高效微调
在 GPU 和 TPU 上使用 PyTorch 进行 Gemma 模型的高效微调
在 Hugging Face 的 transformers 中,Gemma 模型已针对 PyTorch 和 PyTorch/XLA 进行了优化,使得无论是 TPU 还是 GPU 用户都可以根据需要轻松地访问和试验 Gemma 模型。随着 Gemma 的发布,我们还改善了 PyTorch/XLA 在 Hugging Face 上的 FSDP 使用体验。这种 FSDP 通过 SPMD 的集成还让其他 Hugging Face 模型能够通过 PyTorch/XLA 利用 TPU 加速。本文将重点介绍 Gemma 模型的 PEFT 微调,特别是低秩适应(LoRA)。
想要深入了解 LoRA 技术,我们推荐阅读 Lialin 等人的 "Scaling Down to Scale Up" 以及 Belkada 等人的 精彩文章。
使用低秩适应技术 (LoRA) 对大语言模型进行微调
低秩适应(LoRA)是一种用于大语言模型(LLM)的参数高效微调技术。它只针对模型参数的一小部分进行微调,通过冻结原始模型并只训练被分解为低秩矩阵的适配器层。PEFT 库 提供了一个简易的抽象,允许用户选择应用适配器权重的模型层。
from peft import LoraConfig
lora_config = LoraConfig(
r=8,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
task_type="CAUSAL_LM",
)
在这个代码片段中,我们将所有的 nn.Linear 层视为要适应的目标层。
在以下示例中,我们将利用 QLoRA,出自 Dettmers 等人,通过 4 位精度量化基础模型,以实现更高的内存效率微调协议。通过首先在您的环境中安装 bitsandbytes 库,然后在加载模型时传递 BitsAndBytesConfig 对象,即可加载具有 QLoRA 的模型。
开始之前
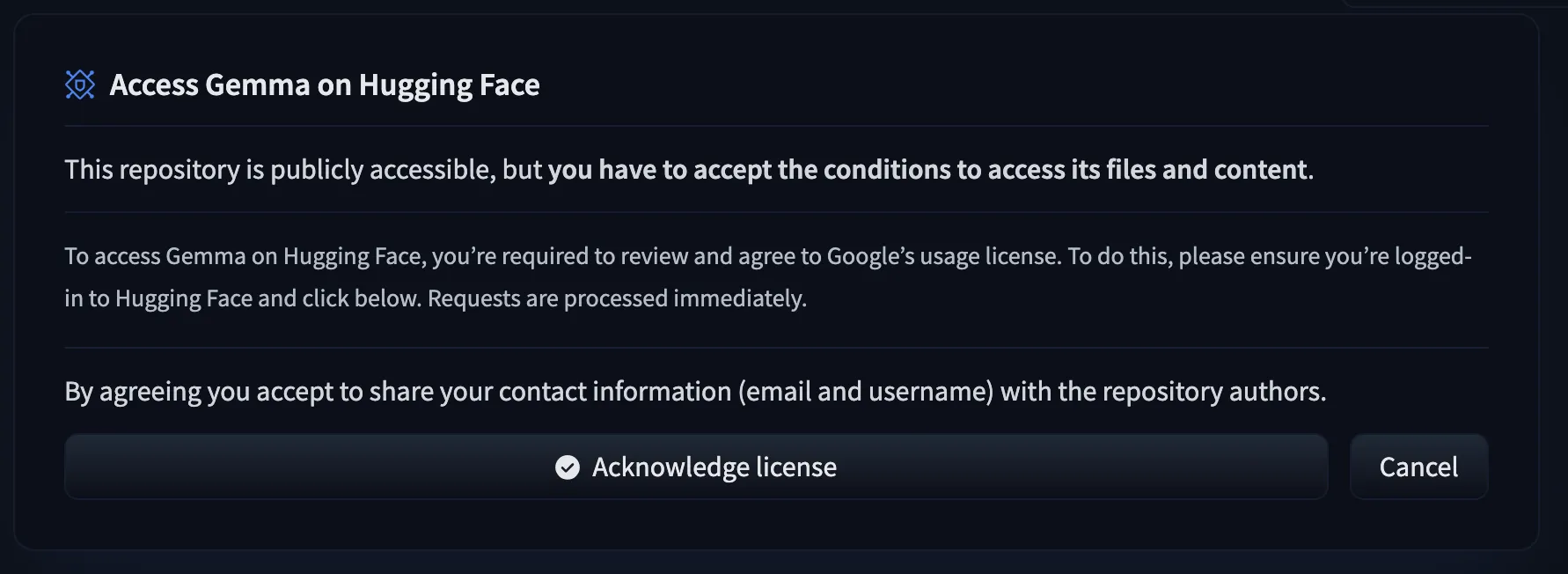
要访问 Gemma 模型文件,用户需先填写 同意表格。
我们继续。
微调 Gemma,让它学会并生成一些“名言金句”
假设您已提交同意表格,您可以从 Hugging Face Hub 获取模型文件。
我们首先下载模型和分词器 (tokenizer),其中包含了一个 BitsAndBytesConfig 用于仅限权重的量化。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "google/gemma-2b"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_id, token=os.environ['HF_TOKEN'])
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0}, token=os.environ['HF_TOKEN'])
在开始微调前,我们先使用一个相当熟知的名言来测试一下 Gemma 模型:
text = "Quote: Imagination is more"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
模型完成了一个合理的补全,尽管有一些额外的 token:
Quote: Imagination is more important than knowledge. Knowledge is limited. Imagination encircles the world.
-Albert Einstein
I
但这并不完全是我们希望看到的答案格式。我们将尝试通过微调让模型学会以我们期望的格式来产生答案:
Quote: Imagination is more important than knowledge. Knowledge is limited. Imagination encircles the world.
Author: Albert Einstein
首先,我们选择一个英文“名人名言”数据集:
from datasets import load_dataset
data = load_dataset("Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
接下来,我们使用上述 LoRA 配置对模型进行微调:
import transformers
from trl import SFTTrainer
def formatting_func(example):
text = f"Quote: {example['quote'][0]}\nAuthor: {example['author'][0]}"
return [text]
trainer = SFTTrainer(
model=model,
train_dataset=data["train"],
args=transformers.TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
warmup_steps=2,
max_steps=10,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir="outputs",
optim="paged_adamw_8bit"
),
peft_config=lora_config,
formatting_func=formatting_func,
)
trainer.train()
最终,我们再次使用先前的提示词,来测试模型:
text = "Quote: Imagination is"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
这次,我们得到了我们期待的答案格式:
Quote: Imagination is more important than knowledge. Knowledge is limited. Imagination encircles the world.
Author: Albert Einstein
名言:想象力比知识更重要,因为知识是有限的,而想象力概括着世界的一切.
作者:阿尔伯特·爱因斯坦
在 TPU 环境下微调,可通过 SPMD 上的 FSDP 加速
如前所述,Hugging Face transformers 现支持 PyTorch/XLA 的最新 FSDP 实现,这可以显著加快微调速度。
只需在 transformers.Trainer 中添加 FSDP 配置即可启用此功能:
from transformers import DataCollatorForLanguageModeling, Trainer, TrainingArguments
# Set up the FSDP config. To enable FSDP via SPMD, set xla_fsdp_v2 to True.
fsdp_config = {
"fsdp_transformer_layer_cls_to_wrap": ["GemmaDecoderLayer"],
"xla": True,
"xla_fsdp_v2": True,
"xla_fsdp_grad_ckpt": True
}
# Finally, set up the trainer and train the model.
trainer = Trainer(
model=model,
train_dataset=data,
args=TrainingArguments(
per_device_train_batch_size=64, # This is actually the global batch size for SPMD.
num_train_epochs=100,
max_steps=-1,
output_dir="./output",
optim="adafactor",
logging_steps=1,
dataloader_drop_last = True, # Required for SPMD.
fsdp="full_shard",
fsdp_config=fsdp_config,
),
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
trainer.train()
下一步
通过这个从源笔记本改编的简单示例,我们展示了应用于 Gemma 模型的 LoRA 微调方法。完整的 GPU colab 在 这里 可以找到,完整的 TPU 脚本在 这里可以找到。我们对于这一最新加入我们开源生态系统的成员所带来的无限研究和学习机会感到兴奋。我们鼓励用户也浏览 Gemma 文档 和我们的 发布博客,以获取更多关于训练、微调和部署 Gemma 模型的示例。
使用 Hugging Face 微调 Gemma 模型的更多相关文章
- Hugging Face发布diffuser模型AI绘画库初尝鲜!
作者:韩信子@ShowMeAI 深度学习实战系列:https://www.showmeai.tech/tutorials/42 TensorFlow 实战系列:https://www.showmeai ...
- 利用Hugging Face中的模型进行句子相似性实践
Hugging Face是什么?它作为一个GitHub史上增长最快的AI项目,创始人将它的成功归功于弥补了科学与生产之间的鸿沟.什么意思呢?因为现在很多AI研究者写了大量的论文和开源了大量的代码, ...
- Optimum + ONNX Runtime: 更容易、更快地训练你的 Hugging Face 模型
介绍 基于语言.视觉和语音的 Transformer 模型越来越大,以支持终端用户复杂的多模态用例.增加模型大小直接影响训练这些模型所需的资源,并随着模型大小的增加而扩展它们.Hugging Face ...
- 使用 DeepSpeed 和 Hugging Face 🤗 Transformer 微调 FLAN-T5 XL/XXL
Scaling Instruction-Finetuned Language Models 论文发布了 FLAN-T5 模型,它是 T5 模型的增强版.FLAN-T5 由很多各种各样的任务微调而得,因 ...
- PyTorch专栏(八):微调基于torchvision 0.3的目标检测模型
专栏目录: 第一章:PyTorch之简介与下载 PyTorch简介 PyTorch环境搭建 第二章:PyTorch之60分钟入门 PyTorch入门 PyTorch自动微分 PyTorch神经网络 P ...
- Torchvision模型微调
Torchvision模型微调 本文将深入探讨如何对 torchvision 模型进行微调和特征提取,所有这些模型都已经预先在1000类的magenet数据集上训练完成.将深入介绍如何使用几个现代的C ...
- ILLA Cloud: 调用 Hugging Face Inference Endpoints,开启大模型世界之门
一个月前,我们 宣布了与 ILLA Cloud 与达成的合作,ILLA Cloud 正式支持集成 Hugging Face Hub 上的 AI 模型库和其他相关功能. 今天,我们为大家带来 ILLA ...
- 官宣 | Hugging Face 中文博客正式发布!
作者:Tiezhen.Adina.Luke Hugging Face 的中国社区成立已经有五个月之久,我们也非常高兴的看到 Hugging Face 相关的中文内容在各个平台广受好评,我们也注意到,H ...
- lecture14-RBM的堆叠、修改以及DBN的决策学习和微调
这是Hinton的第14课,主要介绍了RBM和DBN的东西,这一课的课外读物有三篇论文<Self-taught learning- transfer learning from unlabele ...
- pycaffe︱caffe中fine-tuning模型三重天(函数详解、框架简述)
本文主要参考caffe官方文档[<Fine-tuning a Pretrained Network for Style Recognition>](http://nbviewer.jupy ...
随机推荐
- [转帖]Windows自带MD5 SHA1 SHA256命令行工具
https://www.cnblogs.com/huangrt/p/13961399.html 检验工具http://www.zdfans.com/html/4346.html HashMyFiles ...
- [转帖]jmeter正则表达式提取器获取数组数据-02篇
接上篇,当我们正则表达式匹配到多个值以后,入下图所示,匹配到21个结果,如果我们想一次拿到这一组数据怎么办呢 打开正则表达式提取器页面,匹配数字填入-1即可 通过调试取样器就可以看到匹配到已经匹配到多 ...
- Semantic Kernel 通过 LocalAI 集成本地模型
本文是基于 LLama 2是由Meta 开源的大语言模型,通过LocalAI 来集成LLama2 来演示Semantic kernel(简称SK) 和 本地大模型的集成示例. SK 可以支持各种大模型 ...
- 热更新适配ibatis原理浅析
一.热更新解决了什么问题? 在研发过程中,每个研发同学在联调.自测阶段中总会频繁的去执行编译.构建.打包的动作,遇到比较大的项目,执行一套流程下来,往往需要3-10分钟左右,极大的降低了研发的速度,基 ...
- vue3动态路由的addRoute和removeRoute使用
为什么需要有动态路由 有些时候,我们不同的身份角色,我们希望可以展示不同的菜单. 比如说:普通用户只有展示A菜单,管理员有A,B,C菜单 这个时候,我们就需要动态路由了! Vue2和vue3的区别 V ...
- TienChin-课程管理-课程更新接口
更改包名 将之前的 entity 更改为 domain: 将之前的 validator 包当中的校验分组接口移动到 common 模块当中,因为其它模块也需要使用就放到公共当中进行存储. 更改完毕之后 ...
- 微信小程序-页面跳转wxAPI
官方文档地址:https://developers.weixin.qq.com/miniprogram/dev/api/route/wx.navigateTo.html wx.navigateTo(O ...
- Prompt-“设计提示模板:用更少数据实现预训练模型的卓越表现,助力Few-Shot和Zero-Shot任务”
Prompt-"设计提示模板:用更少数据实现预训练模型的卓越表现,助力Few-Shot和Zero-Shot任务" 通过设计提示(prompt)模板,实现使用更少量的数据在预训练模型 ...
- 13.4 DirectX内部劫持绘制
相对于外部绘图技术的不稳定性,内部绘制则显得更加流程与稳定,在Dx9环境中,函数EndScene是在绘制3D场景后,用于完成将最终的图像渲染到屏幕的一系列操作的函数.它会将缓冲区中的图像清空,设置视口 ...
- centos离线安装chrony
环境 CentOS Linux release 7.9.2009 (Core) 工具 chrony-2.2.1.tar.gz 下载地址:https://download.tuxfamily.org/c ...